# Qwen3-VL
## 论文
[Qwen3-VL Technical Report](https://arxiv.org/pdf/2511.21631)
## 模型简介
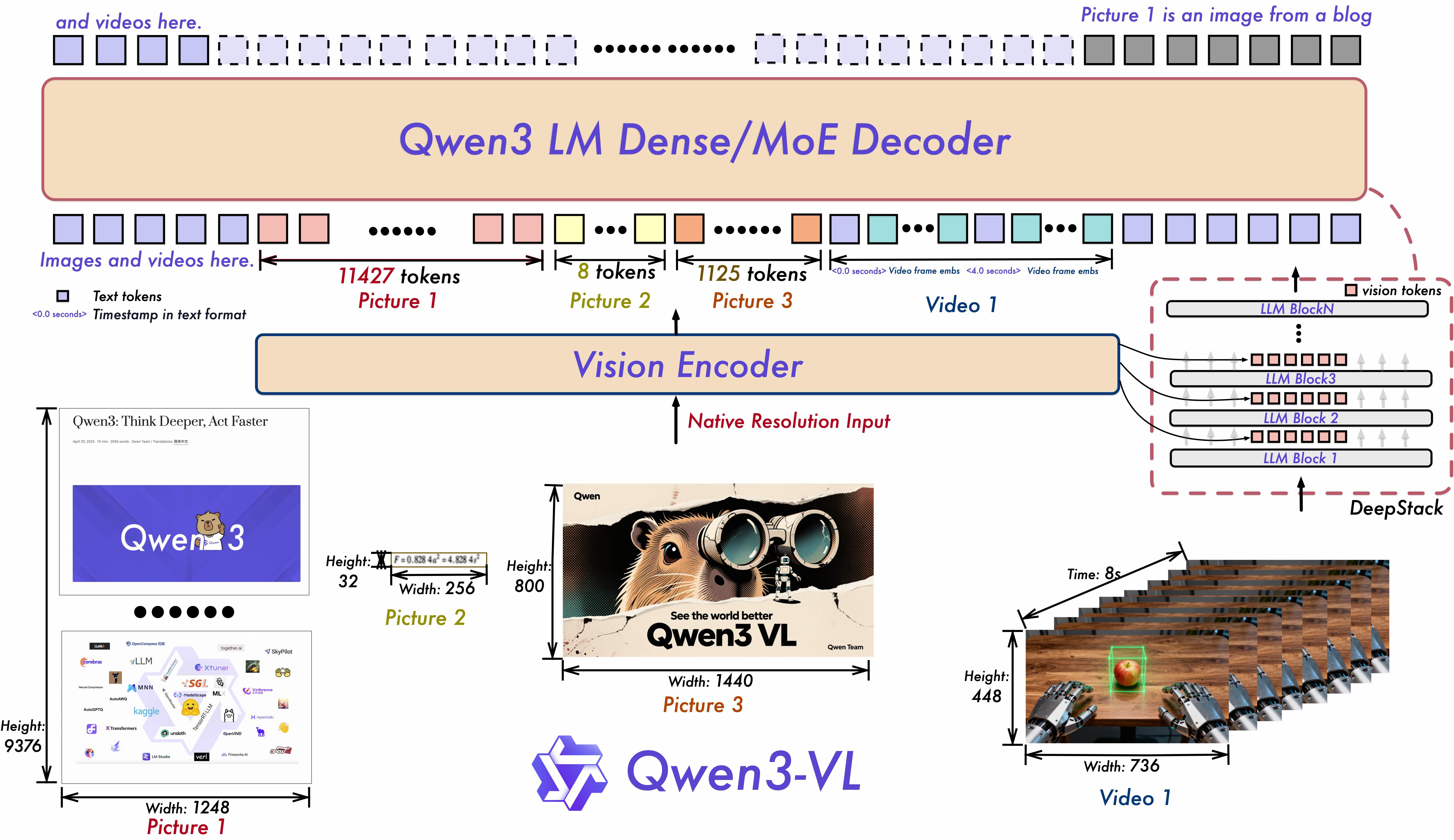
Qwen3-VL——迄今为止 Qwen 系列中最强大的视觉语言模型。
这一代产品在各方面都进行了全面升级:更出色的文本理解和生成能力、更深入的视觉感知和推理能力、更长的上下文长度、更强大的空间和视频动态理解能力以及更强大的代理交互能力。
提供从边缘到云端可扩展的密集型和 MoE 架构,以及可灵活按需部署的指导型和推理增强型思维型版本。
主要改进:
- 视觉代理:操作 PC/移动 GUI——识别元素、理解功能、调用工具、完成任务。
Visual Coding Boost:从图像/视频生成 Draw.io/HTML/CSS/JS。
- 高级空间感知:判断物体位置、视角和遮挡;提供更强的 2D 基础,并为空间推理和具身人工智能实现 3D 基础。
- 长上下文和视频理解:原生支持 256K 上下文,可扩展至 1M;能够处理书籍和数小时的视频,并具有完全回忆和二级索引功能。
- 增强型多模态推理能力:在 STEM/数学领域表现出色——因果分析和基于逻辑、证据的答案。
- 升级的视觉识别:更广泛、更高质量的预训练能够“识别一切”——名人、动漫、产品、地标、动植物等。
- 扩展的 OCR:支持 32 种语言(从 10 种增加到 32 种);在弱光、模糊和倾斜条件下表现更佳;对罕见/古代字符和术语的处理能力更强;改进了长文档结构解析。
- 文本理解能力与纯 LLM 相当:实现无损、统一的文本视觉无缝融合,从而获得统一的理解。
模型架构更新:
1. **Interleaved-MRoPE**: 通过稳健的位置嵌入,在时间、宽度和高度上进行全频分配,增强长时程视频推理。
2. **DeepStack**: 融合多级 ViT 特征,以捕捉精细细节并增强图像与文本的对齐。
3. **Text–Timestamp Alignment:** 超越 T-RoPE,实现基于时间戳的精确事件定位,从而增强视频时间建模能力。
## 环境依赖
| 软件 | 版本 |
|:------------:| :------: |
| DTK | 25.04.2 |
| python | 3.10.12 |
| transformers | 4.57.1 |
| torch | 2.5.1+das.opt1.dtk25042 |
| accelerate | 1.11.0 |
| torchvision | 0.20.1+das.opt1.dtk25042 |
| flash_attn | 2.6.1+das.opt1.dtk2504|
| av | 16.0.1|
推荐使用镜像:
- 挂载地址`-v`,`{docker_name}`和 `{docker_image_name}`根据实际模型情况修改
```bash
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_path/:/path/your_code_path/ -v /opt/hyhal/:/opt/hyhal/:ro {docker_image_name} bash
示例如下:
docker run -it --shm-size 200g --network=host --name qwen3vl --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_path/:/path/your_code_path/ -v /opt/hyhal/:/opt/hyhal/:ro image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.2-py3.10 bash
#视频推理时安装PyAV后端依赖
pip install av
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装,其它包参照requirements.txt安装:
```
pip install -r requirements.txt
```
## 数据集
`暂无`
## 训练
`暂无`
## 推理
### transformers
#### 单机推理
```bash
#普通图文对话
HIP_VISIBLE_DEVICES=0 python qwen3vl_infer.py
#多图像推理
HIP_VISIBLE_DEVICES=0 python qwen3vl_infer_multi_images.py
#视频推理
HIP_VISIBLE_DEVICES=0 python qwen3vl_infer_video.py
```
## 效果展示
**场景1** :普通图文对话
Input:
- image:
- text: "Describe this image."
Output:
**场景2** :多图像推理
Input:
- image1:
- image2:
- text: "Identify the similarities between these images."
Output:
**场景3** :视频推理
- Vedio:

- text:: "Describe this video."
Output:
### 精度
`DCU与GPU精度一致,推理框架:transformers。`
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 |下载地址|
|:--------------------:|:----:|:----------:|:------:|:----------:|
| Qwen3-VL-4B-Instruct | 4B | BW1000| 1 | [Hugging Face](https://huggingface.co/Qwen/Qwen3-VL-4B-Instruct) |
| Qwen3-VL-8B-Instruct | 8B | BW1000| 1 | [Hugging Face](https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct) |
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/qwen3-vl_pytorch
## 参考资料
- https://github.com/QwenLM/Qwen3-VL