# Phi-4-multimodal-instruct
## 论文
[Phi-4-Mini Technical Report: Compact yet Powerful Multimodal
Language Models via Mixture-of-LoRAs](https://arxiv.org/pdf/2503.01743)
## 模型结构
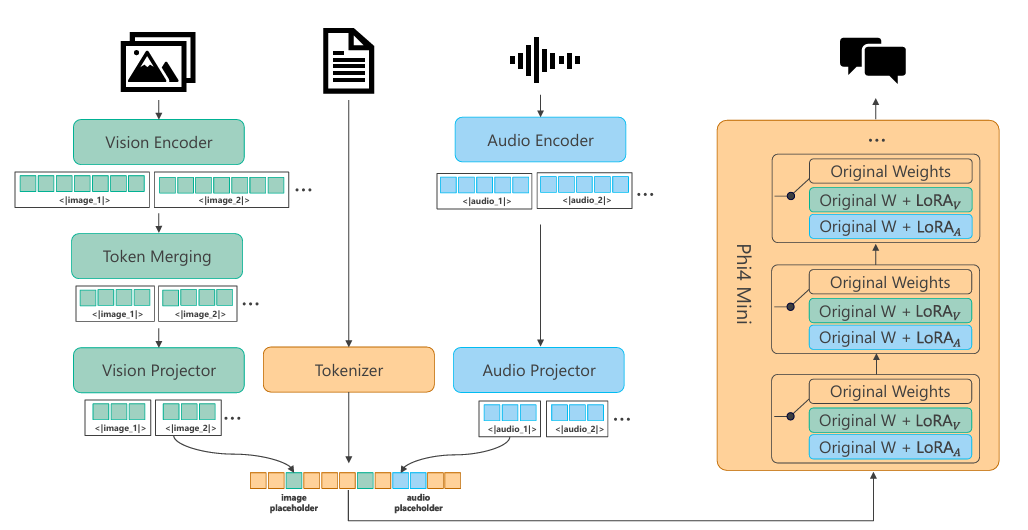
Phi-4-多模态是一个混合了LoRAs的单一模型,包括在同一表示空间内同时处理的语音、视觉和语言。其结果是一个能够处理文本、音频和视频输入的统一模型——不需要复杂的管道或不同模态的单独模型。Phi-4-multimodal建立在提高效率和可扩展性的新架构之上。它包含了更大的词汇表以改进处理,支持多语言功能,并将语言推理与多模态输入集成在一起。
## 算法原理
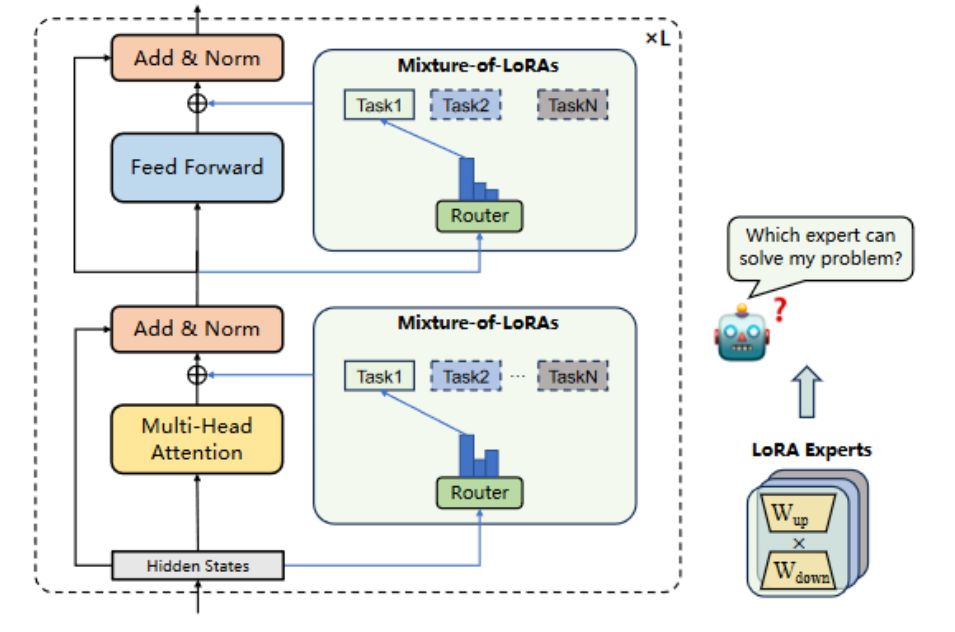
Mixture-of-LoRAs(MoA)的新型参数高效调整方法,旨在为LLMs的多任务学习提供更有效的解决方案。MoA通过结合多个领域特定的LoRA(Low-Rank Adaptation)模块,并使用显式路由策略来实现多任务学习,从而减少任务间的干扰,并提高每个单独任务的性能。此外,MoA允许对LoRA模型进行迭代适应,以便快速适应新领域。
## 环境配置
### Docker(方法一)
推荐使用docker方式运行, 此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-py3.10-dtk24.04.3-ubuntu20.04
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name phi-4 bash # 为以上拉取的docker的镜像ID替换
git clone http://developer.sourcefind.cn/codes/modelzoo/phi-4-multimodal-instruct_pytorch.git
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
docker build -t phi-4:latest .
docker run --shm-size 500g --network=host --name=phi-4 --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
git clone http://developer.sourcefind.cn/codes/modelzoo/phi-4-multimodal-instruct_pytorch.git
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.3
python:3.10
torch:2.3.0
flash-attn:2.6.1
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirement.txt安装:
```
git clone http://developer.sourcefind.cn/codes/modelzoo/phi-4-multimodal-instruct_pytorch.git
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
## 数据集
在ms-wift中自带测试数据集,使用[AI-ModelScope/LaTeX_OCR](https://www.modelscope.cn/datasets/AI-ModelScope/LaTeX_OCR/summary)数据集,使用脚本自动下载数据集,用于正常训练的完整数据集可参照该数据集格式进行自备。
## 训练
使用ms-swift框架微调
```
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
```
### 单机多卡
sh phi4_finetune.sh
可根据需要修改参数。
```
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model '/home/wanglch/Phi4/Phi-4-multimodal-instruct' \
--dataset 'AI-ModelScope/LaTeX_OCR:human_handwrite#20000' \
--train_type dummy \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--eval_steps 200 \
--save_steps 200 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
```
## 推理
### 单机单卡
文本推理
```
python phi4_text_inference.py
```
图片推理
```
python phi4_vision_inference.py
```
音频推理
```
python phi4_speech_inference.py
```
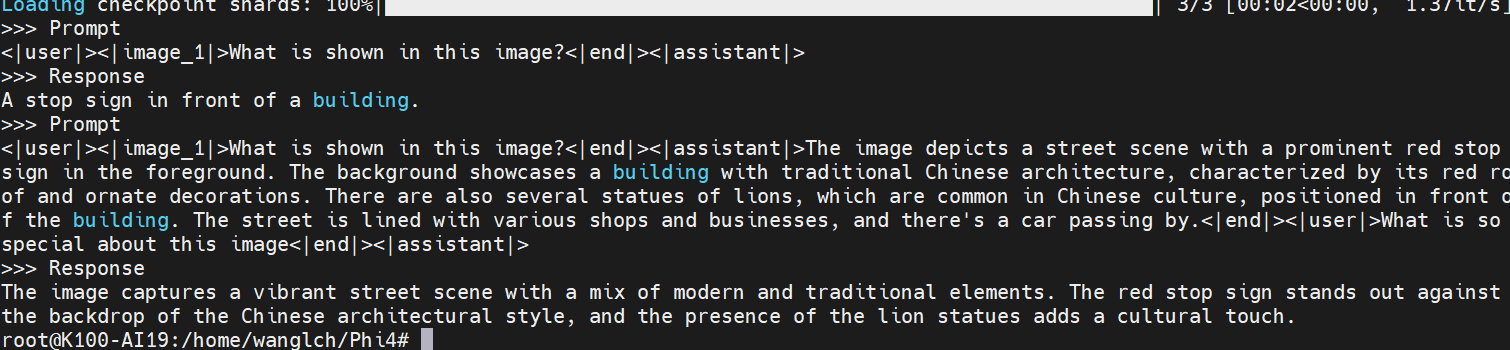
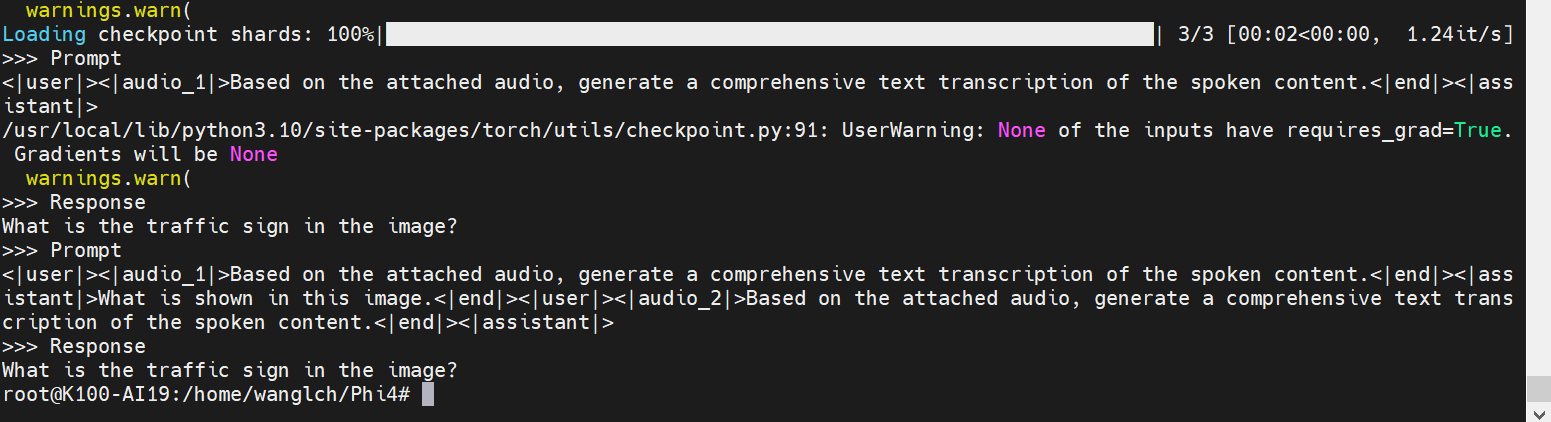
## result
- 文本推理
- 图片推理
- 音频推理
### 精度
无
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`科研,教育,政府,金融`
## 预训练权重
[microsoft/Phi-4-multimodal-instruct](https://huggingface.co/microsoft/Phi-4-multimodal-instruct)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/phi-4-multimodal-instruct_pytorch
## 参考资料
- https://github.com/microsoft/PhiCookBook
- https://huggingface.co/microsoft/Phi-4-multimodal-instruct