# Qwen3-Omni
## 论文
[Qwen3-Omni](https://github.com/QwenLM/Qwen3-Omni/blob/main/assets/Qwen3_Omni.pdf)
## 模型简介
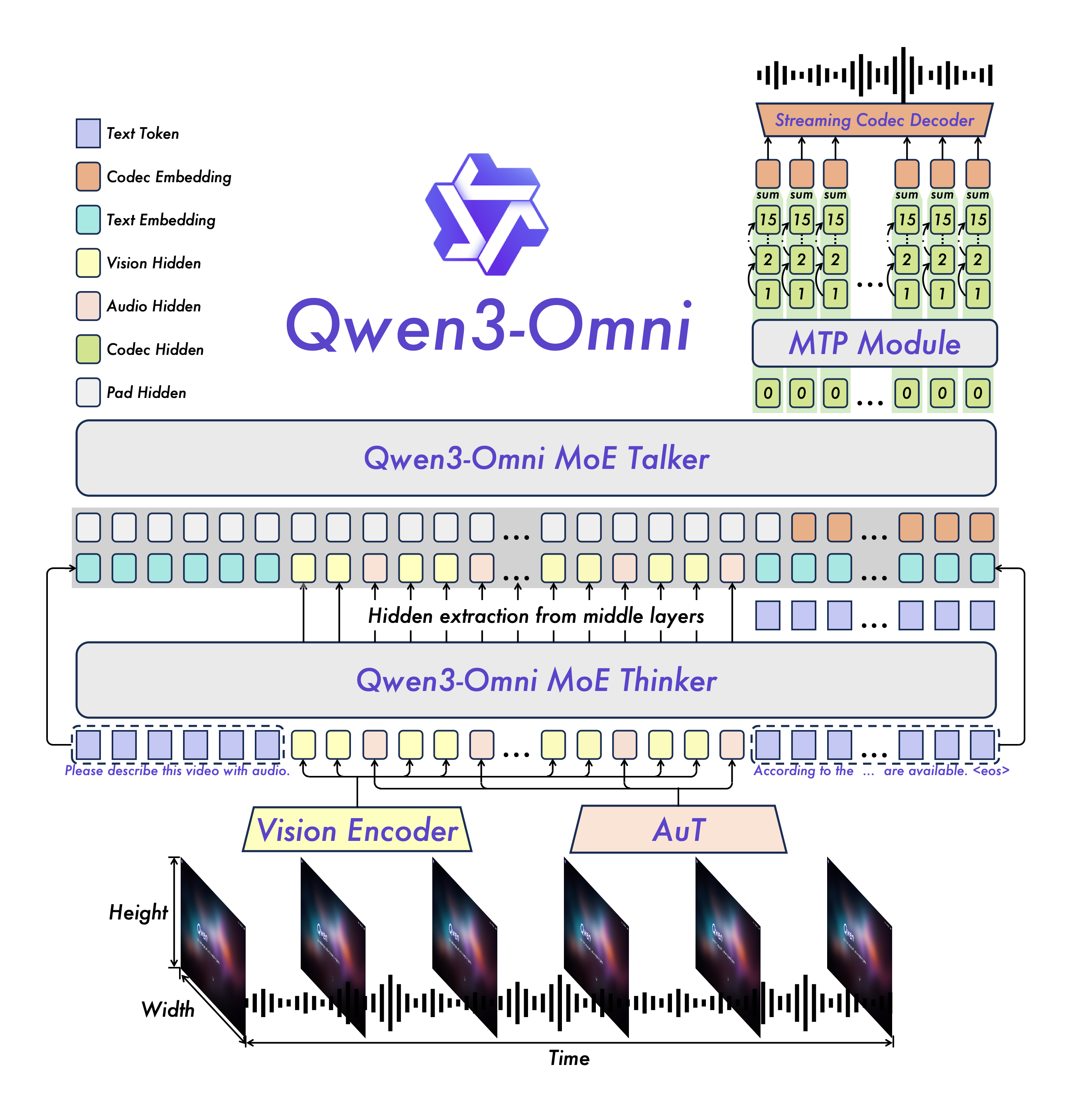
Qwen3-Omni 是一款原生的端到端全模态基座模型,具备对文本、图像、音频及视频的统一理解与生成能力。 该模型在多项音视频基准测试中展现出卓越的业界领先(SOTA)性能,其语音识别、音频理解及交互对话能力已可媲美 Gemini 2.5 Pro;同时,得益于早期的“文本优先”预训练策略,它在强化多模态支持的同时,完全保留了顶级的纯文本与图像处理水平,并支持多达 119 种文本语言及 19 种语音输入的跨语言交互。
在架构创新上,Qwen3-Omni 采用了基于 MoE(混合专家模型)的 “Thinker–Talker” 设计,结合 AuT 预训练与多码本技术,显著降低了推理延迟。 这种先进的设计使其能够支持极低延迟的流式音视频实时交互,实现自然的对话轮替与即时反馈。此外,模型提供了灵活的系统提示词控制机制,并同步开源了高精度的 30B 级别音频描述器(Captioner),为开源社区在全模态实时感知与复杂任务处理领域提供了强有力的支持。
## 环境依赖
| 软件 | 版本 |
| :------: |:-----------------------------------------:|
| DTK | 26.04 |
| python | 3.10.12 |
| transformers | 4.57.6 |
| vllm | 0.15.1+das.opt1.alpha.dtk2604 |
| vllm-omni | 0.14.0 |
| torch | 2.9.0+das.opt1.dtk2604.20260206.g275d08c2 |
推荐使用镜像: harbor.sourcefind.cn:5443/dcu/admin/base/custom:vllm0.15.1-ubuntu22.04-dtk26.04-0130-py3.10-20260220
- 挂载地址`-v` 根据实际模型情况修改
```bash
docker run -it \
--shm-size 200g \
--network=host \
--name Qwen3_Omni \
--privileged \
--device=/dev/kfd \
--device=/dev/dri \
--device=/dev/mkfd \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
-u root \
-v /opt/hyhal/:/opt/hyhal/:ro \
-v /path/your_code_data/:/path/your_code_data/ \
harbor.sourcefind.cn:5443/dcu/admin/base/custom:vllm0.15.1-ubuntu22.04-dtk26.04-0130-py3.10-20260220 bash
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装,vllm 等库需要替换安装:
```
pip uninstall vllm
pip install vllm-0.15.1+das.opt1.alpha.dtk2604-cp310-cp310-linux_x86_64.whl
pip install -r requirements.txt
```
> audio功能需要安装vllm-omni库,安装方法如下:
```
git clone http://developer.sourcefind.cn/codes/OpenDAS/vllm-omni.git
cd /your_code_path/vllm-omni
pip install -e . --no-build-isolation
```
## 数据集
暂无
## 训练
暂无
## 推理
### vllm
#### 单机推理
```bash
## serve启动
vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct \
--trust-remote-code \
--tensor-parallel-size 2 \
--dtype bfloat16 \
--max-model-len 65536 \
--gpu-memory-utilization 0.95 \
--allowed-local-media-path / \
--port 8001 \
--served-model-name qwen3-omni
## client访问
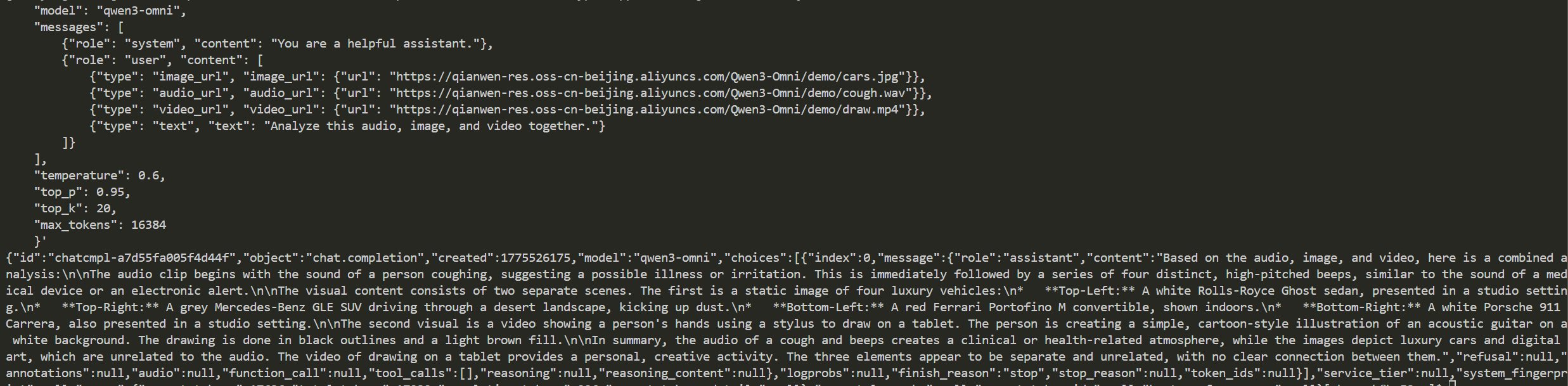
curl http://localhost:8001/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-omni",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cars.jpg"}},
{"type": "audio_url", "audio_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"}},
{"type": "video_url", "video_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/draw.mp4"}},
{"type": "text", "text": "Analyze this audio, image, and video together."}
]}
],
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"max_tokens": 16384
}'
```
## 效果展示
- Qwen3-Omni-30B-A3B-Instruct
- Qwen3-Omni-30B-A3B-Thinking
### 精度
DCU与GPU精度一致,推理框架:vllm。
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 | 下载地址 |
|:------:|:----:|:----------:|:------:|:---------------------:|
| Qwen3-Omni-30B-A3B-Instruct | 30B | BW1000 | 2 | [Hugging Face](https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct) |
| Qwen3-Omni-30B-A3B-Thinking | 30B | BW1000 | 2 | [Hugging Face](https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Thinking) |
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/qwen3-omni_vllm
## 参考资料
- https://github.com/QwenLM/Qwen3-Omni