
open_clip
Showing
docs/clip_loss.png
0 → 100755
{kind=link}
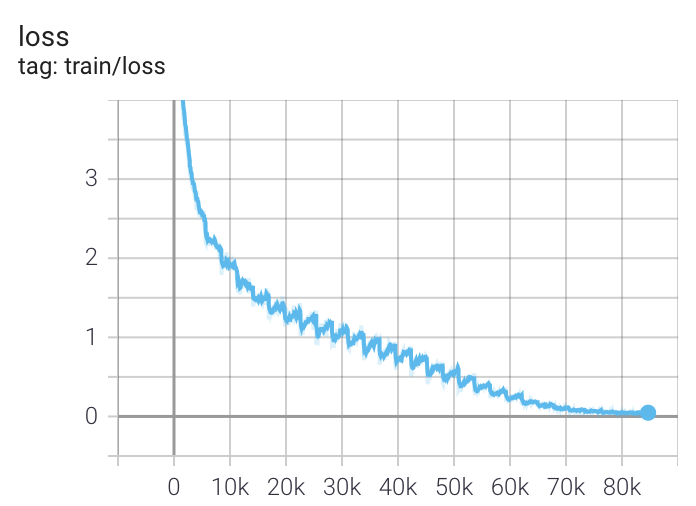
41.9 KB
docs/clip_recall.png
0 → 100755
{kind=link}
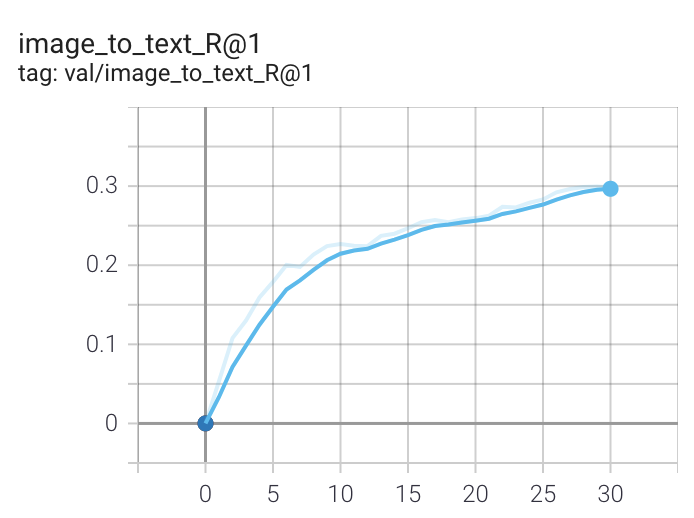
49.6 KB
docs/clip_val_loss.png
0 → 100755
{kind=link}
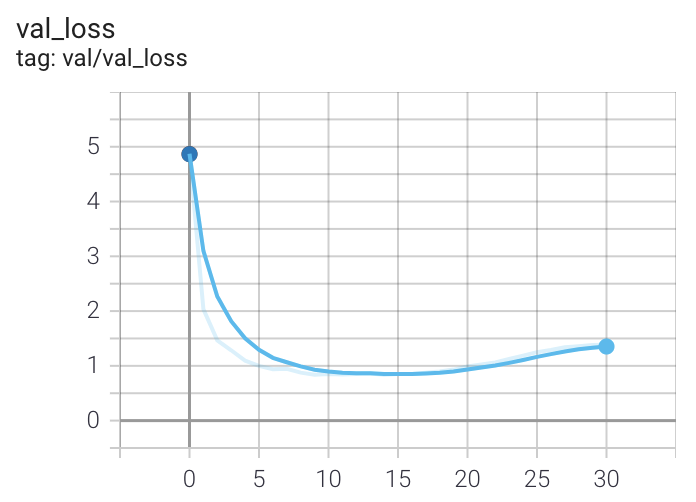
42.8 KB
docs/clip_zeroshot.png
0 → 100755
{kind=link}
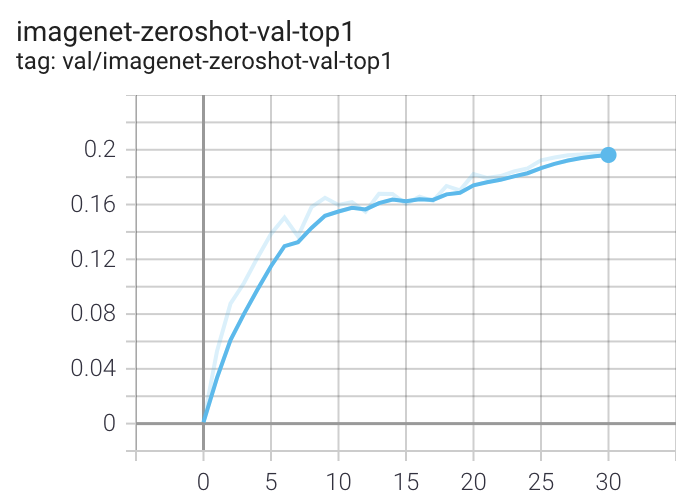
57.1 KB
docs/clipa.md
0 → 100755
docs/clipa_acc_compute.png
0 → 100755
{kind=link}
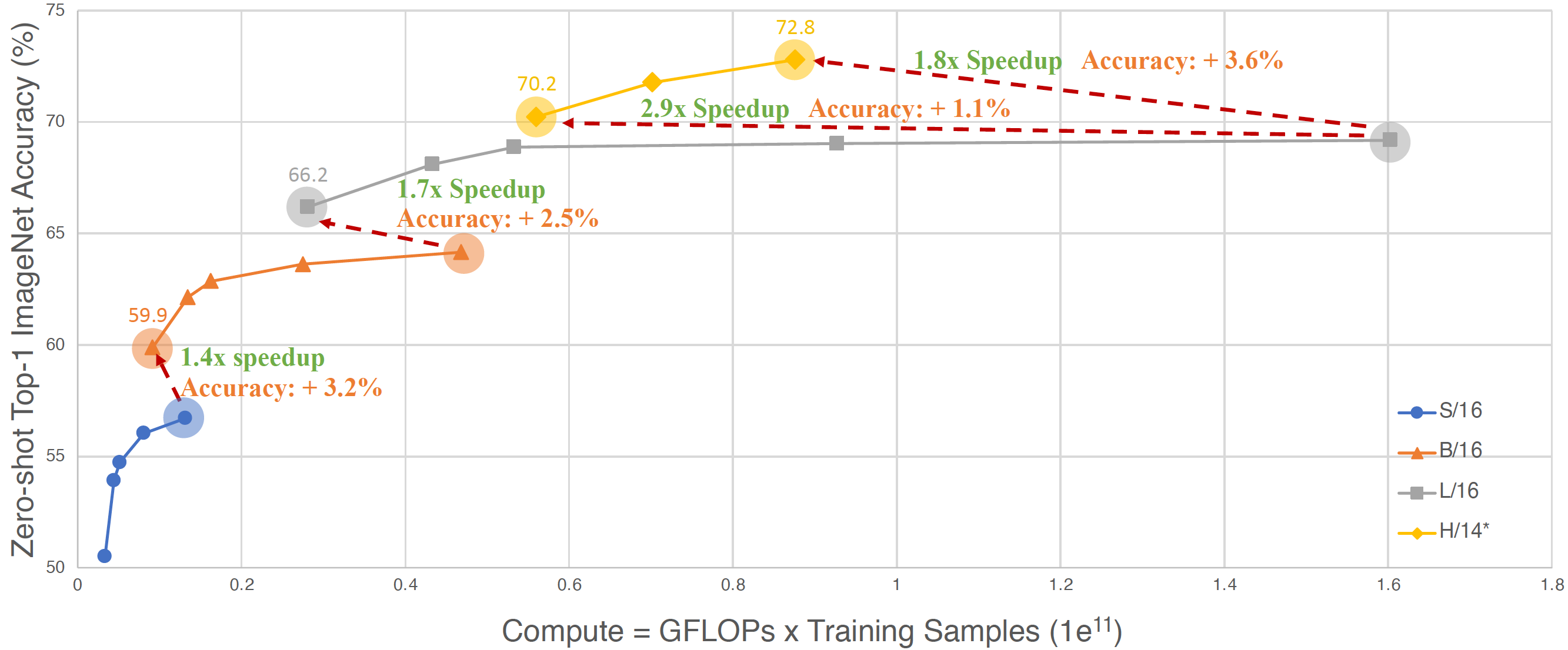
255 KB
{kind=link}

1.04 MB
{kind=link}
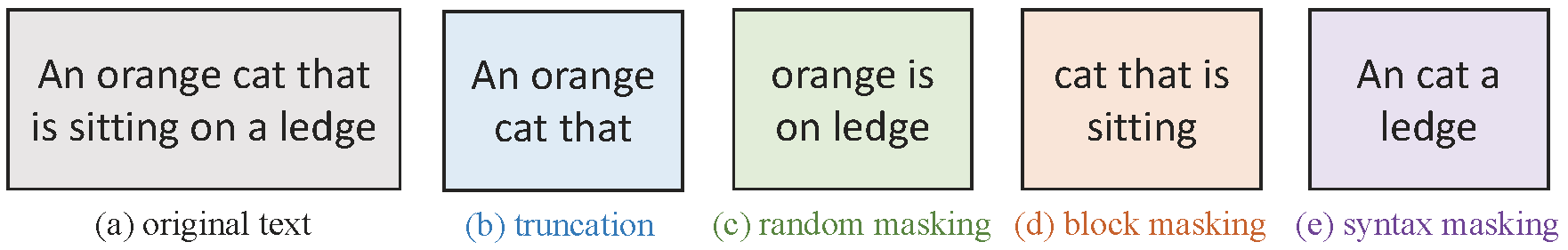
15.7 KB
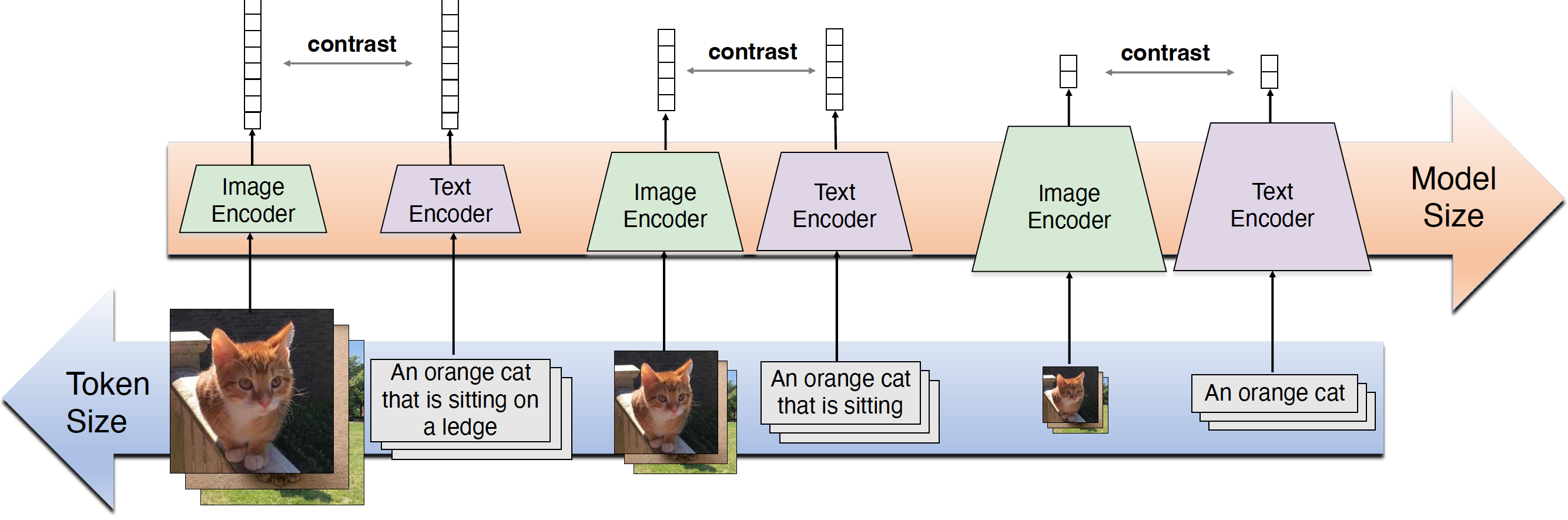
docs/datacomp_models.md
0 → 100755
{kind=link}
995 KB
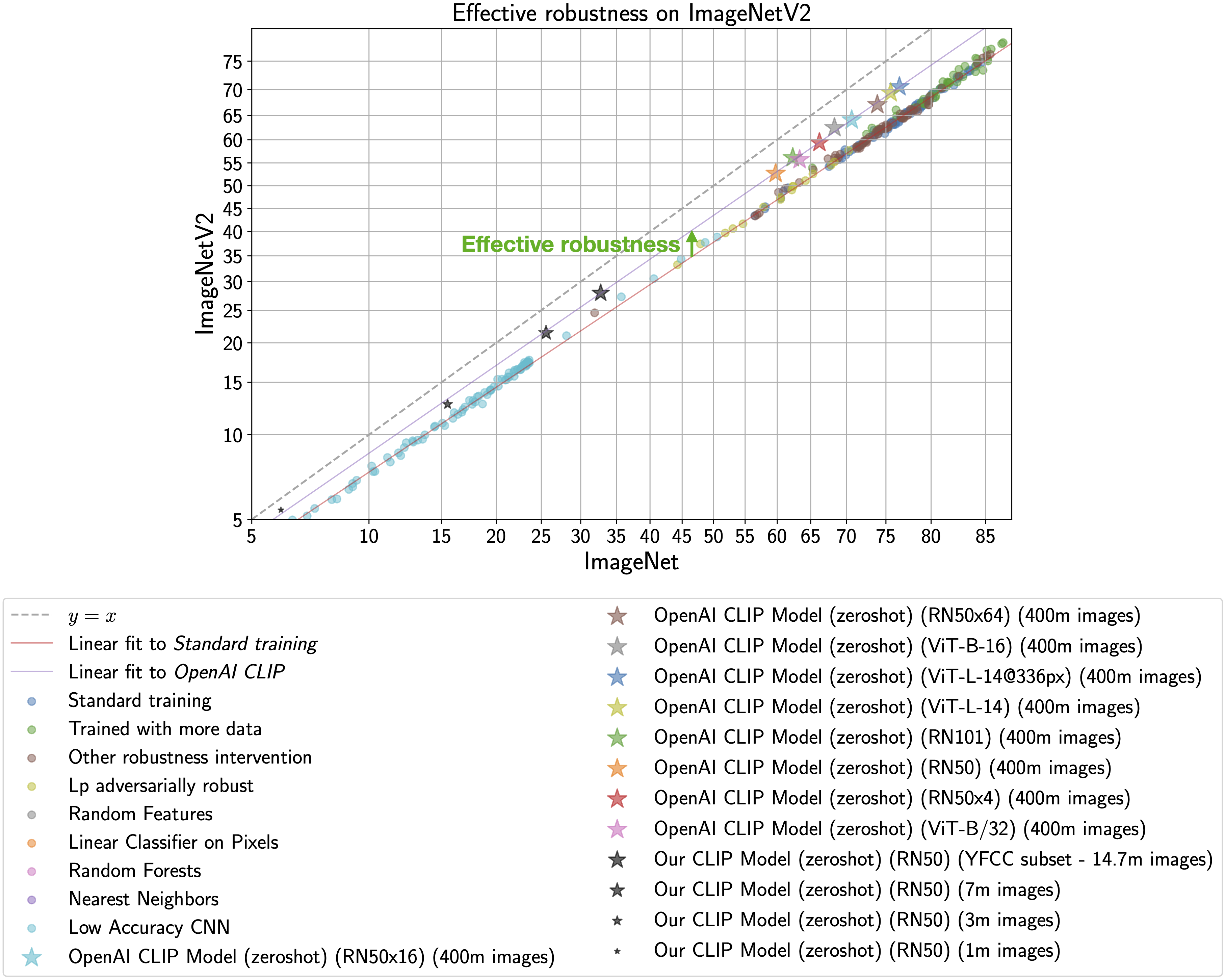
docs/inverse_scaling_law.png
0 → 100755
{kind=link}
583 KB
{kind=link}
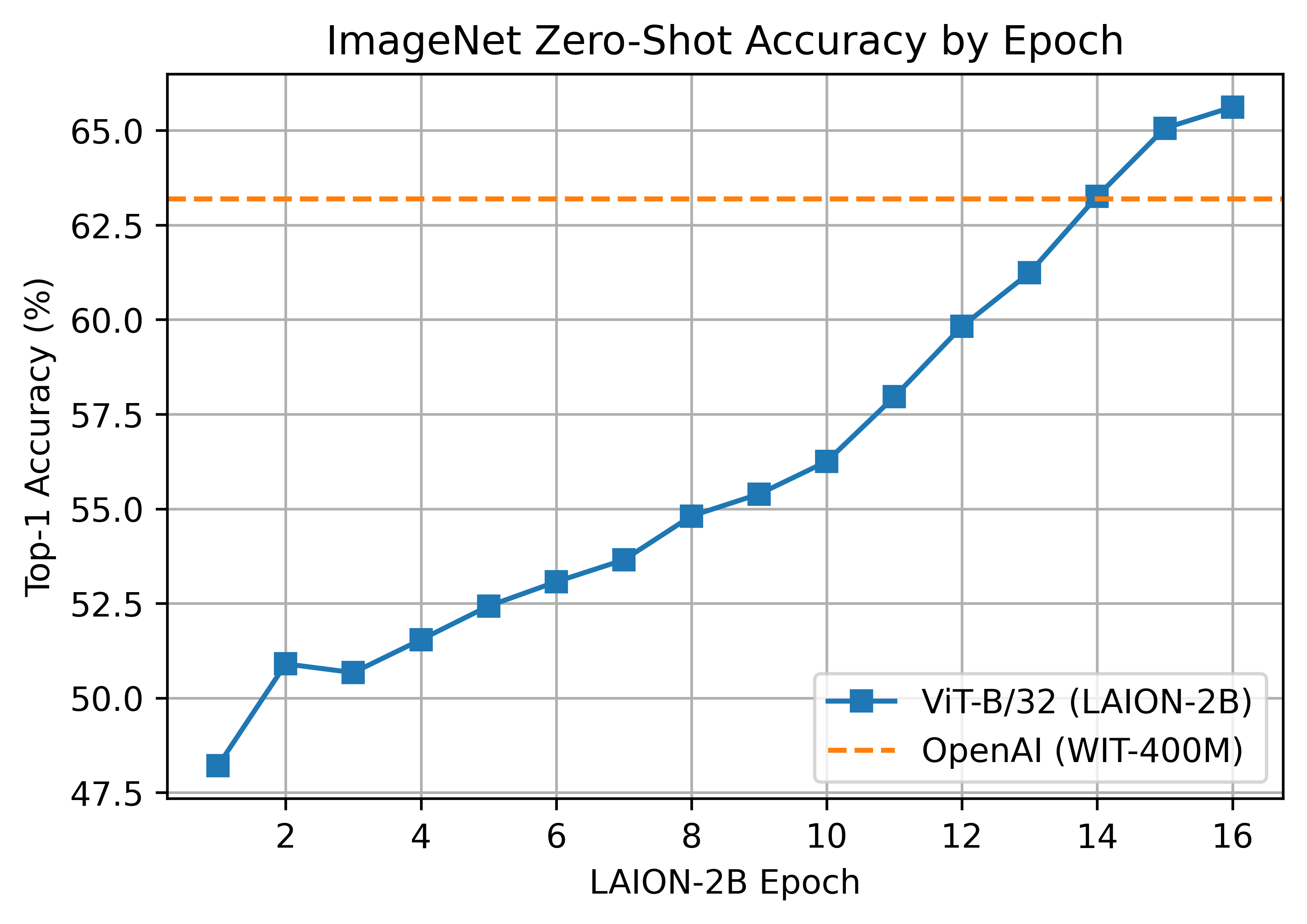
240 KB
docs/laion_clip_zeroshot.png
0 → 100755
{kind=link}
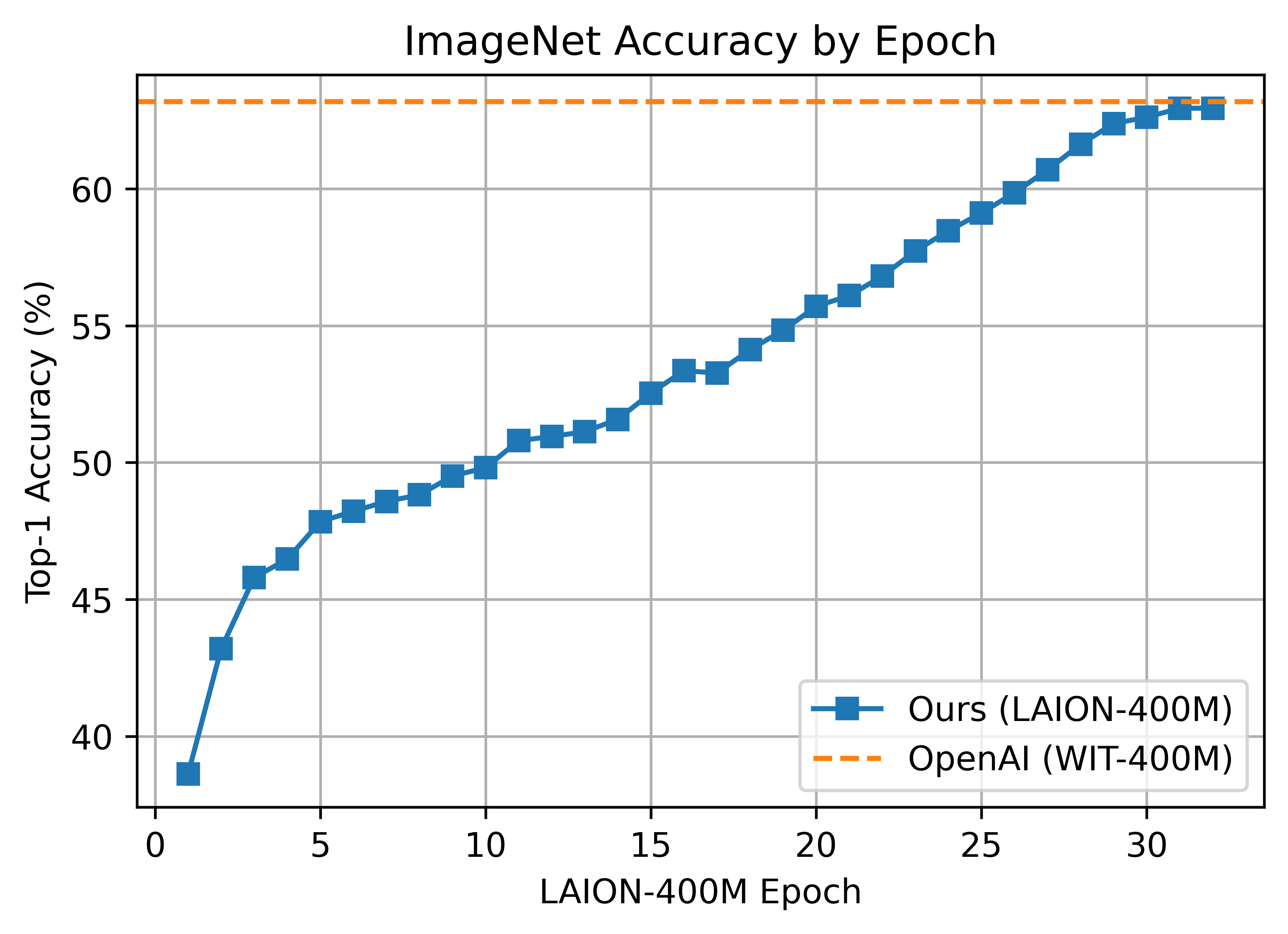
191 KB
{kind=link}
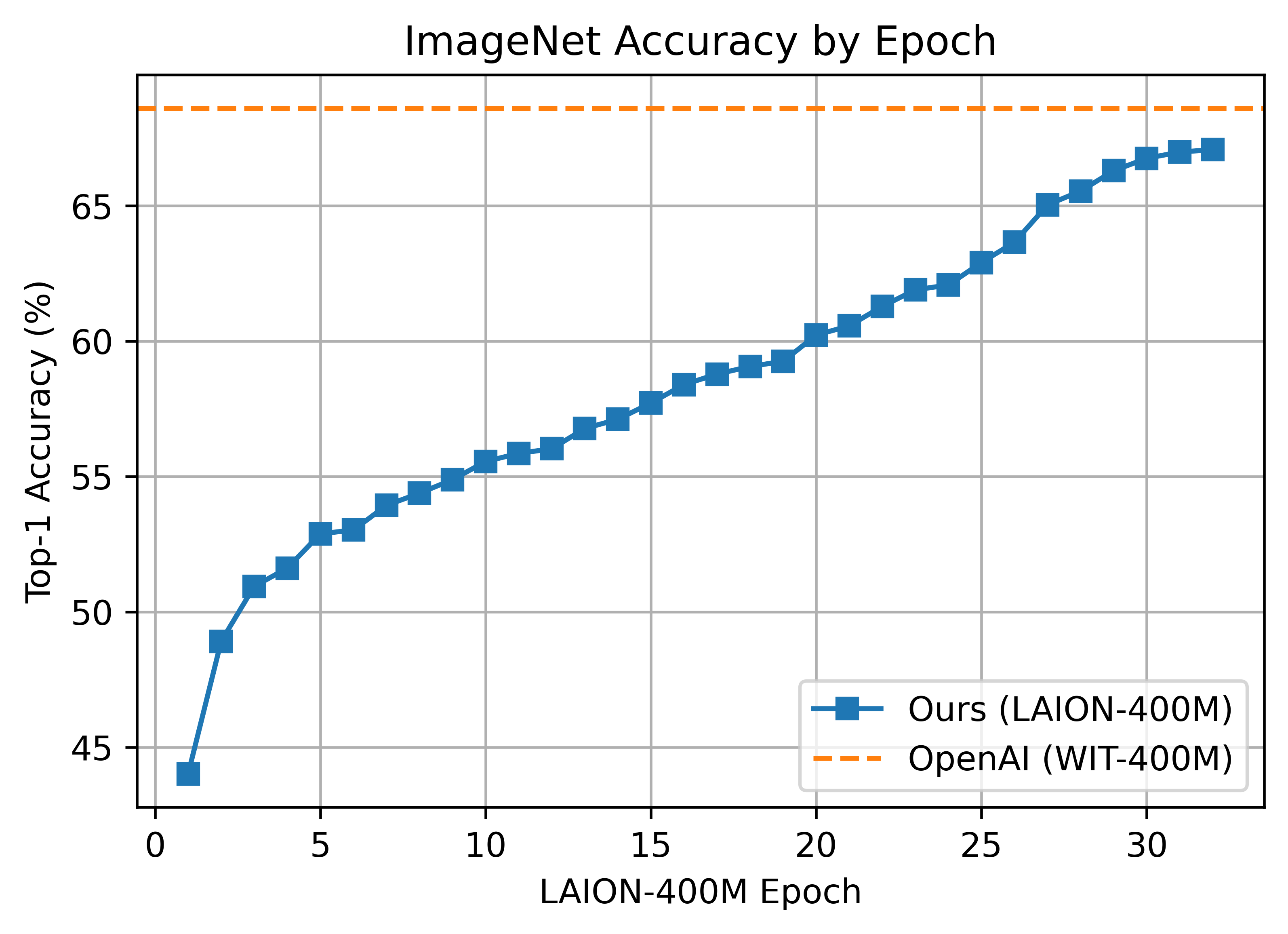
191 KB
{kind=link}

249 KB
{kind=link}
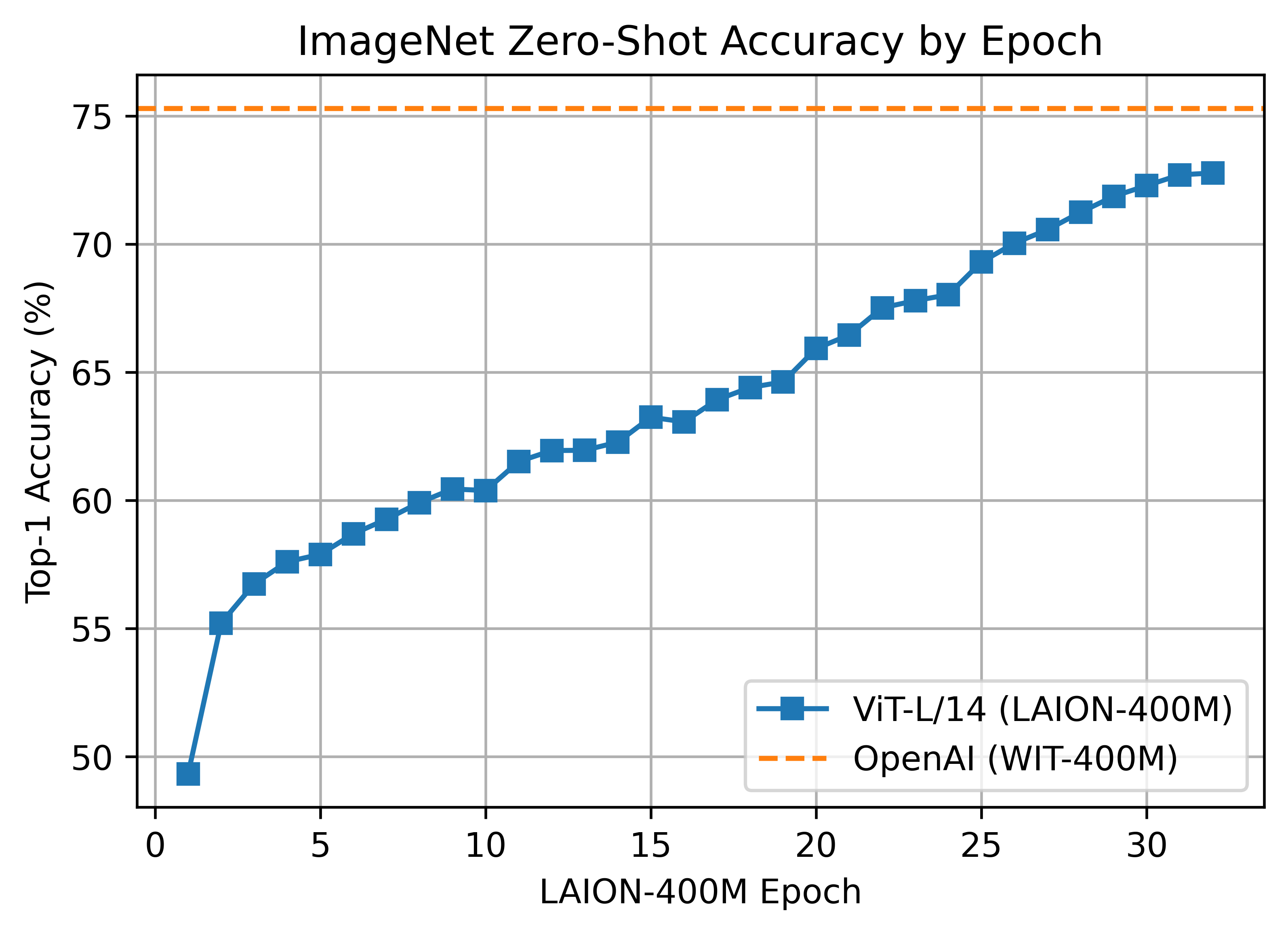
199 KB
{kind=link}
58.1 KB
docs/model_profile.csv
0 → 100755
This diff is collapsed.