# Qwen2-Audio
为一个大规模音频语言模型,Qwen2-Audio能够接受各种音频信号输入,并根据语音指令执行音频分析或直接响应文本。我们介绍两种不同的音频交互模式:语音聊天 voice chat 和音频分析 audio analysis。
* 语音聊天:用户可以自由地与 Qwen2-Audio 进行语音互动,而无需文本输入;
* 音频分析:用户可以在互动过程中提供音频和文本指令对音频进行分析;
## 论文
- [Qwen2-Audio Technical Report](https://arxiv.org/abs/2407.10759)
## 模型结构
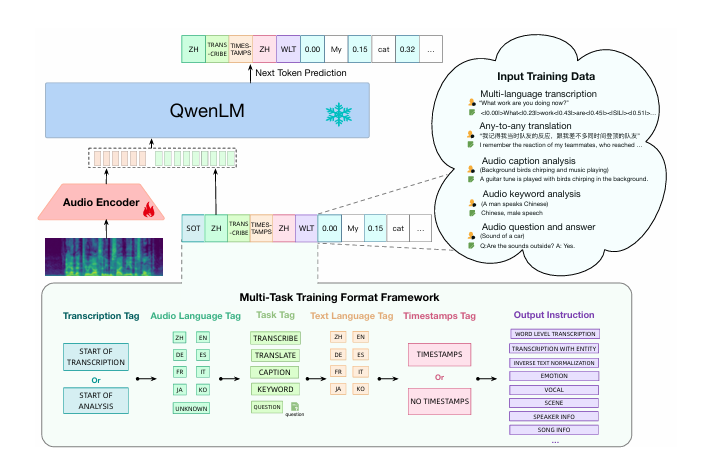
Qwen2-Audio的模型结构主要包含音频编码器和大型语言模型两部分,其设计旨在处理音频和文本输入以生成文本输出,以下是对其模型结构的详细介绍:
1. 音频编码器
初始化基础:Qwen2-Audio的音频编码器初始化基于Whisper-large-v3模型。Whisper-large-v3是一个在大规模音频数据上预训练的模型,具有良好的音频特征提取能力,为Qwen2-Audio的音频编码器提供了一个强大的起点。
音频数据预处理:
重采样:将音频数据重采样到16kHz的频率,统一音频的采样率,以便模型能够更好地处理不同来源的音频数据。
2. 大型语言模型
基础组件:Qwen2-Audio采用了Qwen-7B作为其大型语言模型的基础组件。Qwen-7B是一个具有强大语言理解和生成能力的模型,为Qwen2-Audio提供了丰富的语言知识和表达能力。
参数规模:整个Qwen2-Audio模型的参数总量为82亿参数。这些参数分布在音频编码器和大型语言模型中,使得模型能够学习到复杂的音频和语言特征,并生成准确、流畅的文本输出。
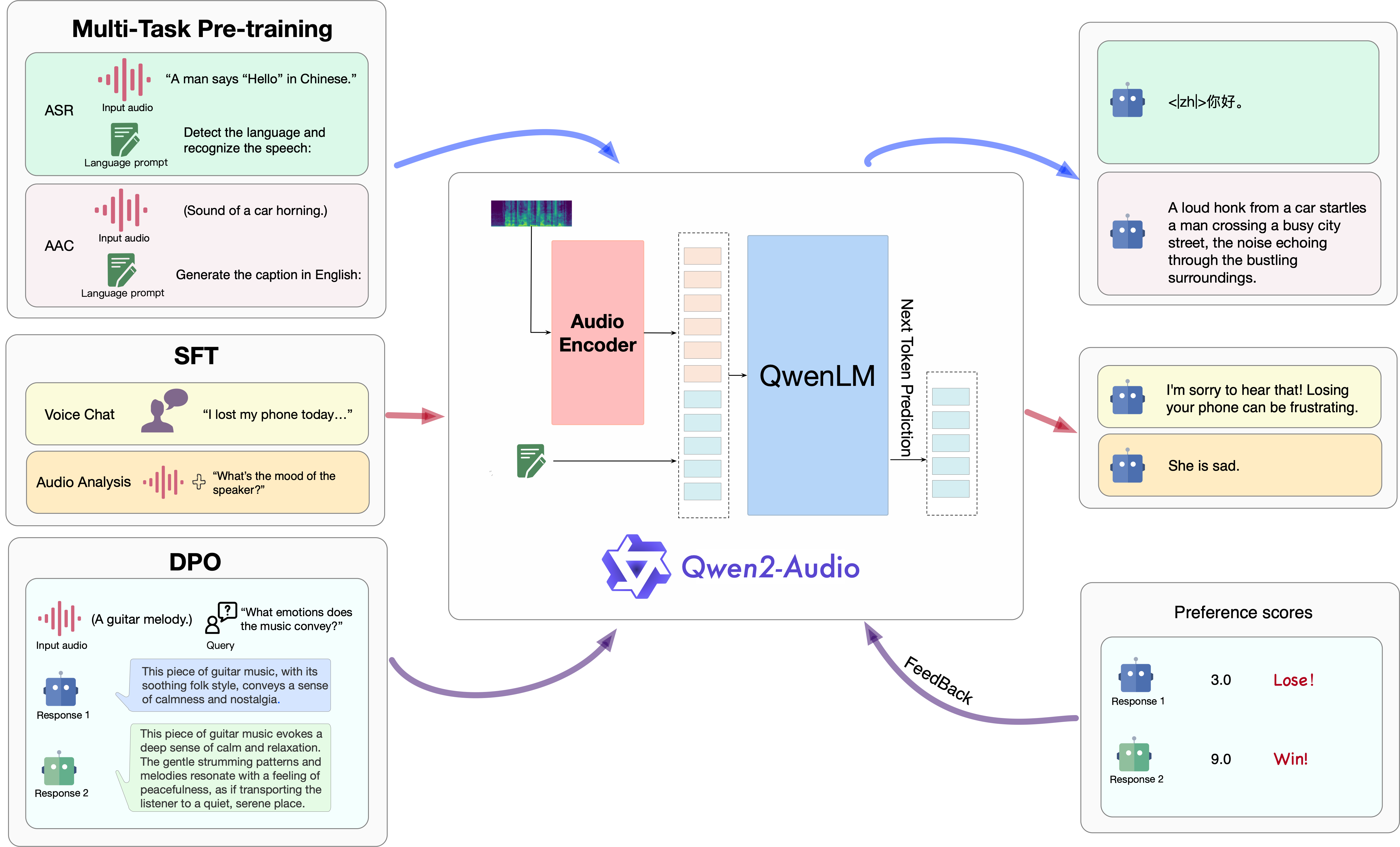
## 算法原理
Qwen2-Audio的技术原理涵盖了以下几个方面:
* 多模态输入处理:模型能接收并处理音频和文本两种模态的输入。
* 预训练与微调:在大量多模态数据上进行预训练,学习语言和音频的联合表示,并通过微调提高特定应用场景下的性能。
* 注意力机制:使用注意力机制加强音频和文本之间的关联。
* 条件文本生成:根据给定的音频和文本条件生成响应文本。
* 编码器-解码器架构:采用编码器-解码器架构,处理输入并生成输出文本。
* Transformer架构:作为transformers库的一部分,采用Transformer架构处理序列数据。
* 优化算法:使用优化算法调整模型参数,提高预测准确性。
## 环境配置
### Docker(方法一)
[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.3-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=64G --privileged=true --network=host --device=/dev/kfd --device=/dev/dri/ --group-add video --name qwen2-audio bash
cd /path/your_code_data/Qwen2-Audio/demo
pip install -r requirements_web_demo.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install git+https://github.com/modelscope/swift.git#egg=ms-swift[llm]
pip install git+https://github.com/huggingface/transformers.git
```
### Dockerfile(方法二)
```
cd /path/your_code_data/docker
docker build --no-cache -t qwen2-audio:latest .
docker run --shm-size=64G --name qwen2-audio -v /opt/hyhal:/opt/hyhal:ro --privileged=true --network=host --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it qwen2-audio bash
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.3
python:python3.10
torch:2.3.0
torchvision: 0.18.0
deepspped: 0.14.2
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
conda create -n qwen2-audio python=3.10
conda activate qwen2-audio
cd /path/your_code_data/Qwen2-Audio/demo
pip install -r requirements_web_demo.txt -i http://mirrors.aliyun.com/pypi/simple
```
## 数据集
迷你数据集 [run.py](./finetune/run.py), 格式已经写入**run.py**文件中,可以按照以下格式自备json文件。
预训练需要准备你的训练数据,每个样本对应一个conversation+id,示例如下所示:用于正常训练的完整数据集请按此目录结构进行制备:
```
conversation = [
{
"role": "system", "content": "You are a helpful assistant."
},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/guess_age_gender.wav"
}
]
},
{
"role": "assistant", "content": "Yes, the speaker is female and in her twenties."
},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/translate_to_chinese.wav"
}
]
}
]
conversation1 = [
{
"role": "system", "content": "You are a helpful assistant."
},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"
},
{
"type": "text", "text": "What's that sound?"
},
]
},
{
"role": "assistant", "content": "It is the sound of glass shattering."
},
{
"role": "user",
"content": [
{"type": "text", "text": "What can you do when you hear that?"},
]
},
{
"role": "assistant",
"content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property."
},
{
"role": "user", "content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"
},
{"type": "text", "text": "What does the person say?"},
]
}
]
```
## 训练
### 单机多卡
训练需要修改**run.sh**文件中的参数,具体如下:
```
export GPUS_PER_NODE=6
export NCCL_IB_QPS_PER_CONNECTION=6
export WORLD_SIZE=1
export MASTER_ADDR=localhost
export MASTER_PORT=29586
export RANK=0
export MODEL_NAME_OR_PATH='/home/wanglch/Qwen2-Audio/Qwen2-Audio-7B-Instruct'
```
运行指令:
```
cd finetune
bash run.sh
```
## 推理
执行多种任务时需要对以下参数进行修改,可使用中文指令,如下:
```
processor = 模型路径
model = 模型路径
```
### 单机单卡
```
python qwen2_audio_inference.py
```
## result
### 语音交流推理
### 精度
测试数据: [run.py](./finetune/run.py)中的测试微型数据集 ,使用的加速卡:K100AI/A800。
| device | train_loss |
| :------: | :------: |
| K100AI | 1.7161635160 |
| A800 | 1.734375 |
## 应用场景
### 算法类别
`语音对话`
### 热点应用行业
`金融,教育,政府,科研,制造,能源,交通`
## 预训练权重
- [Qwen/Qwen2-Audio-7B-Instruct](https://modelscope.cn/models/qwen/Qwen2-Audio-7B-Instruct)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/qwen2-audio_pytorch
## 参考资料
- [Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models](https://arxiv.org/abs/2311.07919)
- [Qwen2-Audio Technical Report](https://arxiv.org/abs/2407.10759)
- [Qwen2-Audio github](https://github.com/QwenLM/Qwen2-Audio)
