# Qwen3-30B-A3B_vllm
## 论文
`Qwen3 Technical Report`
- https://arxiv.org/abs/2505.09388
`Qwen2.5-1M Technical Report`
- https://arxiv.org/abs/2501.15383
## 模型结构
Qwen3-30B-A3B 是 Qwen 系列中的最新一代大型语言模型,它提供了涵盖密集型和专家混合型(MoE)模型的一整套工具。基于大量的训练数据,Qwen3 在推理、指令遵循、智能体功能以及多语言支持等方面实现了突破性的进步。其主要特点如下:
- 支持在单个模型内无缝切换思考模式(用于复杂逻辑推理、数学和编码)和非思考模式(用于高效通用对话),确保在各种场景下实现最佳性能。
- 显著提升推理能力,在数学、代码生成和常识逻辑推理方面超越之前的 QwQ(思考模式)和 Qwen2.5 指令模型(非思考模式)。
- 在创意写作、角色扮演、多轮对话和指令遵循方面表现出色,与人类偏好高度一致,提供更自然、更吸引人、更沉浸式的对话体验。
- 具备代理能力专长,在思考和非思考模式下都能精准集成外部工具,在复杂代理任务中处于开源模型的领先地位。
- 支持 100 多种语言和方言,具备强大的多语言指令遵循和翻译能力。
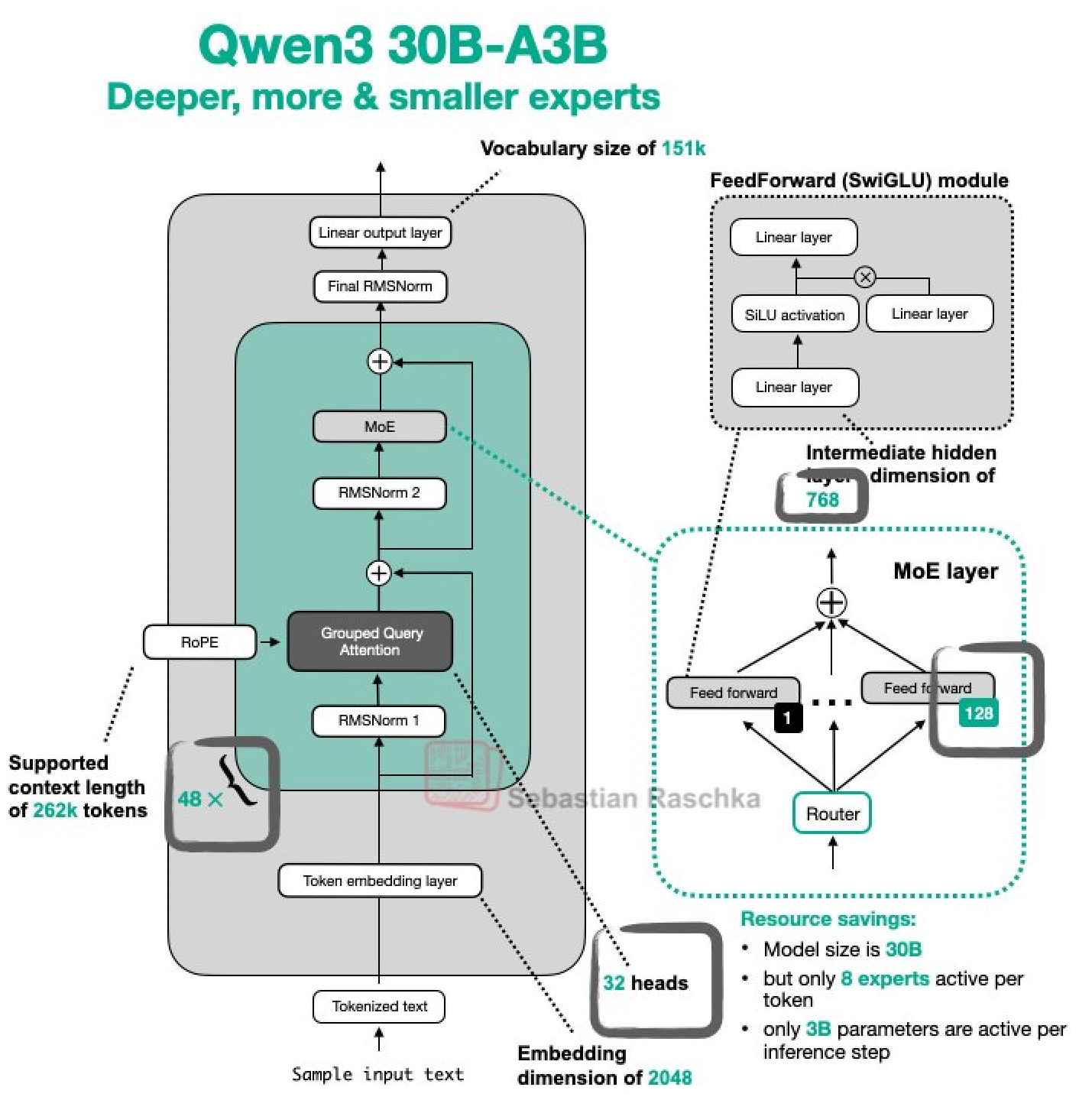
## 算法原理
Qwen3-30B-A3B、Qwen3-30B-A3B-Instruct-2507以及Qwen3-30B-A3B-Thinking-2507在一般能力方面有显著提高,包括遵循指令、逻辑推理、文本理解、数学、科学、编码和工具使用。跨多种语言的长尾知识覆盖的实质性增长。在主观和开放式任务中与用户偏好明显更好的对齐,从而实现更有帮助的响应和更高质量的文本生成。增强了256K长上下文理解能力。
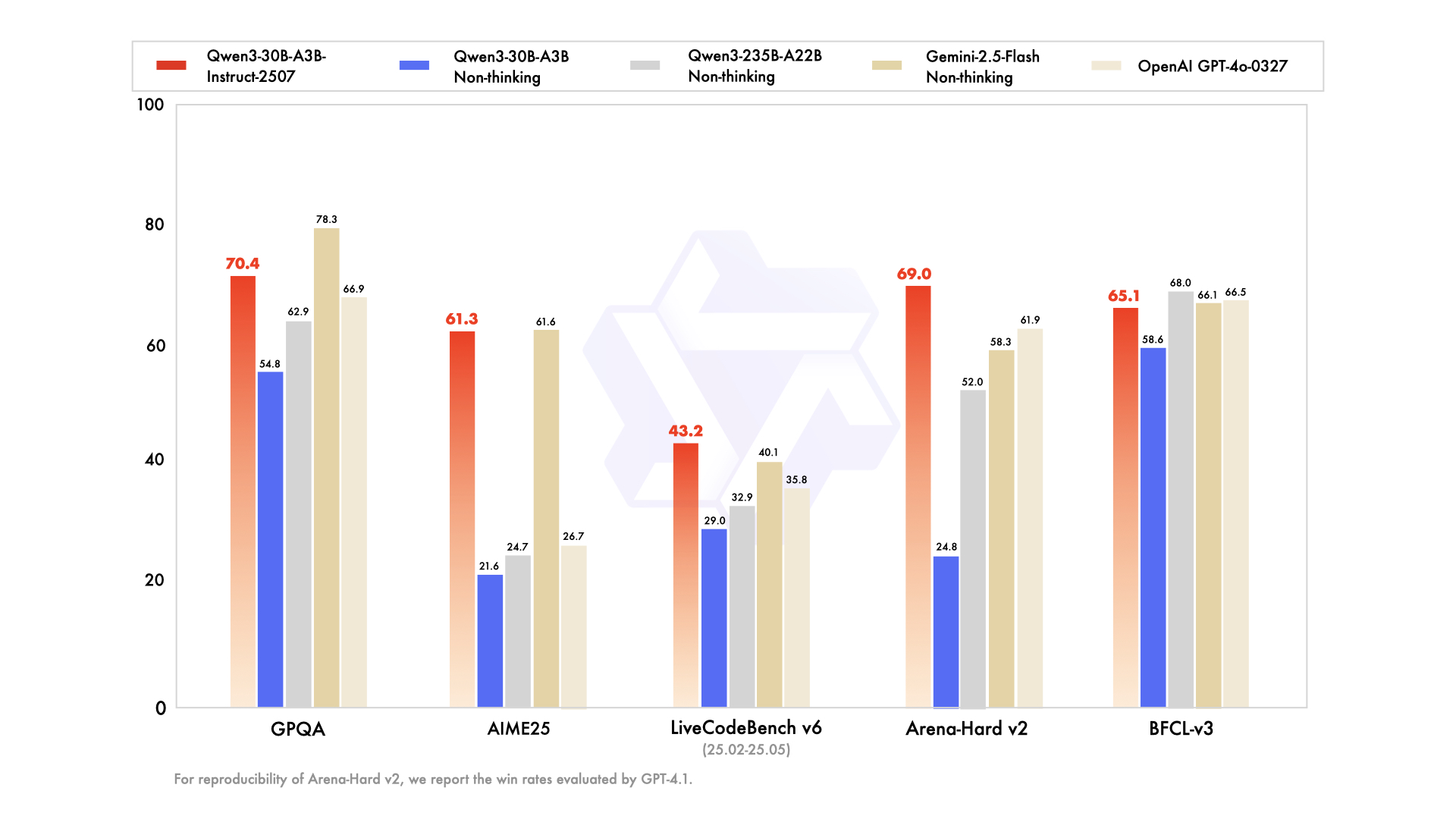
## 环境配置
### 硬件需求
DCU型号:K100_AI,节点数量:1台,卡数:2张。
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/vllm:0.8.5-ubuntu22.04-dtk25.04.1-rc5-das1.6-py3.10-20250724
docker run -it --name {docker_name} --device=/dev/kfd --privileged --network=host --device=/dev/dri --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /public/LLM-Models:/home/LLM-Models:ro -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --group-add video --shm-size 64G {imageID} bash
cd /your_code_path/qwen3-30b-a3b_vllm
```
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```bash
cd docker
docker build --no-cache -t qwen3-30b-a3b:latest .
docker run -it --name {docker_name} --device=/dev/kfd --privileged --network=host --device=/dev/dri --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /public/LLM-Models:/home/LLM-Models:ro -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --group-add video --shm-size 64G {imageID} bash
cd /your_code_path/qwen3-30b-a3b_vllm
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```bash
DTK: 25.04
python: 3.10
vllm: 0.8.5.post1
torch: 2.4.1+das.opt1.dtk25041
```
`Tips:以上dtk驱动、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库安装方式如下:
```bash
pip install transformers==4.51.1
```
## 数据集
暂无
## 训练
暂无
## 推理
vllm离线推理Qwen3-30B-A3B:
```bash
## Qwen3-30B-A3B 在 BF16 精度下,其模型权重本身大约是 61 GB,至少需要双卡部署推理
export HIP_VISIBLE_DEVICES=6,7
## 模型地址参数
python ./infer/offline/infer_vllm.py --model /your_path/Qwen3-30B-A3B --tensor-parallel-size 2
```
## result
### result一
vllm离线推理Qwen3-30B-A3B:
```bash
## Qwen3-30B-A3B 在 BF16 精度下,其模型权重本身大约是 61 GB,至少需要双卡部署推理
export HIP_VISIBLE_DEVICES=6,7
## 模型地址参数
python ./infer/offline/infer_vllm.py --model /your_path/Qwen3-30B-A3B --tensor-parallel-size 2
```
```
Original Input Prompt (if available):
'介绍一下北京.'
Generated text (full output):
'\n好的,用户让我介绍一下北京。首先,我需要确定用户的需求是什么......'
================================================================================
Logprobs per generated token:
Step 0:
- Generated Token: 151667 ('')
- Top Logprobs:
- Rank 1: Token 151667 ('') -> Logprob: -0.0000
- Rank 2: Token 32501 ('yped') -> Logprob: -16.6875
- Rank 3: Token 81218 (' zlib') -> Logprob: -17.5000
- Rank 4: Token 77899 (':len') -> Logprob: -17.9375
- Rank 5: Token 99048 (' zf') -> Logprob: -18.4375
- Rank 6: Token 117865 ('具体内容') -> Logprob: -18.5000
- Rank 7: Token 198 (' ') -> Logprob: -18.5625
- Rank 8: Token 18945 ('α') -> Logprob: -18.5625
- Rank 9: Token 67085 ('[param') -> Logprob: -19.0000
- Rank 10: Token 75025 ('yms') -> Logprob: -19.0000
...
...
成功将每个生成token的logprob写入到文件: ...
```
### 精度测试一
```
# 分别在DCU和GPU上运行infer_vllm.py,得到各自的精度数据,并将精度数据复制粘贴到acc.py中运行
python ./infer/offline/acc.py
```
结果
```
Qwen3-30B-A3B在DCU(K100_AI)与GPU(A800)离线推理的平均绝对误差值:0.002905419914469576
```
DCU(K100_AI)与GPU(A800)离线推理Qwen3-30B-A3B精度一致,推理框架:vllm
### result二
vllm离线推理Qwen3-30B-A3B-Instruct-2507:
```bash
## Qwen3-30B-A3B-Instruct-2507 至少需要双卡部署推理
export HIP_VISIBLE_DEVICES=6,7
## 模型地址参数
python ./infer/offline/infer_vllm.py --model /your_path/Qwen3-30B-A3B-Instruct-2507 --tensor-parallel-size 2
```
```
Original Input Prompt (if available):
'介绍一下北京.'
Generated text (full output):
'北京,简称“京”,是中国的首都,也是中华人民共和国的中央人民政府所在地......'
================================================================================
Logprobs per generated token:
Step 0:
- Generated Token: 68990 ('北京')
- Top Logprobs:
- Rank 1: Token 68990 ('北京') -> Logprob: -0.0019
- Rank 2: Token 103942 ('当然') -> Logprob: -6.2519
- Rank 3: Token 104554 ('北京市') -> Logprob: -11.3769
- Rank 4: Token 99692 ('好的') -> Logprob: -13.5019
- Rank 5: Token 108386 ('你好') -> Logprob: -13.5019
- Rank 6: Token 111308 ('您好') -> Logprob: -14.1269
- Rank 7: Token 106287 ('嗯') -> Logprob: -15.2519
- Rank 8: Token 106114 ('首都') -> Logprob: -16.8769
- Rank 9: Token 110488 ('北京时间') -> Logprob: -16.8769
- Rank 10: Token 334 ('**') -> Logprob: -17.3769
...
...
成功将每个生成token的logprob写入到文件: ...
```
### 精度测试二
```
# 分别在DCU和GPU上运行infer_vllm.py,得到各自的精度数据,并将精度数据复制粘贴到acc.py中运行
python ./infer/offline/acc.py
```
结果
```
Qwen3-30B-A3B-Instruct-2507在DCU(K100_AI)与GPU(A800)离线推理的平均绝对误差值:0.006542379854522551
```
DCU(K100_AI)与GPU(A800)离线推理Qwen3-30B-A3B-Instruct-2507精度一致,推理框架:vllm
### result三
vllm离线推理Qwen3-30B-A3B-Thinking-2507:
```bash
## Qwen3-30B-A3B-Thinking-2507 至少需要双卡部署推理
export HIP_VISIBLE_DEVICES=6,7
## 模型地址参数
python ./infer/offline/infer_vllm.py --model /your_path/Qwen3-30B-A3B-Thinking-2507 --tensor-parallel-size 2
```
```
Original Input Prompt (if available):
'介绍一下北京.'
Generated text (full output):
'嗯,用户让我介绍一下北京。首先得确定用户的需求是什么......'
================================================================================
Logprobs per generated token:
Step 0:
- Generated Token: 106287 ('嗯')
- Top Logprobs:
- Rank 1: Token 106287 ('嗯') -> Logprob: -0.0134
- Rank 2: Token 32313 ('Okay') -> Logprob: -4.3884
- Rank 3: Token 99692 ('好的') -> Logprob: -7.0134
- Rank 4: Token 80022 ('Hmm') -> Logprob: -11.3884
- Rank 5: Token 110115 ('好吧') -> Logprob: -11.6384
- Rank 6: Token 11395 ('Well') -> Logprob: -13.0134
- Rank 7: Token 52801 ('好') -> Logprob: -13.0134
- Rank 8: Token 101140 ('首先') -> Logprob: -13.3884
- Rank 9: Token 71486 ('Alright') -> Logprob: -13.5134
- Rank 10: Token 2461 ('For') -> Logprob: -14.0134
...
...
成功将每个生成token的logprob写入到文件: ...
```
### 精度测试三
```
# 分别在DCU和GPU上运行infer_vllm.py,得到各自的精度数据,并将精度数据复制粘贴到acc.py中运行
python ./infer/offline/acc.py
```
结果
```
Qwen3-30B-A3B-Thinking-2507在DCU(K100_AI)与GPU(A800)离线推理的平均绝对误差值:0.01841533068222816
```
DCU(K100_AI)与GPU(A800)离线推理Qwen3-30B-A3B-Thinking-2507精度一致,推理框架:vllm
### result四
vllm在线推理Qwen3-30B-A3B:
```bash
## Qwen3-30B-A3B 至少需要双卡部署
export HIP_VISIBLE_DEVICES=6,7
## 启动服务
vllm serve /your_path/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1 --tensor-parallel-size 2 --max-logprobs 10
## 修改./infer/online/client.py, MODEL_NAME请改成/your_path/Qwen3-30B-A3B,并运行client.py, 代码内部共设置十个提示词
python client.py
```
```
欢迎使用 Qwen3-30B-A3B 聊天客户端!
已连接到 vLLM 服务,使用模型: /home/zwq/model/Qwen3-30B-A3B
--------------------------------------------------
--- 问题 1: '介绍一下北京.' ---
完整回答 (包含思考): '\n\n北京是中国的首都,也是世界著名古都和国际化大都市......'
答案部分前10个Token的Rank 1 Logprobs:
Step 0: 0.0000
Step 1: -0.0000
Step 2: -0.0711
Step 3: -0.0000
Step 4: -0.1086
Step 5: -0.0150
Step 6: -0.0067
Step 7: -0.0000
Step 8: -0.0298
Step 9: -0.0091
--------------------------------------------------
......
......
所有测试结果已保存到文件: ./Qwen3-30B-A3B_logprobs_K100AI_fp16.json
```
### 精度测试四
```bash
## 分别在DCU和GPU上启动vllm服务,并对应运行client.py,得到各自的精度数据后,运行online文件夹下的acc.py
python ./infer/online/acc.py --file1 /your_path/Qwen3-30B-A3B_logprobs_A800_fp16.json --file2 /your_path/Qwen3-30B-A3B_logprobs_K100AI_fp16.json
```
结果
```
提示词:介绍一下北京.,平均绝对误差:0.002455742455325094
提示词:写一首关于春天的五言绝句.,平均绝对误差:0.0007630783482369452
提示词:请解释一下黑洞的形成原理.,平均绝对误差:0.005167613880542632
提示词:推荐三部值得一看的科幻电影,并简述理由.,平均绝对误差:0.0030238355811320616
提示词:如何有效提高编程能力?,平均绝对误差:0.014263489465471934
提示词:给我讲一个关于人工智能的笑话.,平均绝对误差:0.003418742059113811
提示词:你认为未来教育会发展成什么样?,平均绝对误差:0.0246062334959511
提示词:如何制作一道美味的麻婆豆腐?,平均绝对误差:0.005538759729023468
提示词:量子计算的原理是什么?它有哪些潜在应用?,平均绝对误差:0.012481686085721578
提示词:请用英语介绍一下中国长城.,平均绝对误差:0.001114922351905534
总体平均绝对误差:7.283410e-03
```
DCU(K100_AI)与GPU(A800)在线推理Qwen3-30B-A3B精度一致,推理框架:vllm
### result五
vllm在线推理Qwen3-30B-A3B-Instruct-2507:
```bash
## Qwen3-30B-A3B-Instruct-2507 至少需要双卡部署
export HIP_VISIBLE_DEVICES=6,7
## 启动服务
vllm serve /your_path/Qwen3-30B-A3B-Instruct-2507 --tensor-parallel-size 2 --max-logprobs 10
## 修改./infer/online/client.py, MODEL_NAME请改成/your_path/Qwen3-30B-A3B-Instruct-2507,并运行client.py, 代码内部共设置十个提示词
python client.py
```
```
欢迎使用 Qwen3-30B-A3B 聊天客户端!
已连接到 vLLM 服务,使用模型: /home/zwq/model/Qwen3-30B-A3B-Instruct-2507
--------------------------------------------------
--- 问题 1: '介绍一下北京.' ---
完整回答 (包含思考): '北京,简称“京”,是中国的首都,也是中华人民共和国的中央人民政府所在地......'
答案部分前10个Token的Rank 1 Logprobs:
Step 0: -0.0025
Step 1: -0.2529
Step 2: -0.1372
Step 3: -0.0000
Step 4: 0.0000
Step 5: -0.0000
Step 6: -0.0381
Step 7: -0.0007
Step 8: -0.0001
Step 9: -0.0000
--------------------------------------------------
......
......
所有测试结果已保存到文件: ./Qwen3-30B-A3B-Instruct-2507_logprobs_K100AI_fp16.json
```
### 精度测试五
```bash
## 分别在DCU和GPU上启动vllm服务,并对应运行client.py,得到各自的精度数据后,运行online文件夹下的acc.py
python ./infer/online/acc.py --file1 /your_path/Qwen3-30B-A3B-Instruct-2507_logprobs_A800_fp16.json --file2 /your_path/Qwen3-30B-A3B-Instruct-2507_logprobs_K100AI_fp16.json
```
结果
```
提示词:介绍一下北京.,平均绝对误差:0.0003844495090561395
提示词:写一首关于春天的五言绝句.,平均绝对误差:0.003621068420738993
提示词:请解释一下黑洞的形成原理.,平均绝对误差:0.013209401426135515
提示词:推荐三部值得一看的科幻电影,并简述理由.,平均绝对误差:0.028403437747607542
提示词:如何有效提高编程能力?,平均绝对误差:0.014048111713964317
提示词:给我讲一个关于人工智能的笑话.,平均绝对误差:0.027143383317161353
提示词:你认为未来教育会发展成什么样?,平均绝对误差:0.019544235430657864
提示词:如何制作一道美味的麻婆豆腐?,平均绝对误差:0.007543907890431712
提示词:量子计算的原理是什么?它有哪些潜在应用?,平均绝对误差:0.009102995577677575
提示词:请用英语介绍一下中国长城.,平均绝对误差:8.911460490779177e-05
总体平均绝对误差:1.230901e-02
```
DCU(K100_AI)与GPU(A800)在线推理Qwen3-30B-A3B-Instruct-2507精度一致,推理框架:vllm
### result六
vllm在线推理Qwen3-30B-A3B-Thinking-2507:
```bash
## Qwen3-30B-A3B-Thinking-2507 至少需要双卡部署
export HIP_VISIBLE_DEVICES=6,7
## 启动服务
vllm serve /your_path/Qwen3-30B-A3B-Thinking-2507 --tensor-parallel-size 2 --max-logprobs 10
## 修改./infer/online/client.py, MODEL_NAME请改成/your_path/Qwen3-30B-A3B-Thinking-2507,并运行client.py, 代码内部共设置十个提示词
python client.py
```
```
欢迎使用 Qwen3-30B-A3B 聊天客户端!
已连接到 vLLM 服务,使用模型: /home/zwq/model/Qwen3-30B-A3B-Thinking-2507
--------------------------------------------------
--- 问题 1: '介绍一下北京.' ---
完整回答 (包含思考): '......'
答案部分前10个Token的Rank 1 Logprobs:
Step 0: -0.0025
Step 1: -0.2529
Step 2: -0.1372
Step 3: -0.0000
Step 4: 0.0000
Step 5: -0.0000
Step 6: -0.0381
Step 7: -0.0007
Step 8: -0.0001
Step 9: -0.0000
--------------------------------------------------
......
......
所有测试结果已保存到文件: ./Qwen3-30B-A3B-Thinking-2507_logprobs_K100AI_fp16.json
```
### 精度测试六
```bash
## 分别在DCU和GPU上启动vllm服务,并对应运行client.py,得到各自的精度数据后,运行online文件夹下的acc.py
python ./infer/online/acc.py --file1 /your_path/Qwen3-30B-A3B-Thinking-2507_logprobs_A800_fp16.json --file2 /your_path/Qwen3-30B-A3B-Thinking-2507_logprobs_K100AI_fp16.json
```
结果
```
提示词:介绍一下北京.,平均绝对误差:0.0268607304953548
提示词:写一首关于春天的五言绝句.,平均绝对误差:0.03196280233089581
提示词:请解释一下黑洞的形成原理.,平均绝对误差:0.018056550696832117
提示词:推荐三部值得一看的科幻电影,并简述理由.,平均绝对误差:7.236637604322028e-05
提示词:如何有效提高编程能力?,平均绝对误差:0.021264297872457406
提示词:给我讲一个关于人工智能的笑话.,平均绝对误差:0.00047728609542616594
提示词:你认为未来教育会发展成什么样?,平均绝对误差:0.013615525089016955
提示词:如何制作一道美味的麻婆豆腐?,平均绝对误差:0.01083195809155768
提示词:量子计算的原理是什么?它有哪些潜在应用?,平均绝对误差:0.0001254735009297292
提示词:请用英语介绍一下中国长城.,平均绝对误差:0.00332602070383885
总体平均绝对误差:1.265930e-02
```
DCU(K100_AI)与GPU(A800)在线推理Qwen3-30B-A3B-Thinking-2507精度一致,推理框架:vllm
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`金融,教育,政府,科研,制造,能源,交通`
## 预训练权重
- [Qwen/Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B)
- [Qwen/Qwen3-30B-A3B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507)
- [Qwen/Qwen3-30B-A3B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/qwen3-30b-a3b_vllm
## 参考资料
- https://huggingface.co/Qwen/Qwen3-30B-A3B
- https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507
- https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507