
pyramid-flow
Showing
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
readme_imgs/alg.png
0 → 100644
{kind=link}
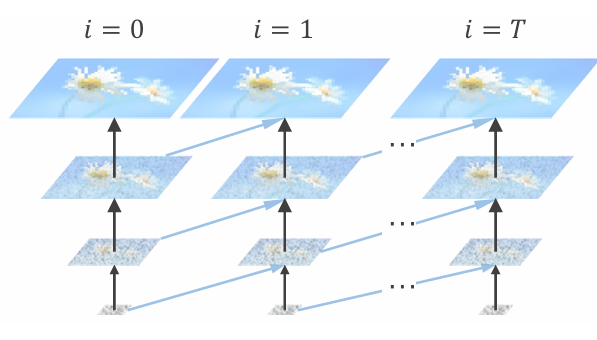
108 KB
readme_imgs/arch.png
0 → 100644
{kind=link}
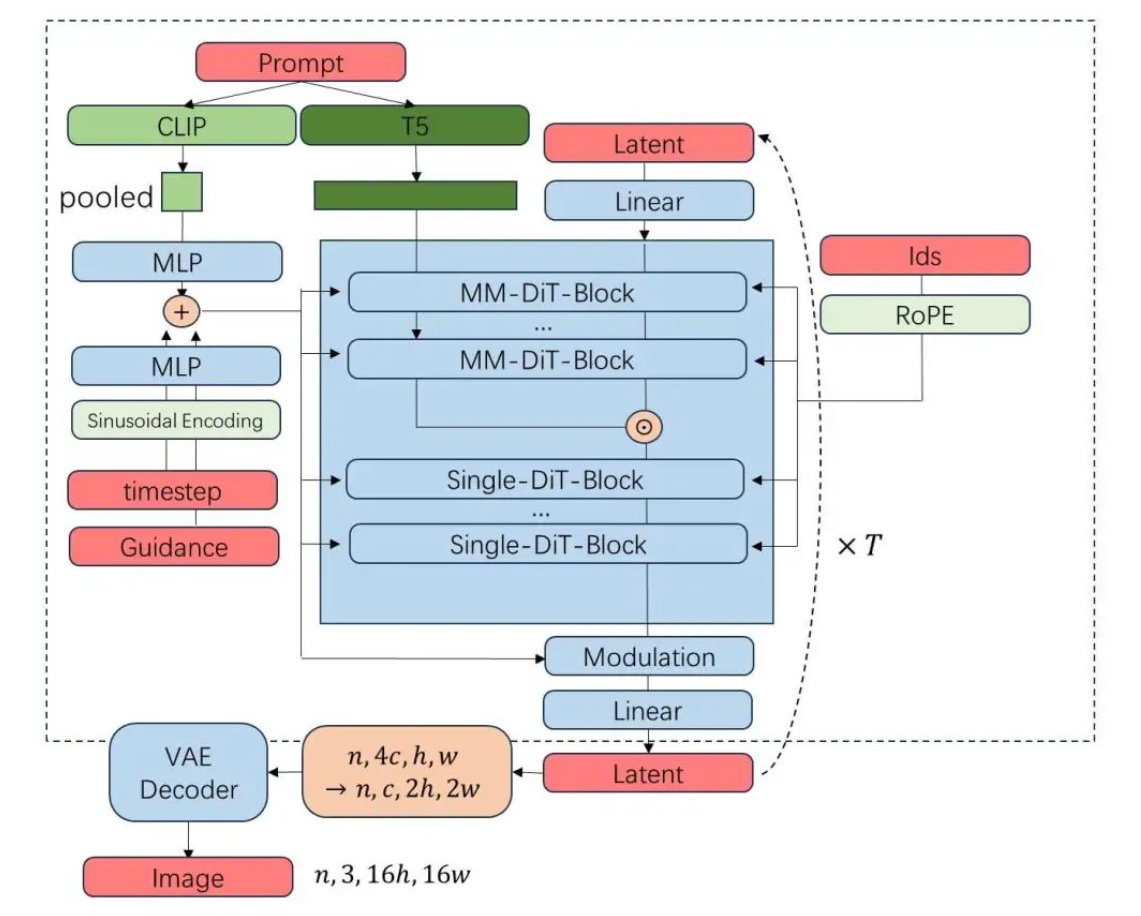
558 KB
readme_imgs/result.gif
0 → 100644
{kind=link}

5.39 MB
readme_imgs/result2.gif
0 → 100644
{kind=link}

5.28 MB
requirements.txt
0 → 100644
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.