
v1.0
Showing
engine.py
0 → 100644
eval.sh
0 → 100644
export_coreml.py
0 → 100644
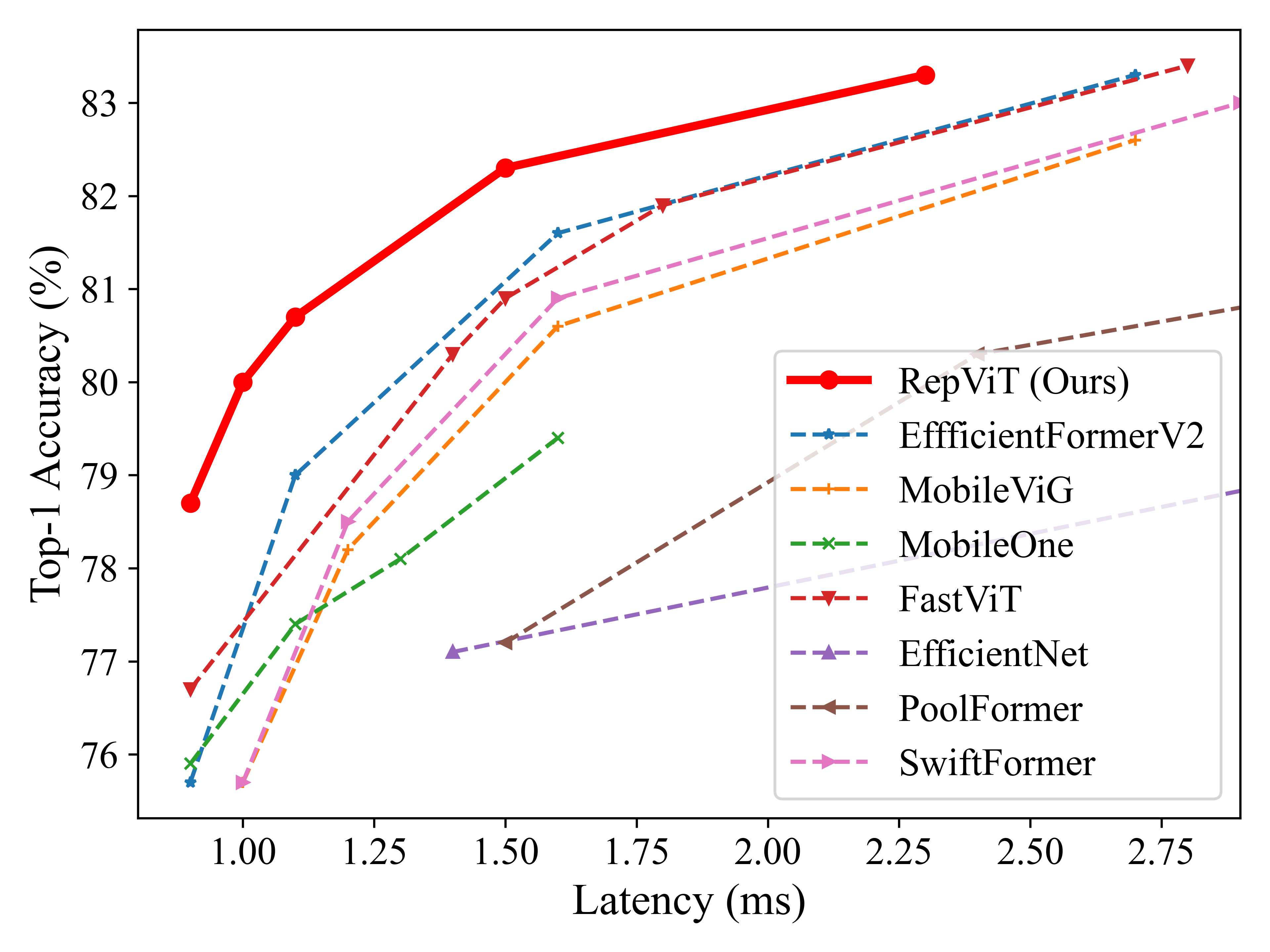
figures/latency.png
0 → 100644
{kind=link}
615 KB
{kind=link}
118 KB
flops.py
0 → 100644
losses.py
0 → 100644
main.py
0 → 100644
model.properties
0 → 100644
model/__init__.py
0 → 100644
model/repvit.py
0 → 100644
requirements.txt
0 → 100644
sam/.gitignore
0 → 100644
sam/CODE_OF_CONDUCT.md
0 → 100644
sam/CONTRIBUTING.md
0 → 100644
sam/LICENSE
0 → 100644
sam/README.md
0 → 100644
sam/app/.gitattributes
0 → 100644
sam/app/app.py
0 → 100644
sam/app/assets/.DS_Store
0 → 100644
File added