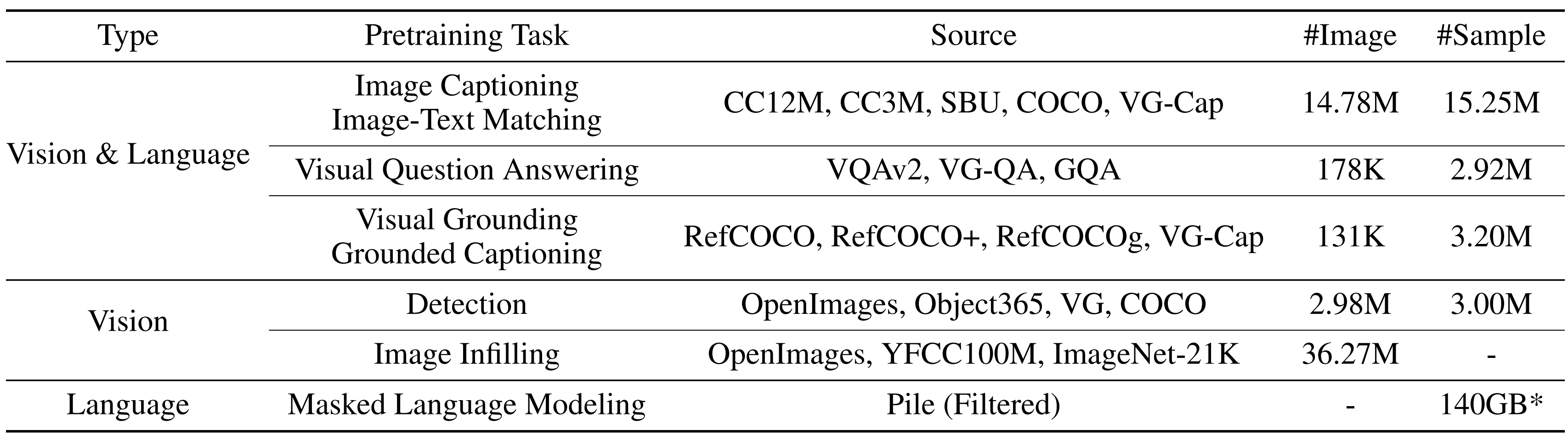
# OFA
本项目的原理、步骤适用于OFA中的Image Captioning算法,OFA项目中的其它算法使用方法类似。
## 论文
`OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework`
- https://arxiv.org/pdf/2202.03052.pdf
## 模型结构
先将图像用卷积进行分块以降低计算量,再对每一块进行展平处理变成序列,然后将图像序列与NLP序列一起放入encoder编码,再将encoder编码与target在decoder中一起提取特征输出预测结果,整体结构由encoder-decoder组成。
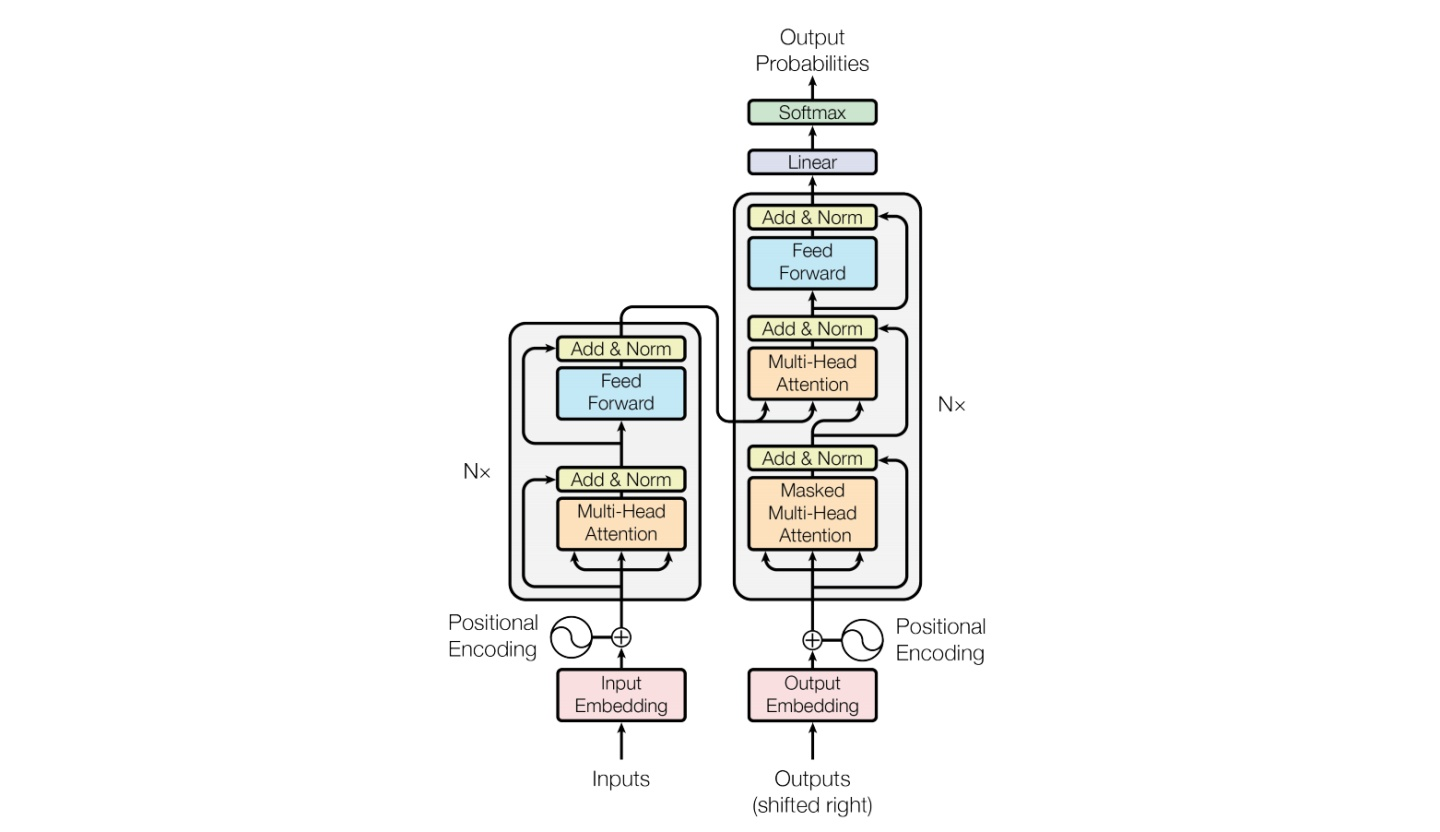
## 算法原理
借鉴《Transformer is all you need!》算法论文中的Transformer结构,利用注意力模块attention提取特征,本文的核心思想是将文本、图像、检测目标用统一的词表进行序列编码,然后就可以用同一个模型结构训练、预测,从而使模型具有更强的通用性。
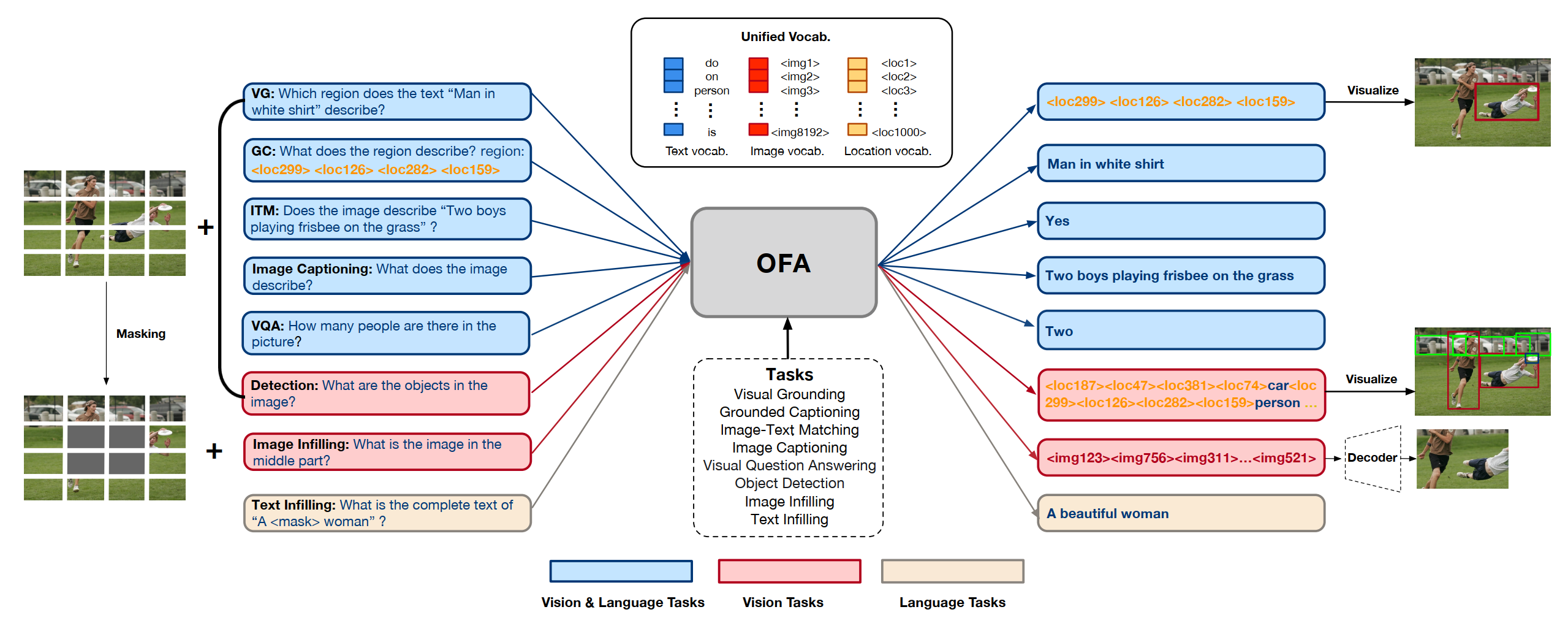
## 环境配置
```
mv OFA_pytorch OFA # 去框架名后缀
mkdir -p OFA/checkpoints
../../checkpoints/ofa_large.pt # finetune训练前,下载预训练权重ofa_large.pt到checkpoints文件夹下。
```
- https://ofa-beijing.oss-cn-beijing.aliyuncs.com/checkpoints/ofa_large.pt
也可参考[预训练权重](https://developer.hpccube.com/codes/modelzoo/ofa_pytorch/-/blob/main/README.md#%E9%A2%84%E8%AE%AD%E7%BB%83%E6%9D%83%E9%87%8D)部分进行下载
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
# 用以上拉取的docker的镜像ID替换
docker run --shm-size=32G --name=ofa --privileged=true --device=/dev/kfd --device=/dev/dri/ -v /opt/hyhal:/opt/hyhal:ro --group-add video -v $PWD/OFA:/home/OFA -it bash
pip install -r requirements.txt
cp -r OFA/nltk_data /root/ # 放置nltk库需要加载的.zip压缩包
```
### Dockerfile(方法二)
```
cd OFA/docker
docker build --no-cache -t ofa:latest .
docker run --shm-size=32G --name=ofa --privileged=true --device=/dev/kfd --device=/dev/dri/ -v /opt/hyhal:/opt/hyhal:ro --group-add video -v $PWD/../../OFA:/home/OFA -it ofa:latest bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt
cp -r OFA/nltk_data /root/ # 放置nltk库需要加载的.zip压缩包
cd OFA && pip install -e ./fairseq/
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk24.04.1
python:python3.10
torch:2.1.0
torchvision:0.16.0
torchaudio:2.1.2
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应,fairseq只能使用项目中自带的经开源作者改造的版本(v1.0.0)。`
2、其它非特殊库参照requirements.txt安装
```
pip install -r requirements.txt
cp -r OFA/nltk_data /root/ # 放置nltk库需要加载的.zip压缩包
```
## 数据集
OFA所用数据来自大量公开数据集:
本项目主要用到`COCO`
- https://cocodataset.org/#download
虽然项目中所用到的数据集皆来自公开数据集,但源作者根据算法的特点进行了改造定制,训练推理需要下载以下数据集,目前暂未开源数据处理代码,未来将会开源。
- https://ofa-beijing.oss-cn-beijing.aliyuncs.com/datasets/caption_data/caption_data.zip
训练数据目录结构如下,将caption_data.zip解压到以下目录即可正常训练:
```
OFA/
├── dataset/
│ ├── caption_data/
│ │ ├── caption_stage1_train.tsv
│ │ ├── caption_stage2_train.tsv
│ │ ├── caption_test.tsv
│ │ ├── caption_val.tsv
│ │ ├── test_caption_coco_format.json
│ │ └── cider_cached_tokens/
│ │ ├── coco-test-words.p
│ ├── coco-train-words.p
│ │ └── coco-valid-words.p
│ │
│ └── xxx_data/
```
`更多资料可参考源项目的README_origin.md`
## 训练
### 单机多卡
```
cd OFA/run_scripts/caption
nohup sh train_caption_stage1.sh > train_stage1.out & # stage 1, train with cross-entropy loss
cp stage1_checkpoints/2_0.06_2500/checkpoint_best.pt ../../checkpoints/caption_stage1_best.pt
nohup sh train_caption_stage2.sh > train_stage2.out & # stage 2, load the best ckpt of stage1 and train with CIDEr optimization
```
## 推理
前文中的fairseq版本无法成功推理,此处需要重新安装,且github上fairseq开源的官方代码也可能无法安装成功。建议按以下方式安装:
```
pip install fairseq==0.12.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
```
```
cp stage2_checkpoints/1e-5_3/checkpoint_best.pt ../../checkpoints/caption_large_best_clean.pt
cd ../../
python caption_infer.py # 来自colab.md下的Image Captioning
```
## result
输入图片:
输出文字描述:
```
a row of houses on a street.
```
### 精度
测试数据:[caption_data]("./dataset/caption_data/caption_test.tsv")中的test数据,推理框架:pytorch。
| device | Bleu_1 | Bleu_2 | Bleu_3 | Bleu_4 | METEOR | ROUGE_L | CIDEr | SPICE |
|:--------:| :------: | :------: | :------: |:------: | :------: | :------: | :------: |:------: |
| DCU Z100 | 0.836 | 0.694 | 0.555 | 0.434 | 0.320 | 0.622 | 1.484 | 0.259 |
| GPU A800 | 0.840 | 0.697 | 0.556 | 0.434 | 0.319 | 0.622 | 1.488 | 0.258 |
## 应用场景
### 算法类别
`图像理解`
### 热点应用行业
`零售,广媒,制造,家居,政府`
## 预训练权重
从OFA/checkpoints.md下的Pretraining下载作者的开源large版本预训练权重
- https://github.com/OFA-Sys/OFA/blob/main/checkpoints.md
```
cat ofa_large.pt.0.* > ofa_large.pt
```
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/ofa_pytorch
## 参考资料
- https://github.com/OFA-Sys/OFA