# Ovis
## 论文
Ovis: Structural Embedding Alignment for Multimodal Large Language Model
https://arxiv.org/abs/2405.20797
## 模型结构
Ovis (Open VISion) 是一种新颖的多模态大型语言模型 (MLLM) 架构,旨在结构化地对齐视觉和文本嵌入。Ovis借鉴了大语言模型中的文本嵌入策略,引入了可学习的视觉嵌入表,将连续的视觉特征先转换为概率化的视觉token,再经由视觉嵌入表多次索引加权得到结构化的视觉嵌入。
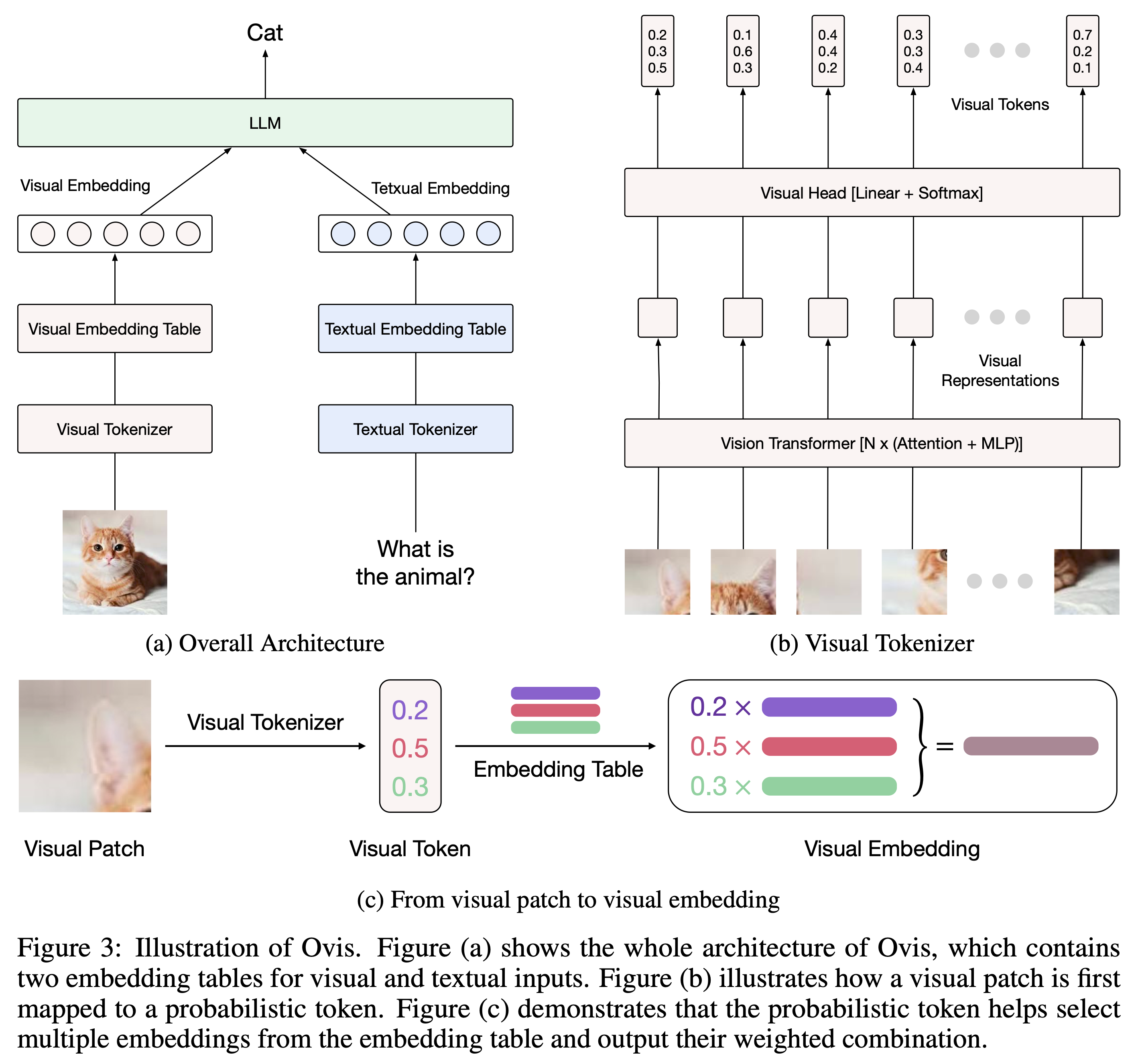
## 算法原理
如上图所示,Ovis通过设计一种新的多模态架构,将视觉和文本信息融合在同一个嵌入空间中。这意味着模型能够学习到如何将图片和文本的信息统一映射到相同的向量表示,这种对齐的目的是为了在视觉和文本之间实现更好的交互和信息传递。视觉嵌入通常通过视觉编码器(例如CLIP、ViT)生成,文本嵌入通过LLM(如GPT、BERT)生成,Ovis则通过特殊的对齐层或映射模块进行对齐。
与传统简单的多模态对齐不同,Ovis特别强调视觉和文本嵌入的结构性对齐。这种对齐不仅仅是将两种模态映射到同一向量空间,而是保留了每种模态特有的结构信息。例如,文本的语法结构和图像的空间信息会在对齐过程中保持,以确保模型在进行推理时能够利用这些结构性信息。
Ovis模型采用层次化的多模态融合策略,这意味着视觉和文本信息的交互在多个层次上进行。不同的层次负责捕捉不同的语义信息,从低层的局部特征到高层的全局语义。这样能够确保模型在处理复杂多模态任务时,有足够的表达能力来捕捉模态间的细微差异和关联。
Ovis引入了指令微调技术,通过给模型提供明确的任务指令,帮助其更好地理解不同任务需求,并在推理过程中实现更强的通用性。结合DPO(Direct Preference Optimization)训练方法,模型能够通过对比学习更精细地优化多模态任务中的决策,提升推理效果。
为了提高模型的泛化能力,Ovis在训练过程中采用了大量多样化的数据,包括高分辨率图像、不同领域的文本描述以及细粒度的视觉特征。这种多样化数据的使用,帮助模型在面对不同模态和领域的任务时都能表现出较强的适应能力。
## 环境配置
### Docker(方法一)
推荐使用docker方式运行, 此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name ovis_pytorch bash # 为以上拉取的docker的镜像ID替换,本镜像为:a4dd5be0ca23
cd /path/your_code_data/
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install --no-deps -e .
cd VLMEvalKit
pip install e .
```
Tips:以上dtk驱动、python、torch、vllm等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
docker build -t ovis:latest .
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name ovis_pytorch ovis bash
cd /path/your_code_data/
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install --no-deps -e .
cd VLMEvalKit
pip install e .
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.1
python:3.10
torch:2.1.0
deepspeed:0.12.3
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirement.txt安装:
```
cd /path/your_code_data/
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install --no-deps -e .
cd VLMEvalKit
pip install e .
```
## 数据集
多模态精度评估可使用VLMEvalKit库进行测试,测试运行时会自动下载MMStar、OCRBench、AID2、HallusionBench等数据,
默认路径为/root/LMUData。
精度评估数据目录结构如下:
```
── LMUData
├── AI2D_TEST.tsv
├── MMStar.tsv
├── OCRBench.tsv
└── ...
```
## 训练
官方暂未提供
## 推理
infer:
```
#注意:根据自己的模型切换文件中的模型位置并调整其他参数
cd /path/your_code_data/
python ovis/serve/runner.py
```
根据自己的要求输入image和text。
eval:
若使用本地下载好的模型权重,注意修改VLMEvalKit/vlmeval/vlm/config.py文件中以下代码行中的model_path为自己的本地模型地址
'Ovis1.6-Gemma2-9B': partial(Ovis1_6, model_path='AIDC-AI/Ovis1.6-Gemma2-9B')
```
cd VLMEvalKit
python run.py --data MMStar AI2D_TEST OCRBench HallusionBench --model Ovis1.6-Gemma2-9B --verbose
```
## result
使用的加速卡:1张 K100_AI 模型:Ovis1.6-Gemma2-9B
输入:
image :
text:
'Please describe this image'
output:
### 精度
使用的加速卡:1张 K100_AI 模型:Ovis1.6-Gemma2-9B
| MLLM | AI2D | OCRBench | MMStar | HallusionBench |
|------------|------|----------|--------|----------------|
| Ovis1.6-Gemma2-9B | 84.6 | 82.6 | 62.1 | 67.7 |
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`科研,教育,政府,金融`
## 预训练权重
模型Huggingface下载链接[Ovis1.6-Gemma2-9B|HF](https://huggingface.co/AIDC-AI/Ovis1.6-Gemma2-9B)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/ovis_pytorch
## 参考资料
- https://github.com/AIDC-AI/Ovis
- https://github.com/open-compass/VLMEvalKit

