# Qwen2.5-Coder
## 论文
- https://arxiv.org/pdf/2409.12186
## 模型结构
Qwen2.5-Coder 基于 Qwen 系列的大模型(通义千问),针对代码领域任务进行了特殊优化。它可以在多种编程语言(如 Python、Java、C++ 等)中生成和解释代码
## 算法原理
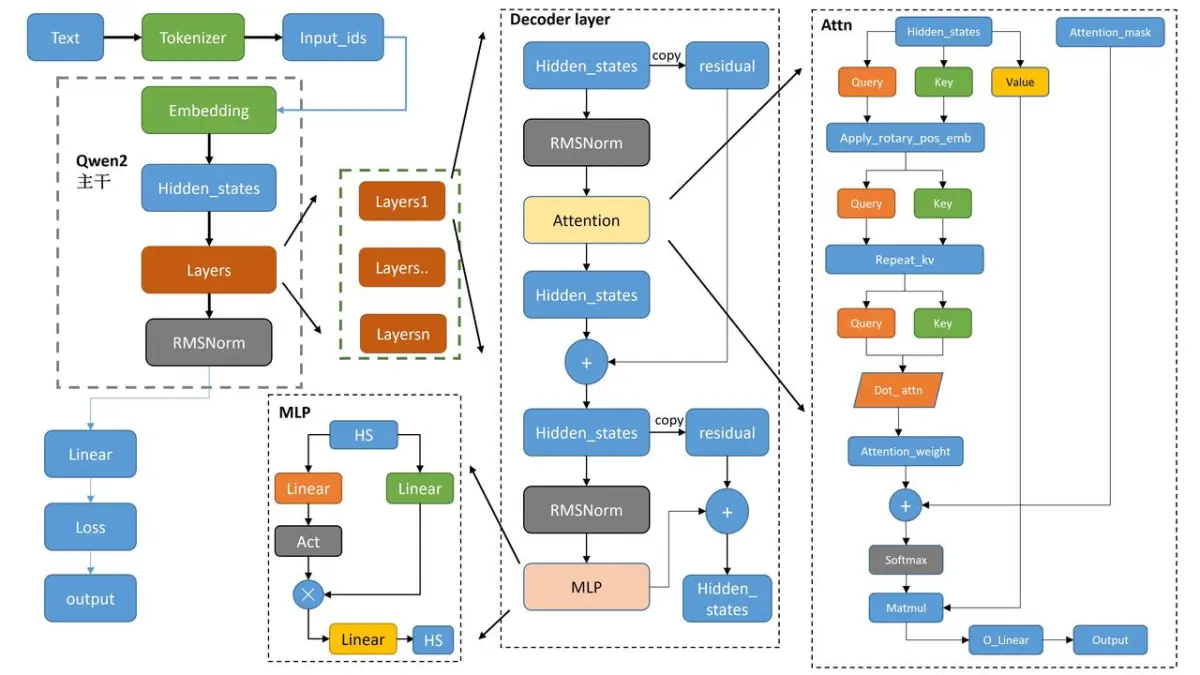
**Architecture**
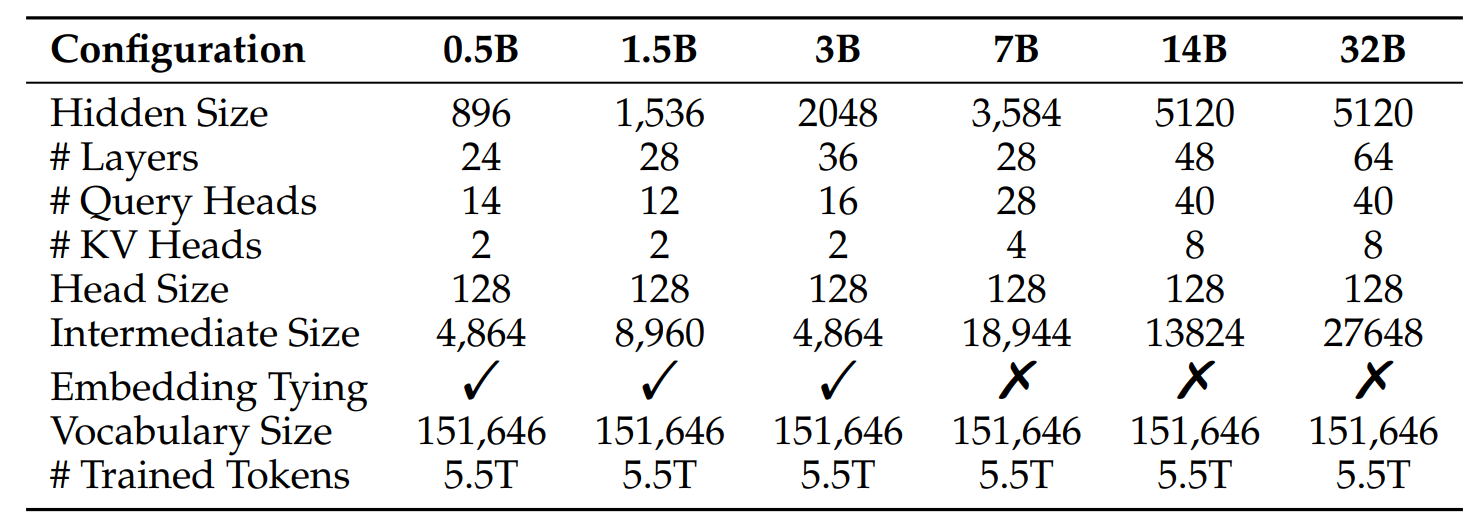
Qwen2.5-Coder以Qwen2.5为基础,有0.5B、1.5B、3B、7B、14B以及32B六个不同的模型尺寸,不同的尺寸的Head Size都为128,尺寸的变化主要体现在Hidden Size、Layers等结构尺寸的调整,具体的模型尺寸和结构如表所示:
**Tokenization**
在Qwen2.5词汇表的基础上,Qwen2.5-Coder增加了一些特殊的tokens帮助模型更好的理解代码的各种格式,比如说,<|endoftext|>标志一段text或者说段落的结束,<|fim_prefix|>,<|fim_middle|>, 和<|fim_suffix|> 用于实现Fill-in-the-Middle(FIM)技术,帮助模型预测代码缺失的block,<|fim_pad|>用于在FIM中对代码片段进行补全,<|repo_name|>和<|file_sep|>分别为Repo代码仓库名称和Repo之间的划分标志:
**Data**
使用了一个自建的数据集Qwen2.5-Coder-Data用于训练 Qwen2.5-Coder,包括5个部分:
- Source Code Data: 源代码数据集,从GitHub的2024年2月以前的公开Repo中进行收集,包括92种语言
- Text-Code Grounding Data: 文本代码混合数据集,主要是一些技术博客、代码相关文档、教程等
- Synthetic Data: 合成数据集,使用CodeQwen1.5生成
- Math Data:数学数据集,使用Qwen2.5-Math的数据集。提升模型的数学推理能力
- Text Data:文本数据集,使用Qwen2.5的数据集,提升模型的通用能力
对5种类型的数据进行混合来训练一个foundational model,Qwen2.5-Coder尝试了多种混合比例,最后选择的混合比例为:Code:Text:Math=7:2:1,共5.2T的Tokens:
**Training Policy**
使用了三阶段的训练方法,以Qwen2.5作为BaseLine,第一阶段进行文本级别的训练,也就是上述的混合数据集共5.2T的Tokens,第二阶段是进行仓库级别的训练,增强模型的长文本处理能力,共300B的Tokens,通过两个阶段的训练,得到了Qwen2.5-Coder-Base模型;
为了更适合进行交互,理解用户指令,在Qwen2.5-Coder-32B-Base模型的基础上,进行指令微调,得到了Instruct版本。为此,项目还构建了一个用于指令微调的合成数据集,具体做法是使用GitHub的代码片段通过LLM生成对应的指令,然后使用LLM Score进行过滤掉低质量样本,构建了合成的代码指令数据集;除了合成数据集,还使用了一些开源的指令数据集,比如McEval-Instruct。具体的训练流程如图:
## 环境配置
## 硬件需求
DCU型号:K100_AI,节点数量:1台,卡数:1张
### Docker(方法一)
从[光源](https://www.sourcefind.cn/#/service-list)中拉取docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.4.1-ubuntu22.04-dtk25.04.1-py3.10
```
创建容器并挂载目录进行开发:
```
docker run -it --name {name} --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v {}:{} {docker_image} /bin/bash
# 修改1 {name} 需要改为自定义名称
# 修改2 {docker_image} 需要需要创建容器的对应镜像名称
# 修改3 -v 挂载路径到容器指定路径
pip install -r requirements.txt
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
pip install deepspeed-0.14.2+das.opt1.dtk25041-cp310-cp310-manylinux_2_28_x86_64.whl
```
### Dockerfile(方法二)
```
cd docker
docker build --no-cache -t qwen2_5_coder:1.0 .
docker run -it --name {name} --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v {}:{} {docker_image} /bin/bash
pip install -r requirements.txt
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
pip install deepspeed-0.14.2+das.opt1.dtk25041-cp310-cp310-manylinux_2_28_x86_64.whl
```
### Anaconda(方法三)
线上节点推荐使用conda进行环境配置。
创建python=3.10的conda环境并激活
```
conda create -n qwen2_5_coder python=3.10
conda activate qwen2_5_coder
```
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk25.04.1
python:python3.10
pytorch:2.4.1
torchvision:0.19.1
deepspeed:0.14.2
```
安装其他依赖包
```
pip install -r requirements.txt
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
pip install deepspeed-0.14.2+das.opt1.dtk25041-cp310-cp310-manylinux_2_28_x86_64.whl
```
下载预训练权重文件并解压,这里以Qwen2.5-Coder-32B-Instruct为例,其他版本模型可以在**预训练权重**部分下载:
Qwen2.5-Coder-32B-Instruct预训练权重下载:[HuggingFace下载](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct)
SCNet快速下载连接[SCNet下载](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-32B-Instruct)
将文件夹Qwen/Qwen2.5-Coder-32B-Instruct保存至LLaMA-Factory中
## 数据集
无
## 训练
使用LLaMA-Factory框架微调
### 单机单卡(LoRA-finetune)
```
# 注意:根据自己的模型切换.yaml文件中的模型位置
HIP_VISIBLE_DEVICES=0 llamafactory-cli train examples/train_lora/qwen2vl_lora_sft_custom.yaml
# 如果显存不够,可以使用Zero-offload减少显存使用,单卡时要注释掉yaml中的deepspeed内容
HIP_VISIBLE_DEVICES=0 llamafactory-cli train examples/train_lora/qwen2vl_lora_sft_offload_custom.yaml
```
### 单机多卡(LoRA-finetune)
```
# 注意:根据自己的模型切换.yaml文件中的模型位置
HIP_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/train_lora/qwen2vl_lora_sft_offload_custom.yaml
```
## 推理
```
# 注意:根据自己的模型切换.yaml文件中的模型位置
HIP_VISIBLE_DEVICES=0 llamafactory-cli chat examples/inference/qwen2_coder_custom.yaml
```
## result
## 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
代码生成
### 热点应用行业
制造,电商,医疗,能源,教育
## 预训练权重
Instruct系列模型
[Qwen2.5-Coder-0.5B-Instruct](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-0.5B-Instruct)
[Qwen2.5-Coder-1.5B-Instruct](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-1.5B-Instruct)
[Qwen2.5-Coder-3B-Instruct](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-3B-Instruct)
[Qwen2.5-Coder-7B-Instruct](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-7B-Instruct)
[Qwen2.5-Coder-14B-Instruct](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-14B-Instruct)
Base系列模型
[Qwen2.5-Coder-0.5B](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-0.5B)
[Qwen2.5-Coder-1.5B](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-1.5B)
[Qwen2.5-Coder-3B](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-3B)
[Qwen2.5-Coder-7B](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-7B)
[Qwen2.5-Coder-14B](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-14B)
[Qwen2.5-Coder-32B](http://113.200.138.88:18080/aimodels/qwen/Qwen2.5-Coder-32B)
## 源码仓库及问题反馈
[https://developer.sourcefind.cn/codes/modelzoo/qwen2.5-coder_pytorch](https://developer.sourcefind.cn/codes/modelzoo/qwen2.5-coder_pytorch)
## 参考资料
[https://github.com/QwenLM/Qwen2.5-Coder](https://github.com/QwenLM/Qwen2.5-Coder)
[https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct)