# Paraformer_FunASR_pytorch
## 论文
Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition
- https://arxiv.org/abs/2206.08317#
## 模型结构
虽然基于Transformer的ASR模型能产生较为良好的性能,但是鉴于传统的自回归(AR)解码效率很低。为加快推理速度,Paraformer模型设计了非自回归(NAR)方法,以实现并行生成tokens。Paraformer模型结构如图所示:
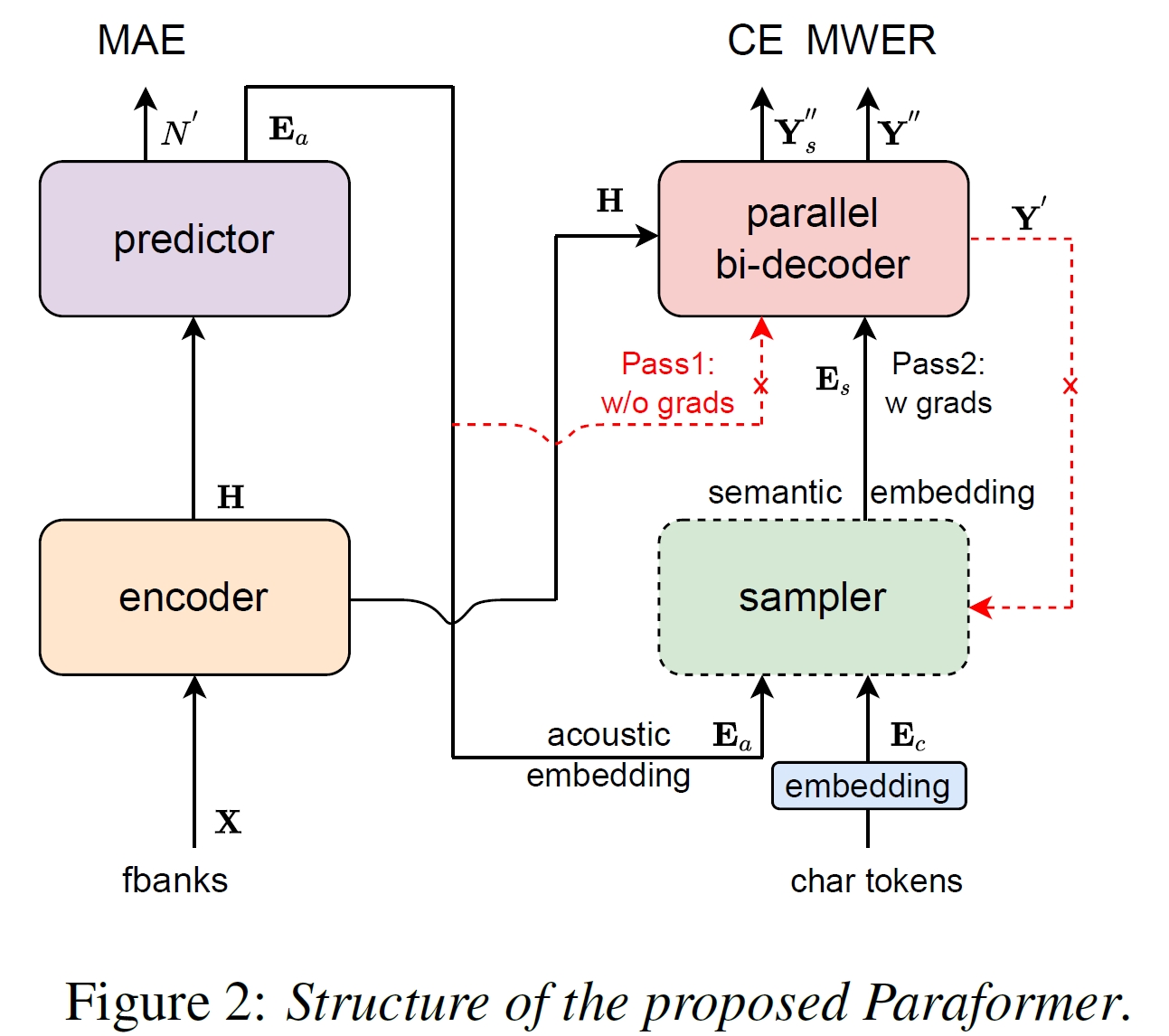
## 算法原理
为了解决自回归解码效率较低的问题,Paraformer的作者提出了如下的解决方案:
- 采用一个预测器(Predictor)来预测文字个数并通过Continuous integrate-and-fire (CIF)机制来抽取文字对应的声学隐变量。
- 受Glancing language model(GLM)启发,设计了一个基于GLM的 Sampler模块来增强模型对上下文语义的建模。
- 设计了一种生成负样本的策略来进行最小词错误率训练,以进一步提高性能。
自回归与非自回归的结构如下图所示:
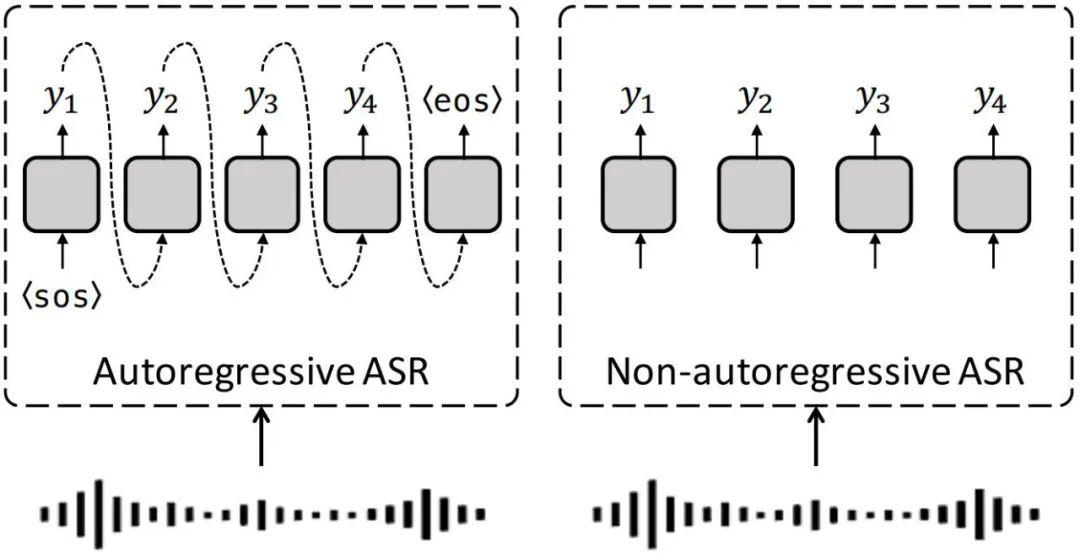
## 环境配置
### Dcoker(方法一)
此处提供[光源](https://sourcefind.cn/#main-page)拉取镜像的地址与使用步骤:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.2-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
```
### Dockerfile(方法二)
此处提供Dockerfile的使用方法:
```shell
cd ./docker
docker build --no-cache -t Paraformer:latest
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk24,04,2
Python:3.10
torch:2.1.0
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
### 安装FunASR
FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调
- pip安装
```
pip install funasr
```
- 从源代码安装
```
cd FunASR
pip3 install -e ./
```
### 推理
### No-streaming 语音识别
```
from funasr import AutoModel
# paraformer-zh is a multi-functional asr model
# use vad, punc, spk or not as you need
model = AutoModel(
model="paraformer-zh",
vad_model="fsmn-vad",
punc_model="ct-punc")
res = model.generate(input="test_audio/asr_example_zh.wav")
print(res)
```
参数说明:
- model_dir:模型名称,或本地磁盘中的模型路径。
- vad_model:表示开启VAD,VAD的作用是将长音频切割成短音频,此时推理耗时包括了VAD与SenseVoice总耗时,为链路耗时,如果需要单独测试SenseVoice模型耗时,可以关闭VAD模型。
- punc_model:针对输出文字的标点符号进行优化。
执行效果图:

### Streaming 语音识别
```
from funasr import AutoModel
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
model = AutoModel(model="paraformer-zh-streaming")
import soundfile
import os
wav_file = os.path.join(model.model_path, "test_audio/asr_example_zh.wav")
speech, sample_rate = soundfile.read(wav_file)
chunk_stride = chunk_size[1] * 960 # 600ms
cache = {}
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
for i in range(total_chunk_num):
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
is_final = i == total_chunk_num - 1
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
print(res)
```
注:chunk_size为流式延时配置,[0,10,5]表示上屏实时出字粒度为10*60=600ms,未来信息为5*60=300ms。每次推理输入为600ms(采样点数为16000*0.6=960),输出为对应文字,最后一个语音片段输入需要设置is_final=True来强制输出最后一个字。
执行效果图:
上述streaming和no-streaming推理所用到的模型可从以下网址下载:
- paraformer-zh:https://hf-mirror.com/funasr/paraformer-zh
- paraformer-zh-streaming:https://hf-mirror.com/funasr/paraformer-zh-streaming
- fsmn-vad:https://hf-mirror.com/funasr/fsmn-vad
- ct-punc:https://hf-mirror.com/funasr/ct-punc
## 应用场景
### 算法分类
语音识别
### 热点应用行业
语音识别、教育、医疗
## 源码仓库及问题反馈
https://developer.hpccube.com/codes/modelzoo/paraformer_funasr_pytorch
## 参考资料
https://github.com/modelscope/FunASR