
open_clip
Showing
This source diff could not be displayed because it is too large. You can view the blob instead.
docs/openclip_results.csv
0 → 100755
This diff is collapsed.
This diff is collapsed.
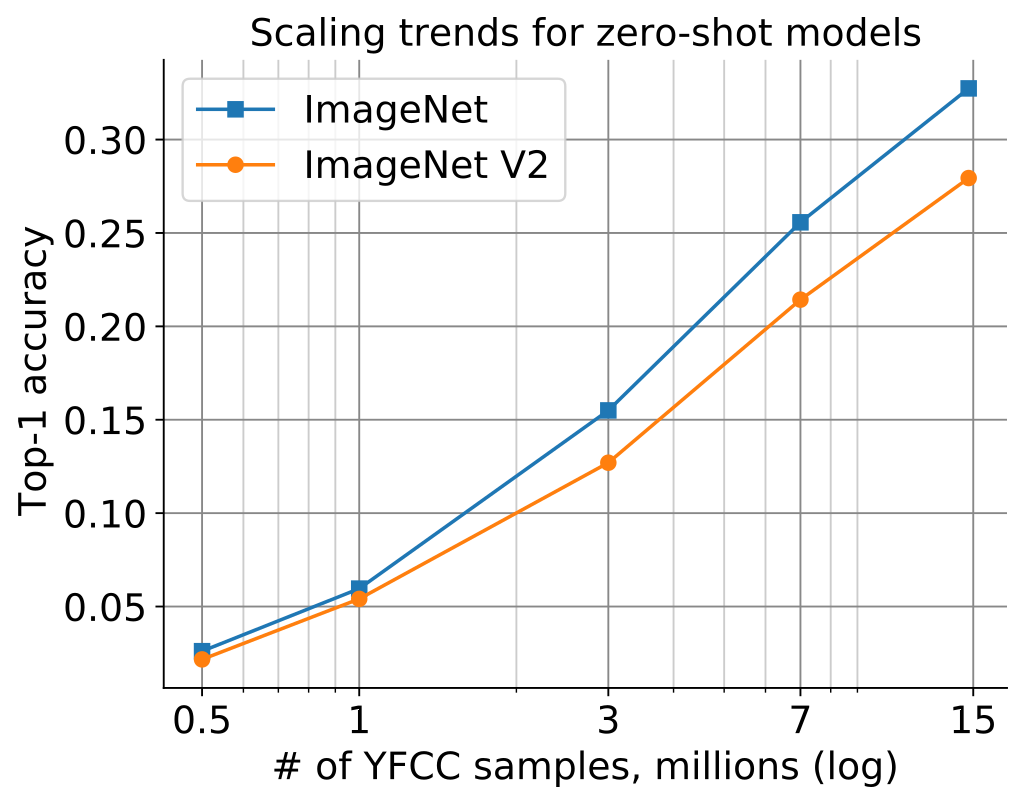
docs/scaling.png
0 → 100755
{kind=link}
96.4 KB
extra_utils/coca_data.py
0 → 100644
extra_utils/valprep.sh
0 → 100755
This diff is collapsed.
model.properties
0 → 100644
pyproject.toml
0 → 100755
pytest.ini
0 → 100755