
particle
Showing
models/ParT_full.pt
0 → 100644
File added
models/ParT_kin.pt
0 → 100644
File added
models/ParT_kinpid.pt
0 → 100644
File added
models/ParticleNet_full.pt
0 → 100644
File added
models/ParticleNet_kin.pt
0 → 100644
File added
models/ParticleNet_kinpid.pt
0 → 100644
File added
networks/example_PCNN.py
0 → 100644
networks/example_PFN.py
0 → 100644
notebooks/JetClass101.ipynb
0 → 100644
readme_imgs/alg.png
0 → 100644
{kind=link}
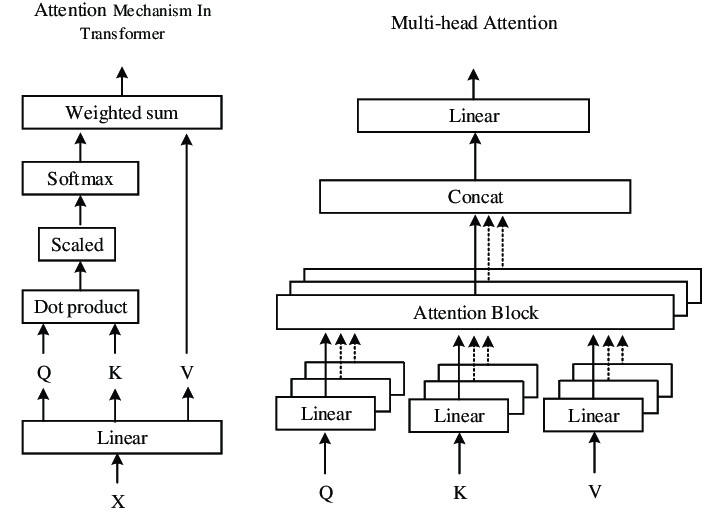
28.7 KB
readme_imgs/arch.png
0 → 100644
{kind=link}
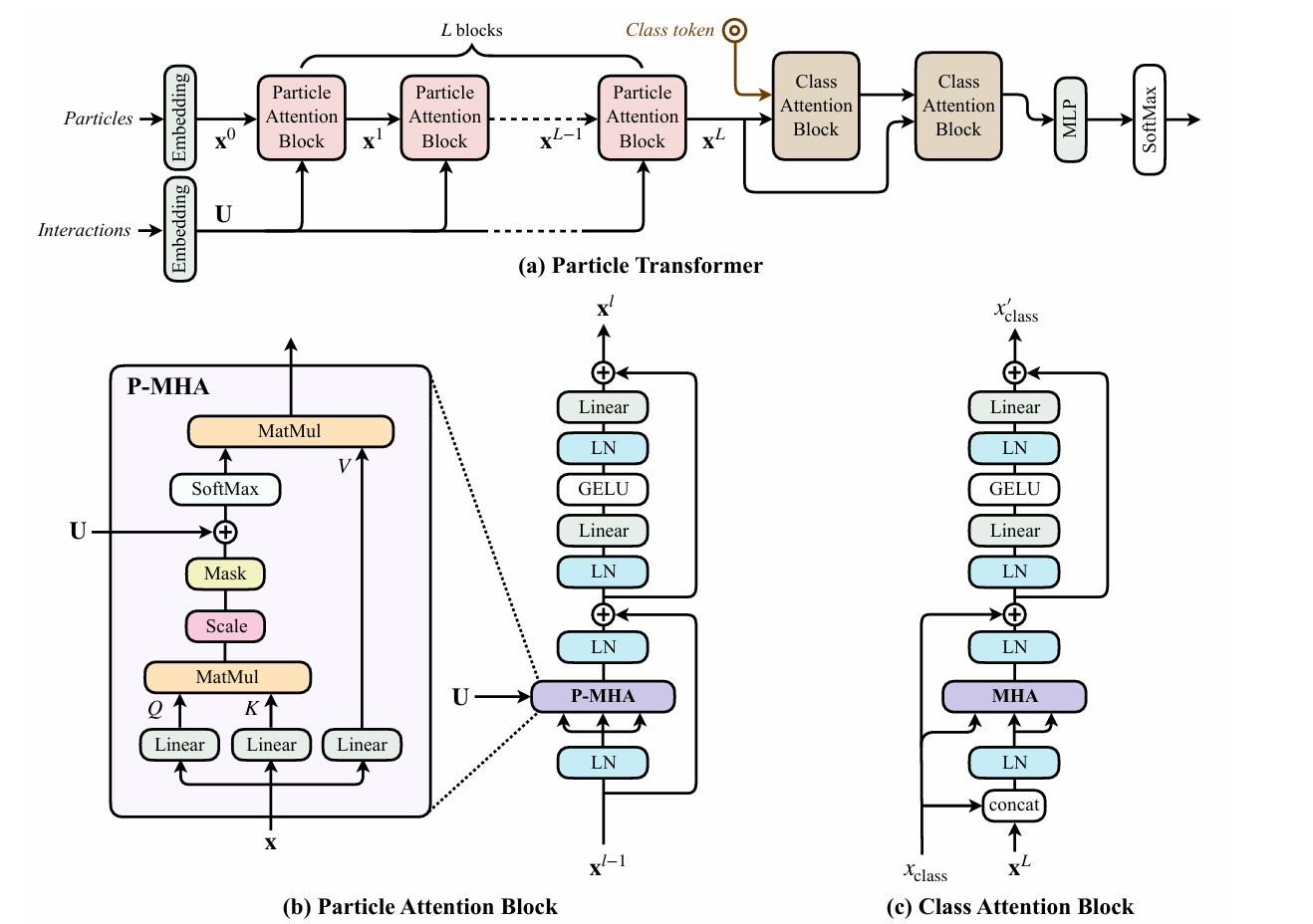
128 KB
readme_imgs/result.png
0 → 100644
{kind=link}
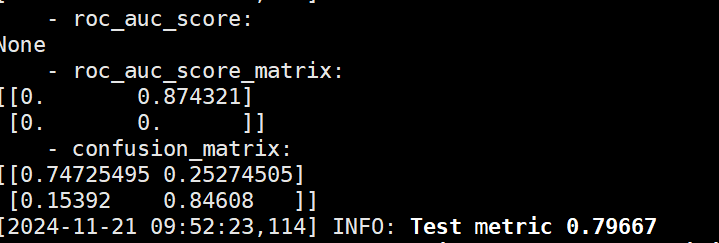
15.6 KB
test_QuarkGluon_demo.sh
0 → 100644
train_JetClass.sh
0 → 100755
train_QuarkGluon.sh
0 → 100755
train_TopLandscape.sh
0 → 100755