# olmocr
## 论文
[olmOCR: Unlocking Trillions of Tokens
in PDFswithVisionLanguageModels](https://olmocr.allenai.org/papers/olmocr.pdf)
## 模型结构
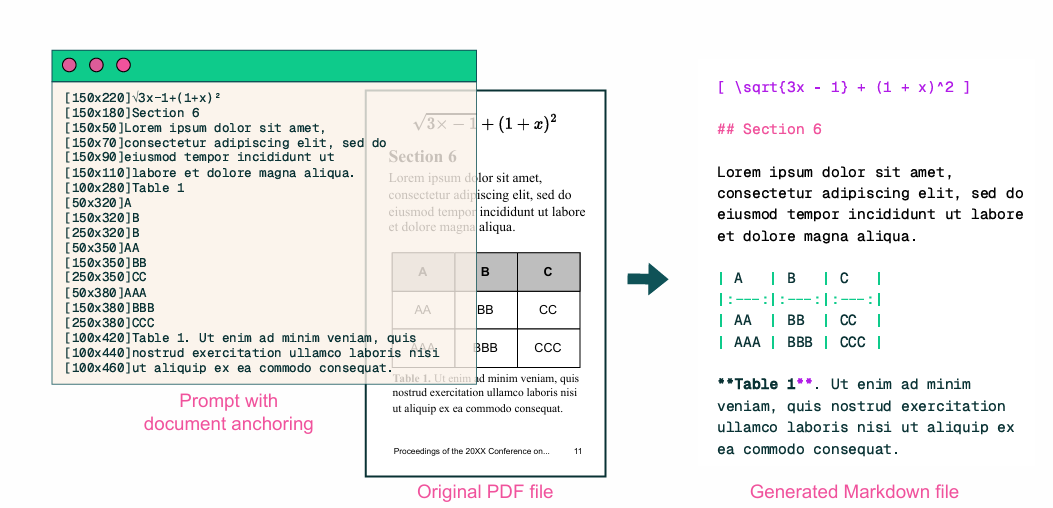
olmOCR结合文档锚定(document-anchoring)技术与Qwen2-VL-7B-Instruct(阿里多模态模型),支持处理多种类型的PDF文档,包括学术论文、书籍、表格和图表等。olmOCR基于提取文档中的文本和布局信息,与页面图像结合,更准确地提取内容、保留结构化信息。
## 算法原理
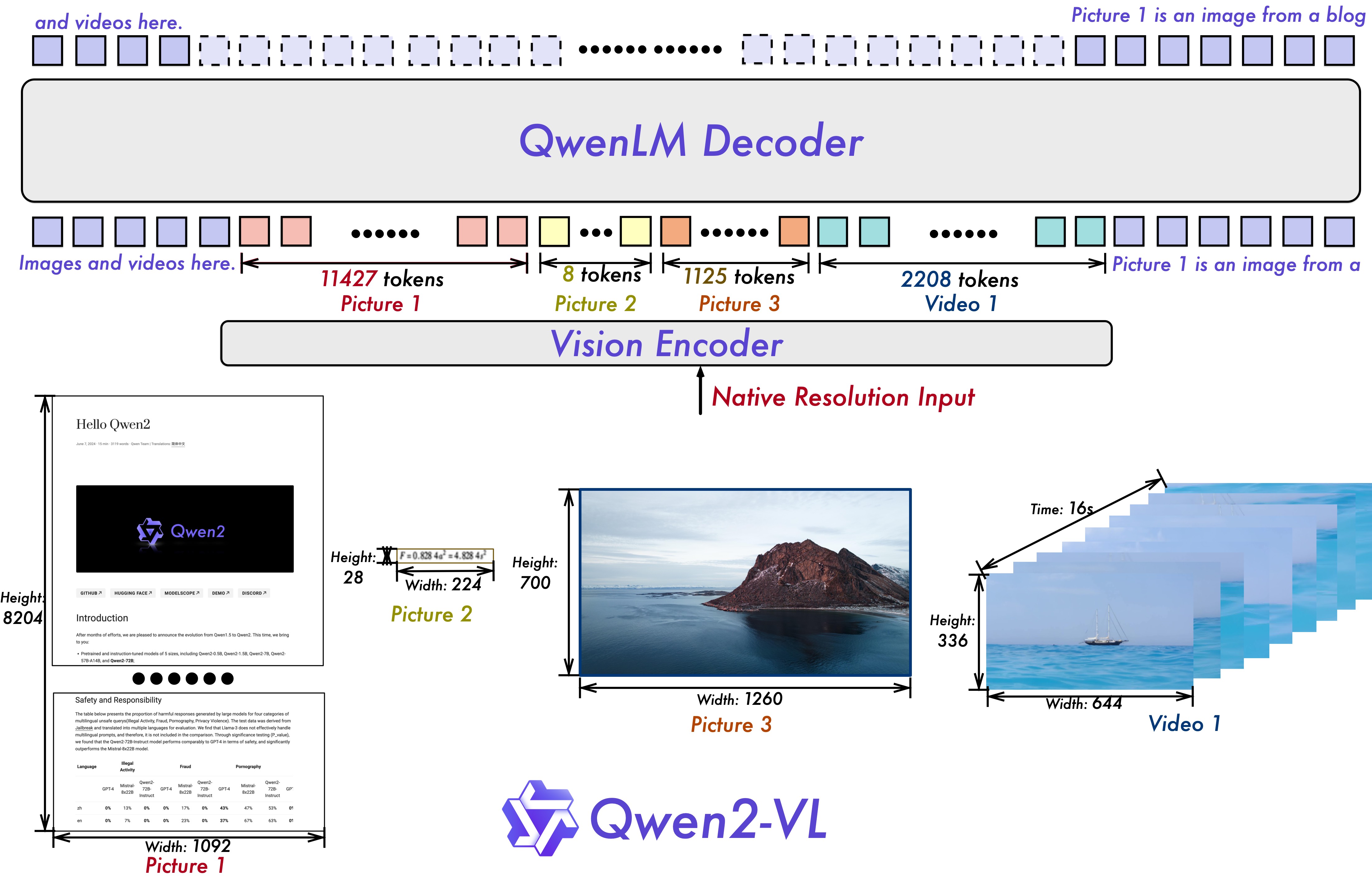
* 文档锚定(Document-anchoring):基与提取PDF页面中的文本块和图像的位置信息,与原始文本结合,形成提示(prompt)。提示与页面的栅格化图像一起输入到视觉语言模型(VLM)中。帮助模型更好地理解文档的结构和布局,减少因图像模糊或布局复杂导致的提取错误。
* 微调的视觉语言模型(VLM):基于Qwen2-VL-7B-Instruct的7B参数视觉语言模型。在包含26万页PDF的数据集上进行微调,适应文档处理任务。模型输出结构化的JSON数据,包含页面的元数据(如语言、方向、是否包含表格等)和自然阅读顺序的文本内容。
## 环境配置
### Docker(方法一)
推荐使用docker方式运行, 此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-py3.10-dtk24.04.3-ubuntu20.04
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name olmocr bash # 为以上拉取的docker的镜像ID替换
cd /path/your_code_data/
sudo apt-get update
sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools
pip install olmocr
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
pip unintall torchvision
pip install torchvision
```
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
docker build -t olmocr:latest .
docker run --shm-size 500g --network=host --name=olmocr --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
sudo apt-get update
sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools
cd /path/your_code_data/
pip install olmocr
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
pip unintall torchvision
pip install torchvision
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.3
python:3.10
torch:2.6.0
flash-attn:2.6.1
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirement.txt安装:
```
conda create -n olmocr python=3.10
conda activate olmocr
sudo apt-get update
sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools
cd /path/your_code_data/
pip install olmocr
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
pip unintall torchvision
pip install torchvision
```
## 数据集
```
无
```
## 训练
```
无
```
## 推理
```
python olmocr_ocr.py
```
## result
### 精度
无
## 应用场景
### 算法类别
`OCR`
### 热点应用行业
`科研,教育,政府,金融`
## 预训练权重
预训练权重快速下载中心: [SCNet AIModels](https://www.scnet.cn/ui/aihub/models)
项目中的预训练权重可从快速下载通道下载:[allenai/olmOCR-7B-0225-preview](https://www.scnet.cn/ui/aihub/models/openaimodels/olmOCR-7B-0225-preview/files/tree/main/)
[ModelScope](https://modelscope.cn/)
[allenai/olmOCR-7B-0225-preview](https://www.modelscope.cn/models/allenai/olmOCR-7B-0225-preview)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/olmocr_pytorch
## 参考资料
- https://github.com/allenai/olmocr