
1、新增warm up功能 2、新增图片叠加OCR字符功能
Showing
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
Doc/Images/res.jpg
0 → 100644
{kind=link}
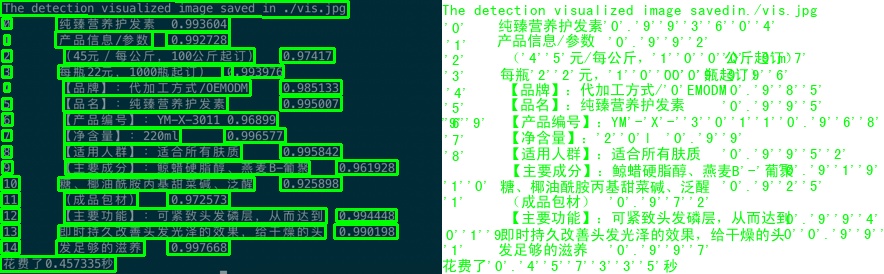
141 KB
This diff is collapsed.
Python/res.jpg
deleted
100755 → 0
{kind=link}
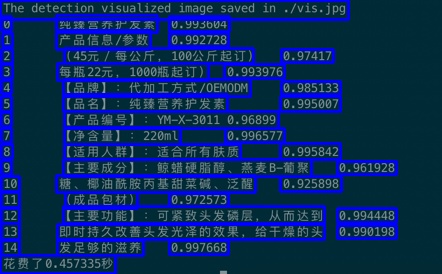
55.3 KB
{kind=link}
Resource/fonts/SimHei.ttf
0 → 100644
File added
Src/Utility/cv_put_Text.cpp
0 → 100644
Src/Utility/cv_put_Text.hpp
0 → 100644