
pyramid-flow
Showing
readme_imgs/alg.png
0 → 100644
{kind=link}
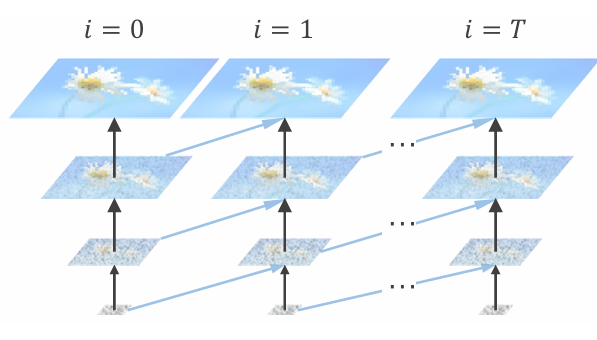
108 KB
readme_imgs/arch.png
0 → 100644
{kind=link}
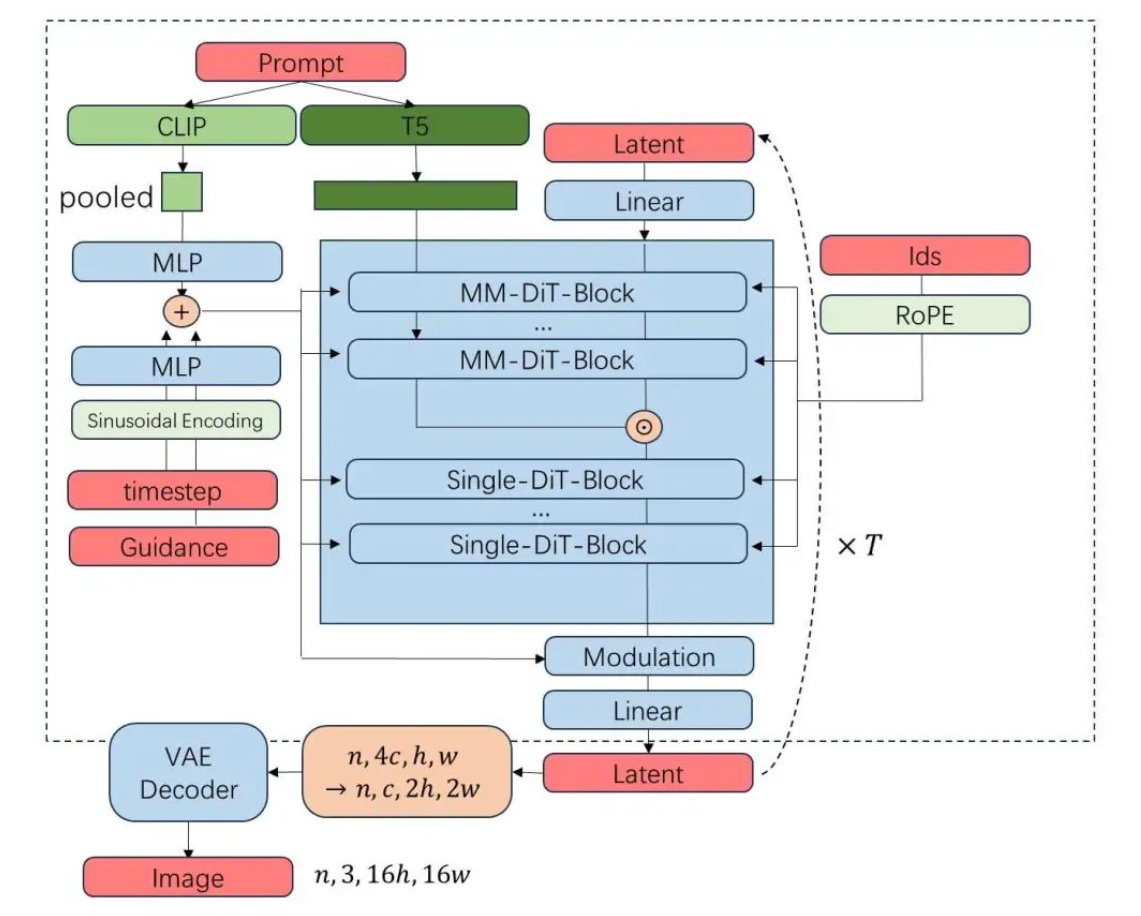
558 KB
readme_imgs/result.gif
0 → 100644
{kind=link}

5.39 MB
readme_imgs/result2.gif
0 → 100644
{kind=link}

5.28 MB
requirements.txt
0 → 100644
| wheel | ||
| # torch==2.1.2 | ||
| # torchvision==0.16.2 | ||
| transformers==4.39.3 | ||
| accelerate==0.30.0 | ||
| diffusers>=0.30.1 | ||
| numpy==1.24.4 | ||
| einops | ||
| ftfy | ||
| ipython | ||
| contexttimer | ||
| opencv-python-headless==4.10.0.84 | ||
| imageio==2.33.1 | ||
| imageio-ffmpeg==0.5.1 | ||
| packaging | ||
| pandas | ||
| plotly | ||
| pre-commit | ||
| python-magic | ||
| scikit-image | ||
| sentencepiece | ||
| spacy==3.7.5 | ||
| streamlit | ||
| timm==0.6.12 | ||
| tqdm | ||
| torchmetrics | ||
| tiktoken | ||
| jsonlines | ||
| tensorboardX | ||
| jupyter |