# Pyramid-Flow
## 论文
`PYRAMIDAL FLOW MATCHING FOR EFFICIENT VIDEO GENERATIVE MODELING`
* https://arxiv.org/pdf/2410.05954
## 模型结构
该项目采用flux.1的模型结构,增加了人物结构的稳定性。
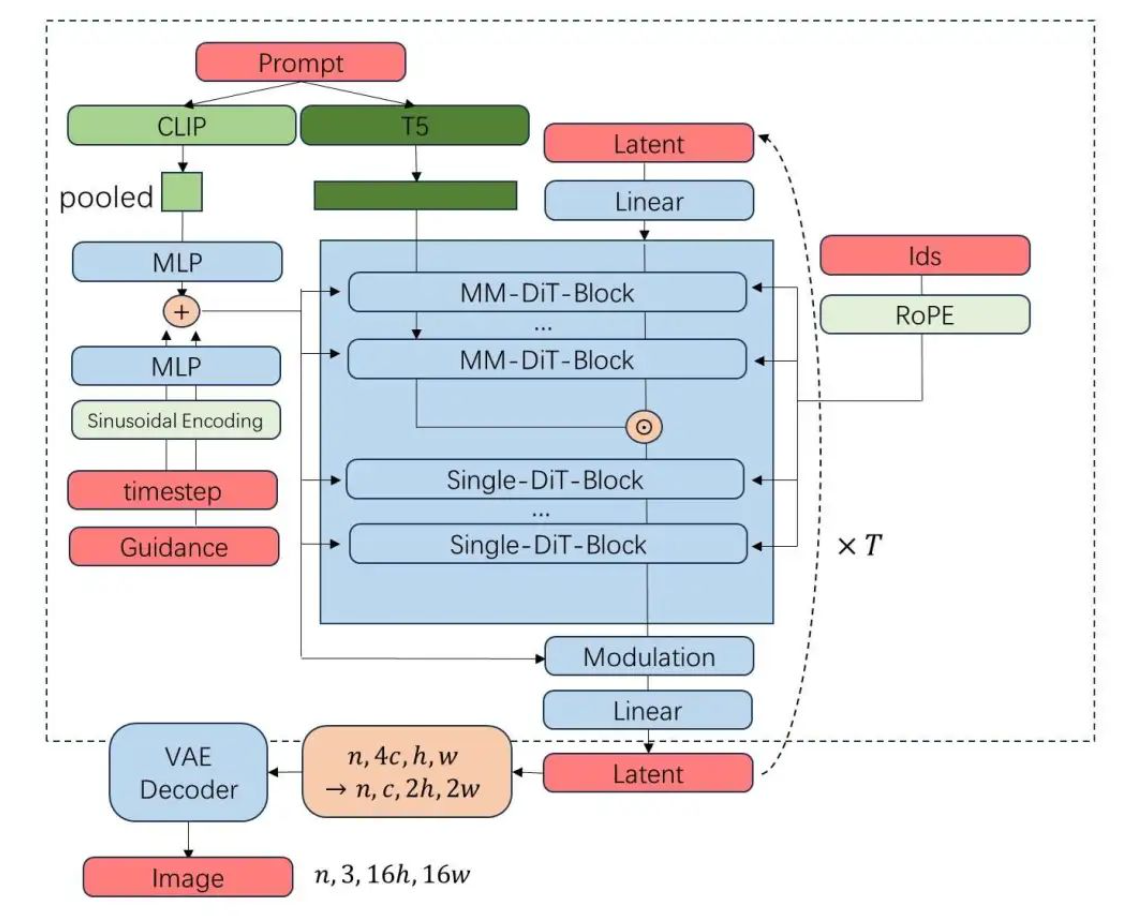
## 算法原理
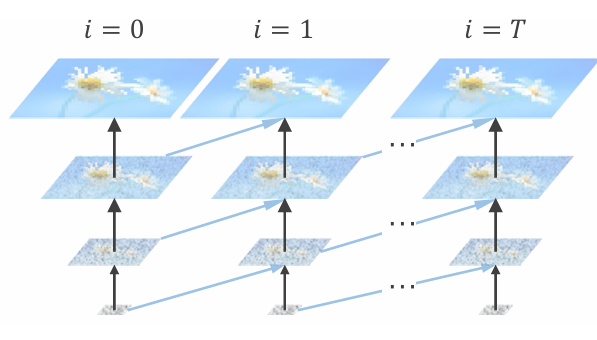
该算法主要关注时间-空间问题的解决,如下:
1、将生成过程分解为多个金字塔阶段,每个阶段在更低分辨率的压缩空间中进行操作,最终阶段才在原始分辨率下进行,从而减少冗余计算。
2、使用逐渐增加分辨率的压缩历史作为条件,进一步减少训练所需的视频标记数量,提高训练效率。
 ## 环境配置
### Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-py3.10-dtk24.04.3-ubuntu20.04
docker run --shm-size 50g --network=host --name=pyramid-flow --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
pip install -r requirements.txt
### Dockerfile(方法二)
docker build -t : .
docker run --shm-size 50g --network=host --name=pyramid-flow --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
pip install -r requirements.txt
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
https://developer.sourcefind.cn/tool/
DTK驱动:dtk24.04.3
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install -r requirements.txt
## 数据集
除本项目提供的数据集外,也可自行准备其他可用数据集。
video: [VIDGEN-1M](https://huggingface.co/datasets/Fudan-FUXI/VIDGEN-1M)
image: [text-to-image-2M](https://hf-mirror.com/datasets/jackyhate/text-to-image-2M/tree/)
### VAE数据格式
```
# For Video
{"video": video_path}
# For Image
{"image": image_path}
```
数据处理脚本
```bash
cd extra_utils
python generate_vae_annotation.py \
--data_root="/path/to/[image|video]" \
--data_type="[image|video]" \
--save_path="/path/to/save/xxx.jsonl"
```
### DiT数据格式
```
{"video": video_path, "text": text prompt, "latent": extracted video vae latent, "text_fea": extracted text feature}
```
数据处理脚本
```bash
cd extra_utils
python get_video_text.py \
--video_root="/path/to/video_root" \
--caption_json_path="/path/to/caption_file" \
--save_root="/path/to/save_file_root" \
--video_latent_root="/path/to/save/video_latent_root" \
--text_fea_root="/path/to/save/text_feature_root"
```
注意:该脚本仅适用于给定数据集,更多数据处理脚本见`extra_utils`。
## 训练
### VAE
```bash
bash scripts/train_causal_video_vae.sh
```
注意:需要在该文件中修改相应参数。
### DiT
#### 数据准备
1、提取视频vae-latent
```bash
bash scripts/extract_vae_latent.sh
```
2、提取T5文本特征(可选)
```bash
bash scripts/extract_text_feature.sh
```
注意:在运行前需确保相应参数正确。
### run
```bash
# 使用时间金字塔的自回归视频生成训练
bash scripts/train_pyramid_flow.sh
```
```bash
# 使用 pyramid-flow 进行全序列扩散训练
bash scripts/train_pyramid_flow_without_ar.sh
```
注意:在运行前需确保相应参数正确,若使用图像训练,可使用`extra_utils/generate_image_text.py`处理相应数据,更多见`参考资料`。
## 推理
```bash
# 多卡推理 - 增加推理速度
HIP_VISIBLE_DEVICES=0,1 bash scripts/inference_multigpu.sh
```
```bash
# 运行video_generation_demo.ipynb代码时需启动jupyter服务
jupyter notebook --no-browser --ip=0.0.0.0 --allow-root
```
### webui
```bash
export HF_ENDPOINT=https://hf-mirror.com
```
```bash
python app.py
```
## result
|类别|输入|结果|
|:---:|:---:|:---:|
|t2v|a cat on the moon, salt desert, cinematic style, shot on 35mm film, vivid colors| |
|i2v|
## 环境配置
### Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-py3.10-dtk24.04.3-ubuntu20.04
docker run --shm-size 50g --network=host --name=pyramid-flow --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
pip install -r requirements.txt
### Dockerfile(方法二)
docker build -t : .
docker run --shm-size 50g --network=host --name=pyramid-flow --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
pip install -r requirements.txt
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
https://developer.sourcefind.cn/tool/
DTK驱动:dtk24.04.3
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install -r requirements.txt
## 数据集
除本项目提供的数据集外,也可自行准备其他可用数据集。
video: [VIDGEN-1M](https://huggingface.co/datasets/Fudan-FUXI/VIDGEN-1M)
image: [text-to-image-2M](https://hf-mirror.com/datasets/jackyhate/text-to-image-2M/tree/)
### VAE数据格式
```
# For Video
{"video": video_path}
# For Image
{"image": image_path}
```
数据处理脚本
```bash
cd extra_utils
python generate_vae_annotation.py \
--data_root="/path/to/[image|video]" \
--data_type="[image|video]" \
--save_path="/path/to/save/xxx.jsonl"
```
### DiT数据格式
```
{"video": video_path, "text": text prompt, "latent": extracted video vae latent, "text_fea": extracted text feature}
```
数据处理脚本
```bash
cd extra_utils
python get_video_text.py \
--video_root="/path/to/video_root" \
--caption_json_path="/path/to/caption_file" \
--save_root="/path/to/save_file_root" \
--video_latent_root="/path/to/save/video_latent_root" \
--text_fea_root="/path/to/save/text_feature_root"
```
注意:该脚本仅适用于给定数据集,更多数据处理脚本见`extra_utils`。
## 训练
### VAE
```bash
bash scripts/train_causal_video_vae.sh
```
注意:需要在该文件中修改相应参数。
### DiT
#### 数据准备
1、提取视频vae-latent
```bash
bash scripts/extract_vae_latent.sh
```
2、提取T5文本特征(可选)
```bash
bash scripts/extract_text_feature.sh
```
注意:在运行前需确保相应参数正确。
### run
```bash
# 使用时间金字塔的自回归视频生成训练
bash scripts/train_pyramid_flow.sh
```
```bash
# 使用 pyramid-flow 进行全序列扩散训练
bash scripts/train_pyramid_flow_without_ar.sh
```
注意:在运行前需确保相应参数正确,若使用图像训练,可使用`extra_utils/generate_image_text.py`处理相应数据,更多见`参考资料`。
## 推理
```bash
# 多卡推理 - 增加推理速度
HIP_VISIBLE_DEVICES=0,1 bash scripts/inference_multigpu.sh
```
```bash
# 运行video_generation_demo.ipynb代码时需启动jupyter服务
jupyter notebook --no-browser --ip=0.0.0.0 --allow-root
```
### webui
```bash
export HF_ENDPOINT=https://hf-mirror.com
```
```bash
python app.py
```
## result
|类别|输入|结果|
|:---:|:---:|:---:|
|t2v|a cat on the moon, salt desert, cinematic style, shot on 35mm film, vivid colors| |
|i2v| |
### 精度
与Nvidia GPU精度一致。
## 应用场景
### 算法类别
`AIGC`
### 热点应用行业
`电商,教育,广媒`
## 预训练权重
[huggingface](https://huggingface.co/rain1011/pyramid-flow-miniflux/tree/main)
vgg_lpips [google-driver](https://drive.google.com/file/d/1YeFlX5BKKw-HGkjNd1r7DSwas1iJJwqC/view)
### 权重文件结构
```
pyramid_flow_model/
└── pyramid-flow-miniflux
├── vgg_lpips.pth
├── causal_video_vae
│ ├── config.json
│ └── diffusion_pytorch_model.bin
├── diffusion_transformer_384p
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── diffusion_transformer_image
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── README.md
├── text_encoder
│ ├── config.json
│ └── model.safetensors
├── text_encoder_2
│ ├── config.json
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ └── model.safetensors.index.json
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── tokenizer_2
├── special_tokens_map.json
├── spiece.model
├── tokenizer_config.json
└── tokenizer.json
```
## 源码仓库及问题反馈
* https://developer.sourcefind.cn/codes/modelzoo/pyramid-flow_pytorch
## 参考资料
* https://github.com/jy0205/Pyramid-Flow
* https://blog.csdn.net/2401_84760322/article/details/141558082
|
### 精度
与Nvidia GPU精度一致。
## 应用场景
### 算法类别
`AIGC`
### 热点应用行业
`电商,教育,广媒`
## 预训练权重
[huggingface](https://huggingface.co/rain1011/pyramid-flow-miniflux/tree/main)
vgg_lpips [google-driver](https://drive.google.com/file/d/1YeFlX5BKKw-HGkjNd1r7DSwas1iJJwqC/view)
### 权重文件结构
```
pyramid_flow_model/
└── pyramid-flow-miniflux
├── vgg_lpips.pth
├── causal_video_vae
│ ├── config.json
│ └── diffusion_pytorch_model.bin
├── diffusion_transformer_384p
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── diffusion_transformer_image
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── README.md
├── text_encoder
│ ├── config.json
│ └── model.safetensors
├── text_encoder_2
│ ├── config.json
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ └── model.safetensors.index.json
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── tokenizer_2
├── special_tokens_map.json
├── spiece.model
├── tokenizer_config.json
└── tokenizer.json
```
## 源码仓库及问题反馈
* https://developer.sourcefind.cn/codes/modelzoo/pyramid-flow_pytorch
## 参考资料
* https://github.com/jy0205/Pyramid-Flow
* https://blog.csdn.net/2401_84760322/article/details/141558082