# Qwen1.5
## 论文
无
## 模型结构
Qwen1.5是阿里云开源大型语言模型系列,是Qwen2.0的beta版本。相较于以往版本,本次更新着重提升了Chat模型与人类偏好的对齐程度,并且显著增强了模型的多语言处理能力。在序列长度方面,所有规模模型均已实现 32768 个tokens的上下文长度范围支持。同时,预训练 Base 模型的质量也有关键优化,有望在微调过程中带来更佳体验。
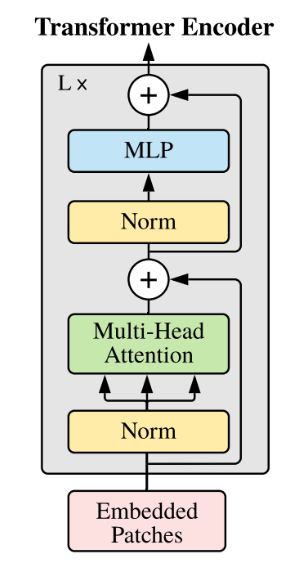
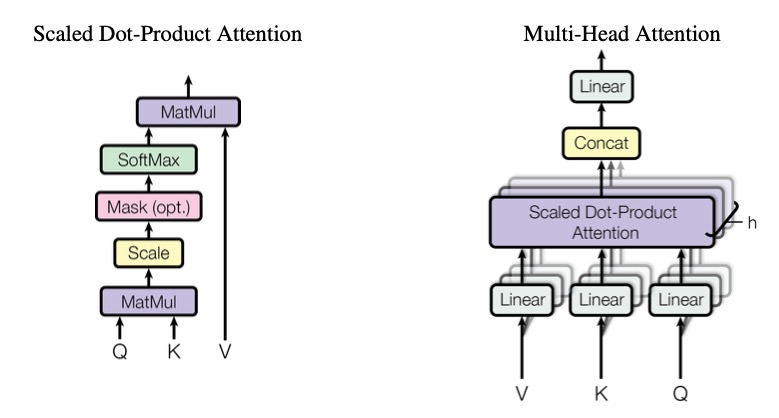
## 算法原理
和Qwen一样,Qwen1.5仍然是一个decoder-only的transformer模型,使用SwiGLU激活函数、RoPE、多头注意力机制等。
## 环境配置
### Docker(方法一)
提供[光源](https://www.sourcefind.cn/#/image/dcu/custom)拉取推理的docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.1-rc5-rocblas104381-0915-das1.6-py3.10-20250916-rc2
# 用上面拉取docker镜像的ID替换
# 主机端路径
# 容器映射路径
# 若要在主机端和容器端映射端口需要删除--network host参数
docker run -it --name qwen1.5_vllm --privileged --shm-size=64G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal -v : /bin/bash
```
`Tips:若在K100/Z100L上使用,使用定制镜像docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:vllm0.5.0-dtk24.04.1-ubuntu20.04-py310-zk-v1,K100/Z100L不支持awq量化`
### Dockerfile(方法二)
```
# 主机端路径
# 容器映射路径
docker build -t qwen1.5:latest .
docker run -it --name qwen1.5_vllm --privileged --shm-size=64G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v : qwen1.5:latest /bin/bash
```
### Anaconda(方法三)
```
conda create -n qwen1.5_vllm python=3.10
```
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
* DTK驱动:dtk25.04.01
* Pytorch: 2.4.0
* triton: 3.0.0
* lmslim: 0.2.1
* flash_attn: 2.6.1
* flash_mla: 1.0.0
* vllm: 0.9.2
* python: python3.10
`Tips:需先安装相关依赖,最后安装vllm包`
环境变量:
export ALLREDUCE_STREAM_WITH_COMPUTE=1
export VLLM_NUMA_BIND=1
export VLLM_RANK0_NUMA=0
export VLLM_RANK1_NUMA=1
export VLLM_RANK2_NUMA=2
export VLLM_RANK3_NUMA=3
export VLLM_RANK4_NUMA=4
export VLLM_RANK5_NUMA=5
export VLLM_RANK6_NUMA=6
export VLLM_RANK7_NUMA=7
## 数据集
无
## 推理
### 模型下载
| 基座模型 | chat模型 | GPTQ模型 | AWQ模型 |
| ----------------------------------------------------- | ----------------------------------------------------------------- | ------------------------------------------------------------------------------------- | ------------------------------------------------------------------------- |
| [Qwen-7B](https://huggingface.co/Qwen/Qwen1.5-7B) | [Qwen-7B-Chat](https://huggingface.co/Qwen/Qwen-7B-Chat) | [Qwen-7B-Chat-GPTQ-Int4](https://huggingface.co/Qwen/Qwen-7B-Chat-Int4) | |
| [Qwen-14B](https://huggingface.co/Qwen/Qwen1.5-14B) | [Qwen-14B-Chat](https://huggingface.co/Qwen/Qwen-14B-Chat) | [Qwen-14B-Chat-GPTQ-Int4](https://huggingface.co/Qwen/Qwen1.5-14B-Chat-GPTQ-Int4) | |
| [Qwen-72B](https://huggingface.co/Qwen/Qwen1.5-72B) | [Qwen-72B-Chat](https://huggingface.co/Qwen/Qwen1.5-72B-Chat) | [Qwen-72B-Chat-GPTQ-Int4](https://huggingface.co/Qwen/Qwen1.5-72B-Chat-GPTQ-Int4) | |
| [Qwen1.5-7B](https://huggingface.co/Qwen/Qwen1.5-7B) | [Qwen1.5-7B-Chat](https://huggingface.co/Qwen/Qwen1.5-7B-Chat) | [Qwen1.5-7B-Chat-GPTQ-Int4](https://huggingface.co/Qwen/Qwen1.5-7B-Chat-GPTQ-Int4) | [Qwen1.5-7B-Chat-AWQ](https://huggingface.co/Qwen/Qwen1.5-7B-Chat-AWQ) |
| [Qwen1.5-14B](https://huggingface.co/Qwen/Qwen1.5-14B) | [Qwen1.5-14B-Chat](https://huggingface.co/Qwen/Qwen1.5-14B-Chat) | [Qwen1.5-14B-Chat-GPTQ-Int4](https://huggingface.co/Qwen/Qwen1.5-14B-Chat-GPTQ-Int4) | [Qwen1.5-14B-Chat-AWQ](https://huggingface.co/Qwen/Qwen1.5-14B-Chat-AWQ) |
| [Qwen1.5-32B](https://huggingface.co/Qwen/Qwen1.5-32B) | [Qwen1.5-32B-Chat](https://huggingface.co/Qwen/Qwen1.5-32B-Chat) | [Qwen1.5-32B-Chat-GPTQ-Int4](https://huggingface.co/Qwen/Qwen1.5-32B-Chat-GPTQ-Int4) | [Qwen1.5-32B-Chat-AWQ](https://huggingface.co/Qwen/Qwen1.5-32B-Chat-AWQ) |
| [Qwen1.5-72B](https://huggingface.co/Qwen/Qwen1.5-72B) | [Qwen1.5-72B-Chat](https://huggingface.co/Qwen/Qwen1.5-72B-Chat) | [Qwen1.5-72B-Chat-GPTQ-Int4](https://huggingface.co/Qwen/Qwen1.5-72B-Chat-GPTQ-Int4) | [Qwen1.5-72B-Chat-AWQ](https://huggingface.co/Qwen/Qwen1.5-72B-Chat-AWQ) |
| [Qwen1.5-110B](https://huggingface.co/Qwen/Qwen1.5-110B) | [Qwen1.5-110B-Chat](https://huggingface.co/Qwen/Qwen1.5-110B-Chat) | [Qwen1.5-110B-Chat-GPTQ-Int4](https://huggingface.co/Qwen/Qwen1.5-110B-Chat-GPTQ-Int4) | [Qwen1.5-110B-Chat-AWQ](https://huggingface.co/Qwen/Qwen1.5-110B-Chat-AWQ) |
| [Qwen2-7B](https://huggingface.co/unsloth/Qwen2-7B) | [Qwen2-7B-Instruct](https://huggingface.co/Qwen/Qwen2-7B-Instruct) | [Qwen2-7B-Instruct-GPTQ-Int4](https://huggingface.co/Qwen/Qwen2-7B-Instruct-GPTQ-Int4) | [Qwen2-7B-Instruct-AWQ](https://huggingface.co/Qwen/Qwen2-7B-Instruct-AWQ) |
| [Qwen2-72B](https://huggingface.co/Qwen/Qwen2-72B) | [Qwen2-72B-Instruct](https://huggingface.co/Qwen/Qwen2-72B-Instruct) | [Qwen2-72B-Instruct-GPTQ-Int4](https://huggingface.co/Qwen/Qwen2-72B-Instruct-GPTQ-Int4) | [Qwen2-72B-Instruct-AWQ](https://huggingface.co/Qwen/Qwen2-72B-Instruct-AWQ) |
### 离线批量推理
```bash
python examples/offline_inference/basic/basic.py
```
其中,本示例脚本在代码中直接定义了 `prompts`,并设置 `temperature=0.8`、`top_p=0.95`、`max_tokens=16`;如需调整请修改脚本中的参数。`model` 在脚本中指定为本地模型路径;`tensor_parallel_size=1` 表示使用 1 卡;`dtype="float16"` 为推理数据类型(若权重为 bfloat16,请相应调整)。本示例未使用 `quantization` 参数,量化推理请参考下文性能测试示例。
### 离线批量推理性能测试
1、指定输入输出
```bash
python benchmarks/benchmark_throughput.py --num-prompts 1 --input-len 32 --output-len 128 --model /your/model/path -tp 1 --trust-remote-code --enforce-eager --dtype float16
```
其中 `--num-prompts`是batch数,`--input-len`是输入seqlen,`--output-len`是输出token长度,`--model`为模型路径,`-tp`为使用卡数,`dtype="float16"`为推理数据类型,如果模型权重是bfloat16,需要修改为float16推理。若指定 `--output-len 1`即为首字延迟。`-q gptq`为使用gptq量化模型进行推理。
2、使用数据集
下载数据集:
[sharegpt_v3_unfiltered_cleaned_split](https://huggingface.co/datasets/learnanything/sharegpt_v3_unfiltered_cleaned_split)
```bash
python benchmarks/benchmark_throughput.py --num-prompts 1 --model /your/model/path --dataset-name sharegpt --dataset-path /path/to/ShareGPT_V3_unfiltered_cleaned_split.json -tp 1 --trust-remote-code --enforce-eager --dtype float16
```
其中 `--num-prompts`是batch数,`--model`为模型路径,`--dataset`为使用的数据集,`-tp`为使用卡数,`dtype="float16"`为推理数据类型,如果模型权重是bfloat16,需要修改为float16推理。`-q gptq`为使用gptq量化模型进行推理。
### OpenAI api服务推理性能测试
1、启动服务端:
```bash
vllm serve --model /your/model/path --enforce-eager --dtype float16 --trust-remote-code --tensor-parallel-size 1
```
2、启动客户端:
```
python benchmarks/benchmark_serving.py --model /your/model/path --dataset-name sharegpt --dataset-path /path/to/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 1 --trust-remote-code
```
参数同使用数据集,离线批量推理性能测试,具体参考[benchmarks/benchmark_serving.py](/codes/modelzoo/qwen1.5_vllm/-/blob/master/benchmarks/benchmark_serving.py)
### OpenAI兼容服务
启动服务:
```bash
vllm serve /your/model/path --enforce-eager --dtype float16 --trust-remote-code
```
这里serve之后为加载模型路径,`--dtype`为数据类型:float16,默认情况使用tokenizer中的预定义聊天模板,`--chat-template`可以添加新模板覆盖默认模板,`-q gptq`为使用gptq量化模型进行推理,`-q awqq`为使用awq量化模型进行推理。
列出模型型号:
```bash
curl http://localhost:8000/v1/models
```
### OpenAI Completions API和vllm结合使用
```bash
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/your/model/path",
"prompt": "What is deep learning?",
"max_tokens": 7,
"temperature": 0
}'
```
或者使用[examples/online_serving/openai_completion_client.py](examples/online_serving/openai_completion_client.py)
### OpenAI Chat API和vllm结合使用
```bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/your/model/path",
"max_tokens": 128,
"messages": [
{"role": "system", "content": "What is deep learning?"},
{"role": "user", "content": "What is deep learning?"}
]
}'
```
或者使用[examples/online_serving/openai_chat_completion_client.py](examples/online_serving/openai_chat_completion_client.py)
### **gradio和vllm结合使用**
1.安装gradio
```
pip install gradio
```
2.安装必要文件
2.1 启动gradio服务,根据提示操作
```
python gradio_openai_chatbot_webserver.py --model "Qwen/Qwen1.5-7B-Chat" --model-url http://localhost:8000/v1 --temp 0.8 --stop-token-ids ""
```
2.2 更改文件权限
打开提示下载文件目录,输入以下命令给予权限
```
chmod +x frpc_linux_amd64_v0.*
```
2.3端口映射
```
ssh -L 8000:计算节点IP:8000 -L 8001:计算节点IP:8001 用户名@登录节点 -p 登录节点端口
```
3.启动OpenAI兼容服务
```
vllm serve /your/model/path --enforce-eager --dtype float16 --trust-remote-code --port 8000 --host "0.0.0.0"
```
4.启动gradio服务
```
python gradio_openai_chatbot_webserver.py --model "Qwen/Qwen1.5-7B-Chat" --model-url http://localhost:8000/v1 --temp 0.8 --stop-token-ids --host "0.0.0.0" --port 8001"
```
5.使用对话服务
在浏览器中输入本地 URL,可以使用 Gradio 提供的对话服务。
## result
使用的加速卡:1张 DCU-K100_AI-64G
```
Prompt: 'What is deep learning?', Generated text: ' Deep learning is a subset of machine learning that involves the use of neural networks to model and solve complex problems. Neural networks are a network of interconnected nodes or " neurons" that are designed to recognize patterns in data, learn from examples, and make predictions or decisions.\nThe term "deep" in deep learning refers to the use of multiple layers or hidden layers in these neural networks. Each layer processes the input data in a different way, extracting increasingly abstract features as the data passes through.'
```
### 精度
无
## 应用场景
### 算法类别
对话问答
### 热点应用行业
金融,科研,教育
## 源码仓库及问题反馈
* [https://developer.sourcefind.cn/codes/modelzoo/qwen1.5_vllm](https://developer.sourcefind.cn/codes/modelzoo/qwen1.5_vllm)
## 参考资料
* [https://github.com/vllm-project/vllm](https://github.com/vllm-project/vllm)