# Qwen3-Next-80B-A3B
## 论文
暂无
## 模型简介
Qwen3-Next-80B-A3B 是 Qwen3-Next 系列的第一个版本,具有以下关键改进:
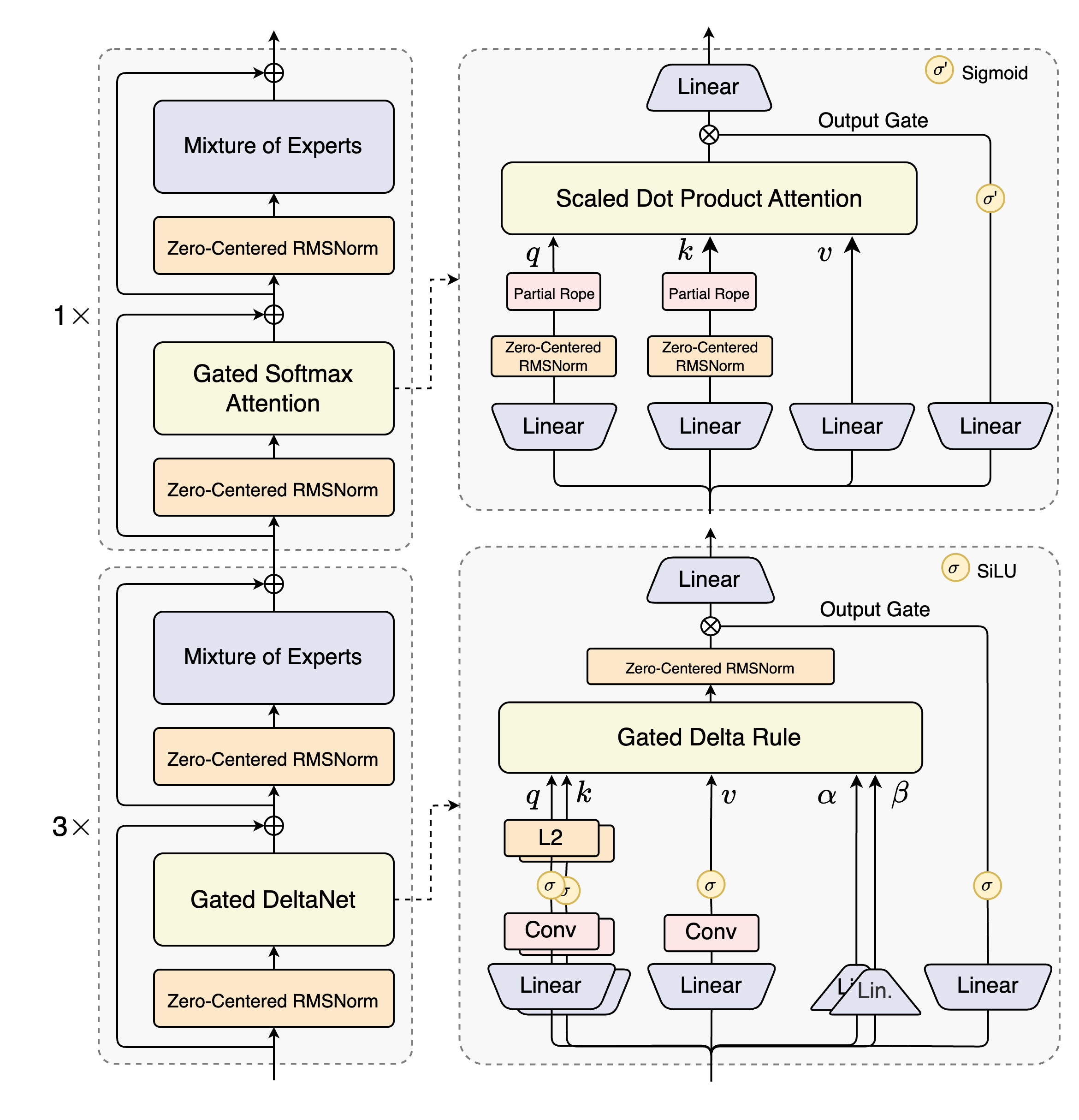
混合注意力:用 Gated DeltaNet 和 Gated Attention 的组合替代标准注意力机制,实现超长上下文的有效建模。
高稀疏度混合专家系统(MoE):在 MoE 层中实现极低的激活比率,大幅减少每个 token 的 FLOPs,同时保持模型容量。
稳定性优化:包括 零中心化和权重衰减的层归一化 以及其他稳定增强技术,以确保预训练和后训练的稳健性。
多 token 预测(MTP):提升预训练模型性能并加速推理。
## 环境依赖
| 软件 | 版本 |
| :----------: | :--------------------------------------------: |
| DTK | 26.04.2 |
| python | 3.10.12 |
| transformers | 4.57.6 |
| torch | 2.5.1+das.opt1.dtk2604.20260116.g78471bfd |
| accelerate | 1.12.0 |
| torchvision | 0.20.1+das.opt1.dtk2604.20260116.g65c66897 |
| flash_attn | 2.6.1+das.opt1.dtk2604.20260131.g4edd8bf9 |
| vllm | 0.11.0+das.opt1.rc2.dtk2604.20260128.g0bf89b0c |
推荐使用镜像:harbor.sourcefind.cn:5443/dcu/admin/base/vllm:0.11.0-ubuntu22.04-dtk26.04-0130-py3.10-20260202
- 挂载地址`-v`根据实际模型情况修改
```bash
docker run -it \
--shm-size 60g \
--network=host \
--name qwen3-next \
--privileged \
--device=/dev/kfd \
--device=/dev/dri \
--device=/dev/mkfd \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
-u root \
-v /opt/hyhal/:/opt/hyhal/:ro \
-v /path/your_code_data/:/path/your_code_data/ \
harbor.sourcefind.cn:5443/dcu/admin/base/vllm:0.11.0-ubuntu22.04-dtk26.04-0130-py3.10-20260202 bash
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
## 预训练权重
**请根据`支持的DCU型号`选择对应模型下载,FP8模型仅在BW1100/BW1101上支持,其他型号请勿使用!**
| **模型名称** | **权重大小** | **数据类型** | **支持的DCU型号** | **最低卡数需求** | **下载地址** |
| :------------------: | :----------: | :----------: | :---------------: | :--------------: | :----------------------------------------------------------: |
| Qwen3-Next-80B-A3B-Instruct | 80B | BF16 | BW1000,K100AI | 4 | [ModelScope](https://www.modelscope.cn/models/Qwen/Qwen3-Next-80B-A3B-Instruct) |
| Qwen3-Next-80B-A3B-Thinking | 80B | BF16 | BW1000,K100AI | 4 | [ModelScope](https://www.modelscope.cn/models/Qwen/Qwen3-Next-80B-A3B-Thinking) |
## 数据集
`暂无`
## 训练
`暂无`
## 推理
### vllm
#### 单机推理
注意:使用K100 AI 启动服务时需要添加--disable-custom-all-reduce参数
```bash
# serve启动
export HF_HUB_OFFLINE=1
export TRANSFORMERS_OFFLINE=1
vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking \
--served-model-name "Qwen3-Next-80B-A3B-Thinking" \
--dtype bfloat16 \
--trust-remote-code \
--tensor-parallel-size 4 \
--gpu-memory-utilization 0.95 \
--max-model-len 8192 \
--port 8000
# client访问
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model":"Qwen3-Next-80B-A3B-Thinking",
"messages":[{"role":"user","content":"简短介绍一下Qwen3-Next-80B-A3B模型"}],
"temperature":0.3
}'
```
## 效果展示
### 精度
`DCU与GPU精度一致,推理框架:vllm。`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/qwen3-next-80b-a3b_vllm
## 参考资料
- https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list