
open_clip
Showing
.gitattributes
0 → 100755
.github/workflows/ci.yml
0 → 100755
.gitignore
0 → 100755
CITATION.cff
0 → 100755
Dockerfile
0 → 100644
HISTORY.md
0 → 100755
LICENSE
0 → 100755
MANIFEST.in
0 → 100755
Makefile
0 → 100755
README.md
0 → 100755
README_official.md
0 → 100755
This diff is collapsed.
custom_tests/simple_test.py
0 → 100755
docs/CLIP.png
0 → 100755
{kind=link}
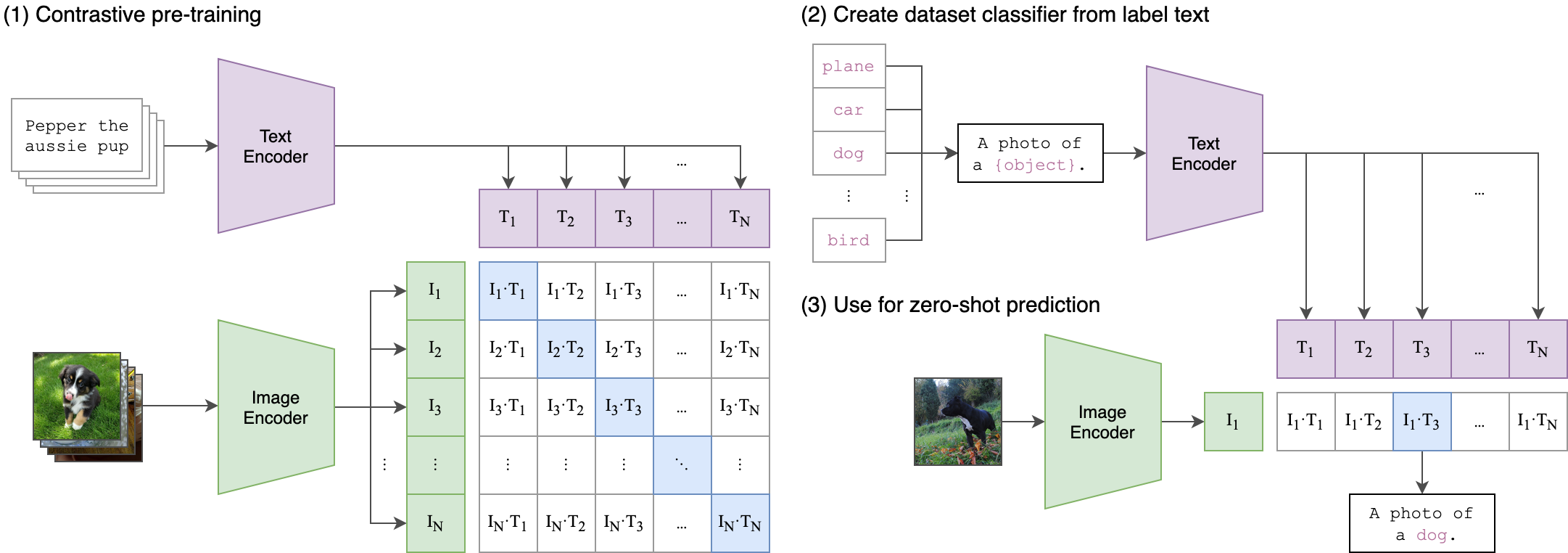
247 KB
This diff is collapsed.
This diff is collapsed.
docs/LOW_ACC.md
0 → 100755
docs/PRETRAINED.md
0 → 100755