# Qwen1.5
## 论文
无
## 模型结构
Qwen1.5是阿里云开源大型语言模型系列,是Qwen2.0的beta版本。相较于以往版本,本次更新着重提升了Chat模型与人类偏好的对齐程度,并且显著增强了模型的多语言处理能力。在序列长度方面,所有规模模型均已实现 32768 个tokens的上下文长度范围支持。同时,预训练 Base 模型的质量也有关键优化,有望在微调过程中带来更佳体验。
## 算法原理
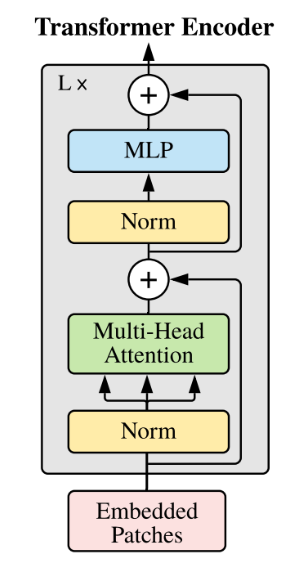
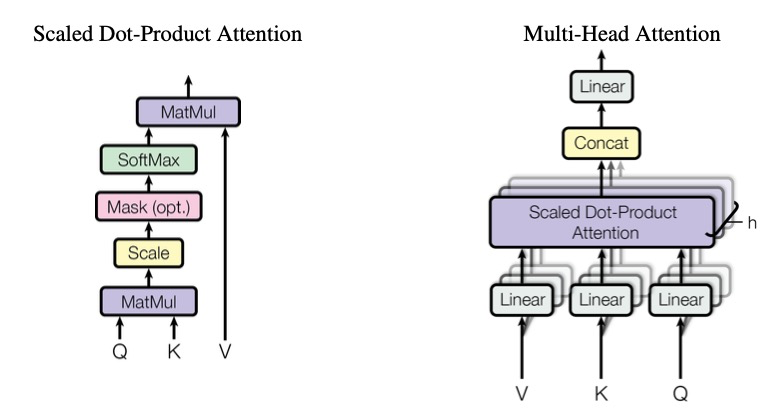
和Qwen一样,Qwen1.5仍然是一个decoder-only的transformer模型,使用SwiGLU激活函数、RoPE、多头注意力机制等。
## 环境配置
### Docker(方法一)
推荐使用docker方式运行, 此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --shm-size=1024G -v $PWD/qwen1.5-pytorch:/home/Qwen1.5-pytorch -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name Qwen1.5-pytorch bash # 为以上拉取的docker的镜像ID替换,本镜像为:ffa1f63239fc
cd /home/Qwen1.5-pytorch
pip install -r requirement.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
Tips:以上dtk驱动、python、torch、xfomers、vllm等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
docker build -t qwen1.5:latest .
docker run -it --shm-size=1024G -v $PWD/qwen1.5-pytorch:/home/Qwen1.5-pytorch -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name Qwen1.5-pytorch qwen1.5 bash
pip install -r requirement.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.1
python:python3.10
torch:2.1.0
torchvision:0.16.0
triton:2.1.0
apex:1.1.0
deepspeed:0.12.3
flash_attn:2.0.4
xformers:0.0.25
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirement.txt安装:
```
pip install -r requirement.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
## 数据集
使用alpaca_gpt4_zh数据集,已经包含在data目录中,具体文件为alpaca_gpt4_data_zh.json
训练数据目录结构如下,用于正常训练的完整数据集请按此目录结构进行制备:
```
── data
├── alpaca_gpt4_data_en.json
└── alpaca_gpt4_data_zh.json
```
## 训练
使用LLaMA-Factory框架微调
### 模型下载
[qwen1.5-14B-Chat模型下载](https://huggingface.co/Qwen/Qwen1.5-14B-Chat)
### 单机单卡(LoRA-finetune)
```
cd finetune
sh single_dcu_finetune_lora.sh
```
### 单机多卡(LoRA-finetune)
```
sh multi_dcus_finetune_lora.sh
```
## 推理
使用vllm框架推理
### 单机单卡
```
python ./inference/inference_vllm/Qwen1.5-7b_single_dcu_inference.py
```
### 单机多卡
```
python ./inference/inference_vllm/Qwen1.5-14b_multi_dcu_inference.py
```
其中,prompts为提示词,model为模型路径,tensor_parallel_size=4为使用卡数。
## result
使用的加速卡:4张 DCU-K100-64G
```
Prompt: 'The capital of France is', Generated text: '______.(\u3000\u3000)\nA. New York\nB. Paris\n'
```
### 精度
模型Qwen1.5-14B-Chat,数据(LoRA finetune):alpaca_gpt4_zh,4卡,zero3训练。
| device | train_loss |
|:------------:|:----------:|
| DCU-K100-64G | 1.3523 |
| GPU A800 | 1.3521 |
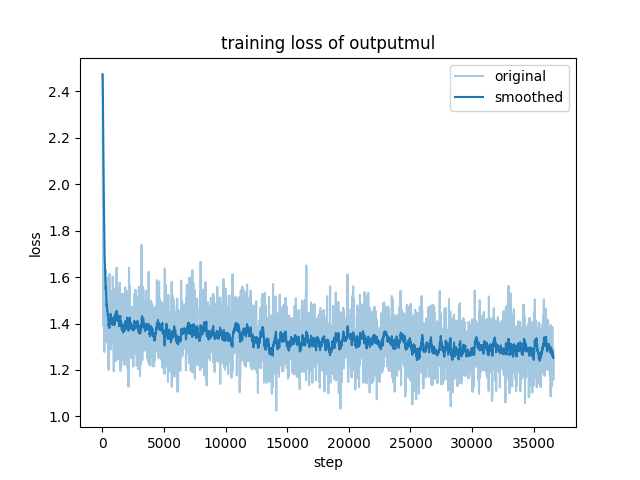
在DCU上训练的收敛情况:
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`科研,教育,政府,金融`
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/qwen1.5-pytorch.git
## 参考资料
- https://github.com/hiyouga/LLaMA-Factory/tree/main
- https://huggingface.co/Qwen/Qwen1.5-14B-Chat
- https://github.com/QwenLM/Qwen1.5