# olmOCR
## 论文
[olmOCR: Unlocking Trillions of Tokens in PDFswithVisionLanguageModels](https://olmocr.allenai.org/papers/olmocr.pdf)
## 模型简介
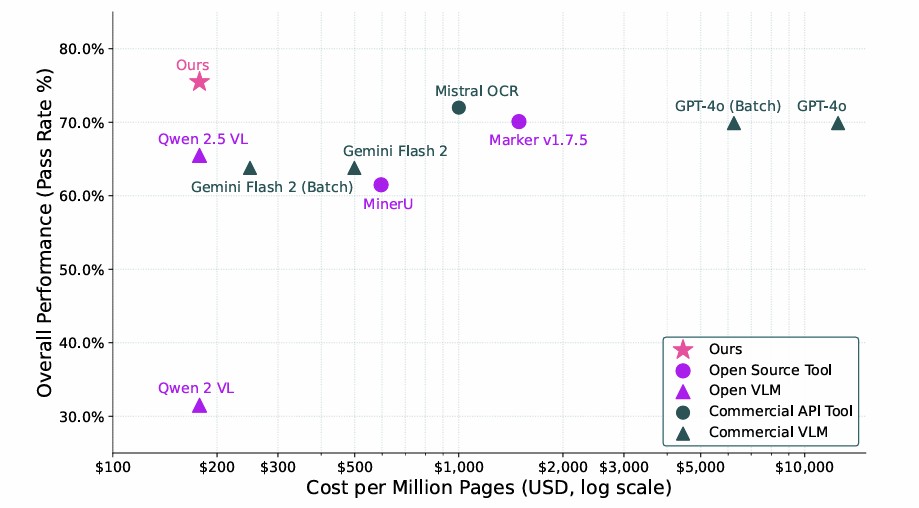
这是一个olmOCR模型的发布版本,它基于Qwen2.5-VL-7B-Instruct模型,并使用olmOCR-mix-1025数据集进行了微调。此外,该模型还采用了GRPO强化学习训练,以提升其在数学公式、表格以及其他复杂OCR场景下的性能。olmOCR与一系列用于PDF线性化和内容提取的方法在性能与成本方面的对比如下:
## 环境依赖
| 软件 | 版本 |
| :------: | :------: |
| DTK | 26.04 |
| python | 3.10.12 |
| torch | 2.5.1+das.opt1.dtk2604 |
| transformers | 4.57.6 |
| vllm | 0.11.0+das.opt1.rc4.dtk2604 |
推荐使用镜像: harbor.sourcefind.cn:5443/dcu/admin/base/vllm:0.11.0-ubuntu22.04-dtk26.04-py3.10
- 挂载地址`-v`根据实际模型情况修改
```bash
docker run -it \
--shm-size 200g \
--network=host \
--name olmOCR \
--privileged \
--device=/dev/kfd \
--device=/dev/dri \
--device=/dev/mkfd \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
-u root \
-v /opt/hyhal/:/opt/hyhal/:ro \
-v /path/your_code_data/:/path/your_code_data/ \
harbor.sourcefind.cn:5443/dcu/admin/base/vllm:0.11.0-ubuntu22.04-dtk26.04-py3.10 bash
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
## 数据集
`暂无`
## 训练
`暂无`
## 推理
### vllm
#### 单机推理
```bash
## serve启动
vllm serve allenai/olmOCR-2-7B-1025-FP8/ --trust-remote-code -tp 1 --port 8010
## client访问
curl -X POST "http://localhost:8010/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "allenai/olmOCR-2-7B-1025-FP8/",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe this image in one sentence."
},
{
"type": "image_url",
"image_url": {
"url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"
}
}
]
}
]
}'
```
## 效果展示
### 精度
`DCU与GPU精度一致,推理框架:vllm。`
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 |下载地址|
|:-----:|:----------:|:----------:|:---------------------:|:----------:|
| olmOCR-2-7B-1025-FP8 | 7B | BW1100 | 1 | [Hugging Face](https://huggingface.co/allenai/olmOCR-2-7B-1025-FP8) |
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/olmocr_vllm
## 参考资料
- https://github.com/allenai/olmocr