
open_sora_inference
Showing
opensora/utils/misc.py
0 → 100755
readme_imgs/image-1.png
0 → 100755
{kind=link}
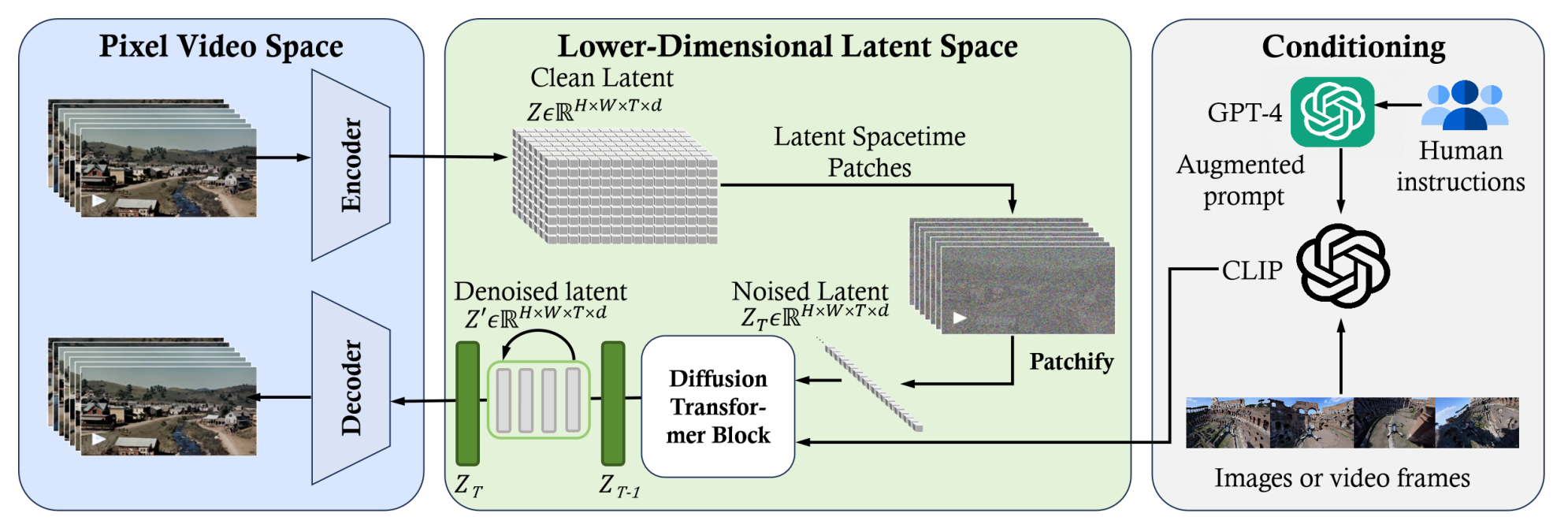
647 KB
readme_imgs/image-2.png
0 → 100755
{kind=link}
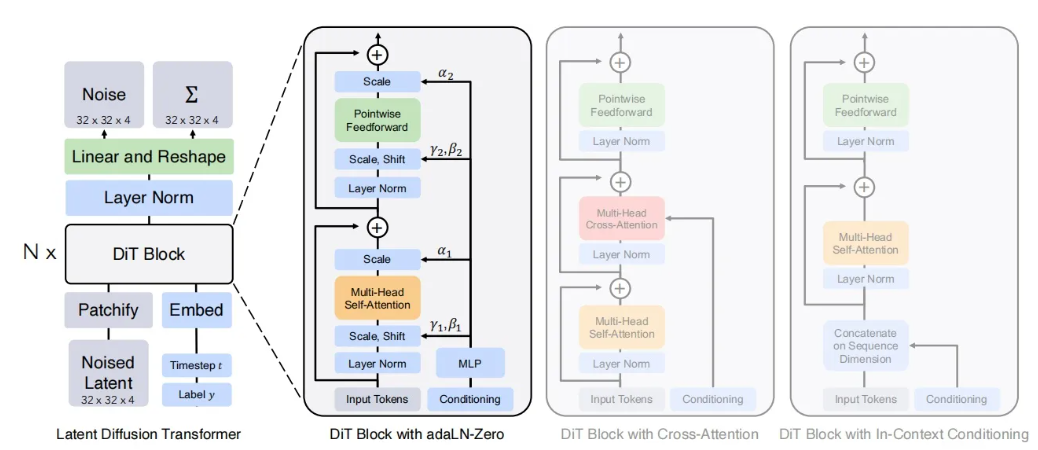
265 KB
readme_imgs/r0.gif
0 → 100644
{kind=link}

483 KB
readme_imgs/r1.gif
0 → 100644
{kind=link}

380 KB
readme_imgs/r2.gif
0 → 100644
{kind=link}

291 KB
readme_imgs/r3.gif
0 → 100644
{kind=link}

282 KB
readme_imgs/r4.gif
0 → 100644
{kind=link}

380 KB
requirements.txt
0 → 100755
| colossalai | ||
| accelerate | ||
| diffusers==0.24.0 | ||
| ftfy | ||
| gdown | ||
| mmengine==0.10.0 | ||
| pre-commit==3.3.2 | ||
| # pyav | ||
| av==11.0.0 | ||
| pyav2==0.0.2 | ||
| tensorboard | ||
| timm | ||
| tqdm | ||
| transformers | ||
| wandb | ||
| sentencepiece |
scripts/inference.py
0 → 100755
scripts/train.py
0 → 100755
setup.py
0 → 100755
tests/test_t5_shardformer.py
0 → 100755
tools/__init__.py
0 → 100755
tools/caption/README.md
0 → 100755
tools/caption/__init__.py
0 → 100755