{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| default_exp models.tsmixerx"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| hide\n",
"%load_ext autoreload\n",
"%autoreload 2"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# TSMixerx\n",
"> Time-Series Mixer exogenous (`TSMixerx`) is a MLP-based multivariate time-series forecasting model, with capability for additional exogenous inputs. `TSMixerx` jointly learns temporal and cross-sectional representations of the time-series by repeatedly combining time- and feature information using stacked mixing layers. A mixing layer consists of a sequential time- and feature Multi Layer Perceptron (`MLP`).\n",
"
**References**
-[Chen, Si-An, Chun-Liang Li, Nate Yoder, Sercan O. Arik, and Tomas Pfister (2023). \"TSMixer: An All-MLP Architecture for Time Series Forecasting.\"](http://arxiv.org/abs/2303.06053)
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"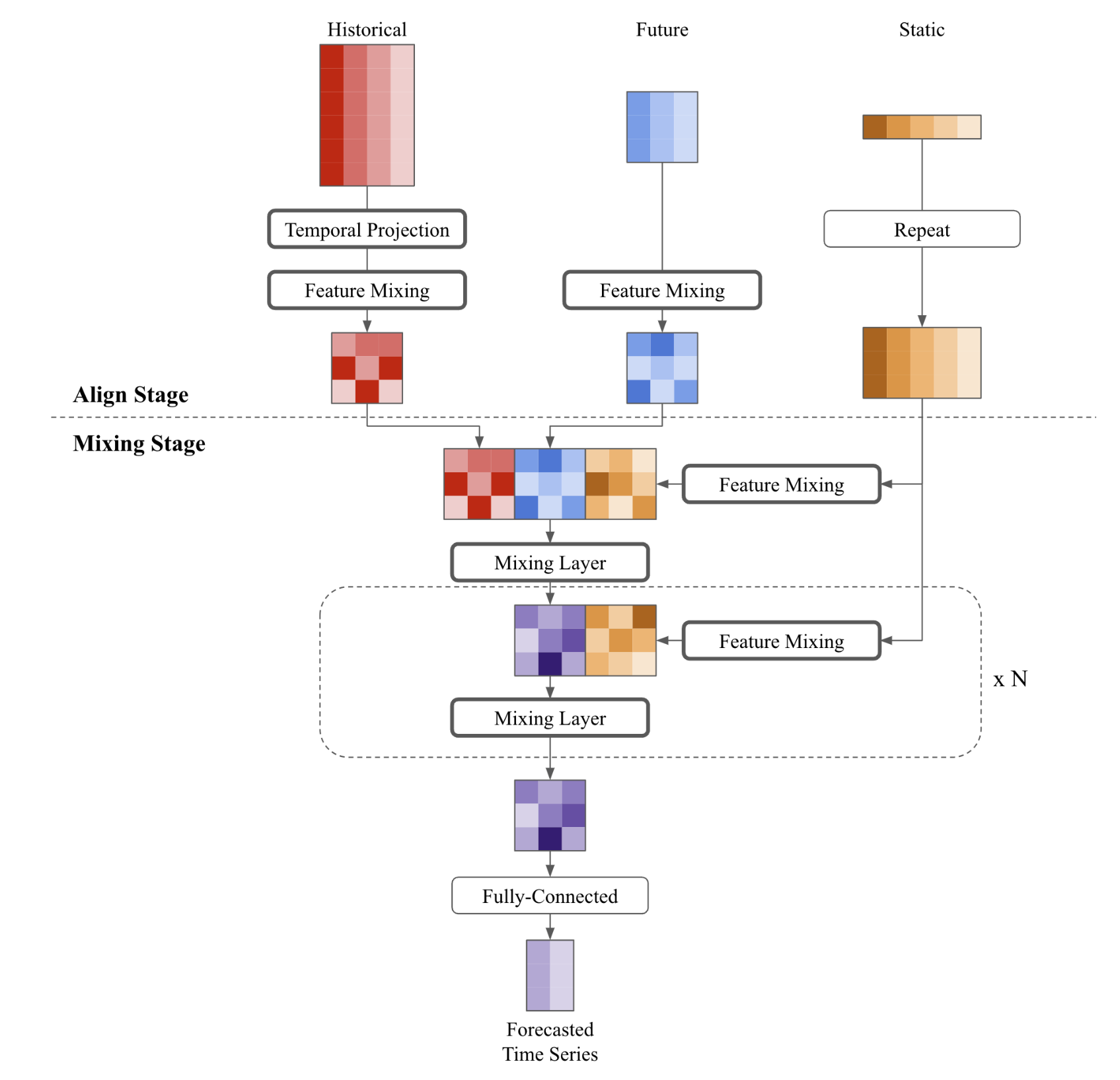"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| hide\n",
"from fastcore.test import test_eq\n",
"from nbdev.showdoc import show_doc"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| export\n",
"import torch\n",
"import torch.nn as nn\n",
"import torch.nn.functional as F\n",
"\n",
"from neuralforecast.losses.pytorch import MAE\n",
"from neuralforecast.common._base_multivariate import BaseMultivariate"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1. Auxiliary Functions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1.1 Mixing layers\n",
"A mixing layer consists of a sequential time- and feature Multi Layer Perceptron (`MLP`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| exporti\n",
"class TemporalMixing(nn.Module):\n",
" def __init__(self, num_features, h, dropout):\n",
" super().__init__()\n",
" self.temporal_norm = nn.LayerNorm(normalized_shape=(h, num_features))\n",
" self.temporal_lin = nn.Linear(h, h)\n",
" self.temporal_drop = nn.Dropout(dropout)\n",
"\n",
" def forward(self, input):\n",
" x = input.permute(0, 2, 1) # [B, h, C] -> [B, C, h]\n",
" x = F.relu(self.temporal_lin(x)) # [B, C, h] -> [B, C, h]\n",
" x = x.permute(0, 2, 1) # [B, C, h] -> [B, h, C]\n",
" x = self.temporal_drop(x) # [B, h, C] -> [B, h, C]\n",
"\n",
" return self.temporal_norm(x + input)\n",
"\n",
"class FeatureMixing(nn.Module):\n",
" def __init__(self, in_features, out_features, h, dropout, ff_dim):\n",
" super().__init__()\n",
" self.feature_lin_1 = nn.Linear(in_features=in_features, \n",
" out_features=ff_dim)\n",
" self.feature_lin_2 = nn.Linear(in_features=ff_dim, \n",
" out_features=out_features)\n",
" self.feature_drop_1 = nn.Dropout(p=dropout)\n",
" self.feature_drop_2 = nn.Dropout(p=dropout)\n",
" self.linear_project_residual = False\n",
" if in_features != out_features:\n",
" self.project_residual = nn.Linear(in_features = in_features,\n",
" out_features = out_features)\n",
" self.linear_project_residual = True\n",
"\n",
" self.feature_norm = nn.LayerNorm(normalized_shape=(h, out_features))\n",
"\n",
" def forward(self, input):\n",
" x = F.relu(self.feature_lin_1(input)) # [B, h, C_in] -> [B, h, ff_dim]\n",
" x = self.feature_drop_1(x) # [B, h, ff_dim] -> [B, h, ff_dim]\n",
" x = self.feature_lin_2(x) # [B, h, ff_dim] -> [B, h, C_out]\n",
" x = self.feature_drop_2(x) # [B, h, C_out] -> [B, h, C_out]\n",
" if self.linear_project_residual:\n",
" input = self.project_residual(input) # [B, h, C_in] -> [B, h, C_out]\n",
"\n",
" return self.feature_norm(x + input)\n",
"\n",
"class MixingLayer(nn.Module):\n",
" def __init__(self, in_features, out_features, h, dropout, ff_dim):\n",
" super().__init__()\n",
" # Mixing layer consists of a temporal and feature mixer\n",
" self.temporal_mixer = TemporalMixing(num_features=in_features, \n",
" h=h, \n",
" dropout=dropout)\n",
" self.feature_mixer = FeatureMixing(in_features=in_features, \n",
" out_features=out_features, \n",
" h=h, \n",
" dropout=dropout, \n",
" ff_dim=ff_dim)\n",
"\n",
" def forward(self, input):\n",
" x = self.temporal_mixer(input) # [B, h, C_in] -> [B, h, C_in]\n",
" x = self.feature_mixer(x) # [B, h, C_in] -> [B, h, C_out]\n",
" return x\n",
" \n",
"class MixingLayerWithStaticExogenous(nn.Module):\n",
" def __init__(self, h, dropout, ff_dim, stat_input_size):\n",
" super().__init__()\n",
" # Feature mixer for the static exogenous variables\n",
" self.feature_mixer_stat = FeatureMixing(in_features=stat_input_size, \n",
" out_features=ff_dim, \n",
" h=h, \n",
" dropout=dropout, \n",
" ff_dim=ff_dim)\n",
" # Mixing layer consists of a temporal and feature mixer\n",
" self.temporal_mixer = TemporalMixing(num_features=2 * ff_dim, \n",
" h=h, \n",
" dropout=dropout)\n",
" self.feature_mixer = FeatureMixing(in_features=2 * ff_dim, \n",
" out_features=ff_dim, \n",
" h=h, \n",
" dropout=dropout, \n",
" ff_dim=ff_dim)\n",
"\n",
" def forward(self, inputs):\n",
" input, stat_exog = inputs\n",
" x_stat = self.feature_mixer_stat(stat_exog) # [B, h, S] -> [B, h, ff_dim]\n",
" x = torch.cat((input, x_stat), dim=2) # [B, h, ff_dim] + [B, h, ff_dim] -> [B, h, 2 * ff_dim]\n",
" x = self.temporal_mixer(x) # [B, h, 2 * ff_dim] -> [B, h, 2 * ff_dim]\n",
" x = self.feature_mixer(x) # [B, h, 2 * ff_dim] -> [B, h, ff_dim]\n",
" return (x, stat_exog)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1.2 Reversible InstanceNormalization\n",
"An Instance Normalization Layer that is reversible, based on [this reference implementation](https://github.com/google-research/google-research/blob/master/tsmixer/tsmixer_basic/models/rev_in.py).
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| exporti\n",
"class ReversibleInstanceNorm1d(nn.Module):\n",
" def __init__(self, n_series, eps=1e-5):\n",
" super().__init__()\n",
" self.weight = nn.Parameter(torch.ones((1, 1, 1, n_series)))\n",
" self.bias = nn.Parameter(torch.zeros((1, 1, 1, n_series)))\n",
" self.eps = eps\n",
"\n",
" def forward(self, x):\n",
" # Batch statistics\n",
" self.batch_mean = torch.mean(x, axis=2, keepdim=True).detach()\n",
" self.batch_std = torch.sqrt(torch.var(x, axis=2, keepdim=True, unbiased=False) + self.eps).detach()\n",
" \n",
" # Instance normalization\n",
" x = x - self.batch_mean\n",
" x = x / self.batch_std\n",
" x = x * self.weight\n",
" x = x + self.bias\n",
" \n",
" return x\n",
"\n",
" def reverse(self, x):\n",
" # Reverse the normalization\n",
" x = x - self.bias\n",
" x = x / self.weight \n",
" x = x * self.batch_std\n",
" x = x + self.batch_mean \n",
"\n",
" return x"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2. Model"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| export\n",
"class TSMixerx(BaseMultivariate):\n",
" \"\"\" TSMixerx\n",
"\n",
" Time-Series Mixer exogenous (`TSMixerx`) is a MLP-based multivariate time-series forecasting model, with capability for additional exogenous inputs. `TSMixerx` jointly learns temporal and cross-sectional representations of the time-series by repeatedly combining time- and feature information using stacked mixing layers. A mixing layer consists of a sequential time- and feature Multi Layer Perceptron (`MLP`).\n",
"\n",
" **Parameters:**
\n",
" `h`: int, forecast horizon.
\n",
" `input_size`: int, considered autorregresive inputs (lags), y=[1,2,3,4] input_size=2 -> lags=[1,2].
\n",
" `n_series`: int, number of time-series.
\n",
" `futr_exog_list`: str list, future exogenous columns.
\n",
" `hist_exog_list`: str list, historic exogenous columns.
\n",
" `stat_exog_list`: str list, static exogenous columns.
\n",
" `n_block`: int=2, number of mixing layers in the model.
\n",
" `ff_dim`: int=64, number of units for the second feed-forward layer in the feature MLP.
\n",
" `dropout`: float=0.0, dropout rate between (0, 1) .
\n",
" `revin`: bool=True, if True uses Reverse Instance Normalization on `insample_y` and applies it to the outputs.
\n",
" `loss`: PyTorch module, instantiated train loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).
\n",
" `valid_loss`: PyTorch module=`loss`, instantiated valid loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).
\n",
" `max_steps`: int=1000, maximum number of training steps.
\n",
" `learning_rate`: float=1e-3, Learning rate between (0, 1).
\n",
" `num_lr_decays`: int=-1, Number of learning rate decays, evenly distributed across max_steps.
\n",
" `early_stop_patience_steps`: int=-1, Number of validation iterations before early stopping.
\n",
" `val_check_steps`: int=100, Number of training steps between every validation loss check.
\n",
" `batch_size`: int=32, number of different series in each batch.
\n",
" `step_size`: int=1, step size between each window of temporal data.
\n",
" `scaler_type`: str='identity', type of scaler for temporal inputs normalization see [temporal scalers](https://nixtla.github.io/neuralforecast/common.scalers.html).
\n",
" `random_seed`: int=1, random_seed for pytorch initializer and numpy generators.
\n",
" `num_workers_loader`: int=os.cpu_count(), workers to be used by `TimeSeriesDataLoader`.
\n",
" `drop_last_loader`: bool=False, if True `TimeSeriesDataLoader` drops last non-full batch.
\n",
" `alias`: str, optional, Custom name of the model.
\n",
" `optimizer`: Subclass of 'torch.optim.Optimizer', optional, user specified optimizer instead of the default choice (Adam).
\n",
" `optimizer_kwargs`: dict, optional, list of parameters used by the user specified `optimizer`.
\n",
" `**trainer_kwargs`: int, keyword trainer arguments inherited from [PyTorch Lighning's trainer](https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.trainer.trainer.Trainer.html?highlight=trainer).
\n",
"\n",
" **References:**
\n",
" - [Chen, Si-An, Chun-Liang Li, Nate Yoder, Sercan O. Arik, and Tomas Pfister (2023). \"TSMixer: An All-MLP Architecture for Time Series Forecasting.\"](http://arxiv.org/abs/2303.06053)\n",
"\n",
" \"\"\"\n",
" # Class attributes\n",
" SAMPLING_TYPE = 'multivariate'\n",
" \n",
" def __init__(self,\n",
" h,\n",
" input_size,\n",
" n_series,\n",
" futr_exog_list = None,\n",
" hist_exog_list = None,\n",
" stat_exog_list = None,\n",
" n_block = 2,\n",
" ff_dim = 64,\n",
" dropout = 0.0,\n",
" revin = True,\n",
" loss = MAE(),\n",
" valid_loss = None,\n",
" max_steps: int = 1000,\n",
" learning_rate: float = 1e-3,\n",
" num_lr_decays: int = -1,\n",
" early_stop_patience_steps: int =-1,\n",
" val_check_steps: int = 100,\n",
" batch_size: int = 32,\n",
" step_size: int = 1,\n",
" scaler_type: str = 'identity',\n",
" random_seed: int = 1,\n",
" num_workers_loader: int = 0,\n",
" drop_last_loader: bool = False,\n",
" optimizer = None,\n",
" optimizer_kwargs = None,\n",
" **trainer_kwargs):\n",
"\n",
" # Inherit BaseMultvariate class\n",
" super(TSMixerx, self).__init__(h=h,\n",
" input_size=input_size,\n",
" n_series=n_series,\n",
" futr_exog_list=futr_exog_list,\n",
" hist_exog_list=hist_exog_list,\n",
" stat_exog_list=stat_exog_list,\n",
" loss=loss,\n",
" valid_loss=valid_loss,\n",
" max_steps=max_steps,\n",
" learning_rate=learning_rate,\n",
" num_lr_decays=num_lr_decays,\n",
" early_stop_patience_steps=early_stop_patience_steps,\n",
" val_check_steps=val_check_steps,\n",
" batch_size=batch_size,\n",
" step_size=step_size,\n",
" scaler_type=scaler_type,\n",
" random_seed=random_seed,\n",
" num_workers_loader=num_workers_loader,\n",
" drop_last_loader=drop_last_loader,\n",
" optimizer=optimizer,\n",
" optimizer_kwargs=optimizer_kwargs,\n",
" **trainer_kwargs)\n",
" # Reversible InstanceNormalization layer\n",
" self.revin = revin\n",
" if self.revin:\n",
" self.norm = ReversibleInstanceNorm1d(n_series = n_series)\n",
"\n",
" # Forecast horizon\n",
" self.h = h\n",
"\n",
" # Exogenous variables\n",
" self.futr_exog_size = len(self.futr_exog_list)\n",
" self.hist_exog_size = len(self.hist_exog_list)\n",
" self.stat_exog_size = len(self.stat_exog_list)\n",
"\n",
" # Temporal projection and feature mixing of historical variables\n",
" self.temporal_projection = nn.Linear(in_features=input_size, \n",
" out_features=h)\n",
"\n",
" self.feature_mixer_hist = FeatureMixing(in_features=n_series * (1 + self.hist_exog_size + self.futr_exog_size),\n",
" out_features=ff_dim,\n",
" h=h, \n",
" dropout=dropout, \n",
" ff_dim=ff_dim)\n",
" first_mixing_ff_dim_multiplier = 1\n",
"\n",
" # Feature mixing of future variables\n",
" if self.futr_exog_size > 0:\n",
" self.feature_mixer_futr = FeatureMixing(in_features = n_series * self.futr_exog_size,\n",
" out_features=ff_dim,\n",
" h=h,\n",
" dropout=dropout,\n",
" ff_dim=ff_dim)\n",
" first_mixing_ff_dim_multiplier += 1\n",
"\n",
" # Feature mixing of static variables\n",
" if self.stat_exog_size > 0:\n",
" self.feature_mixer_stat = FeatureMixing(in_features=self.stat_exog_size * n_series,\n",
" out_features=ff_dim,\n",
" h=h,\n",
" dropout=dropout,\n",
" ff_dim=ff_dim) \n",
" first_mixing_ff_dim_multiplier += 1\n",
"\n",
" # First mixing layer\n",
" self.first_mixing = MixingLayer(in_features = first_mixing_ff_dim_multiplier * ff_dim,\n",
" out_features=ff_dim,\n",
" h=h,\n",
" dropout=dropout,\n",
" ff_dim=ff_dim)\n",
"\n",
" # Mixing layer block\n",
" if self.stat_exog_size > 0:\n",
" mixing_layers = [MixingLayerWithStaticExogenous(\n",
" h=h, \n",
" dropout=dropout, \n",
" ff_dim=ff_dim,\n",
" stat_input_size=self.stat_exog_size * n_series) \n",
" for _ in range(n_block)] \n",
" else:\n",
" mixing_layers = [MixingLayer(in_features=ff_dim,\n",
" out_features=ff_dim,\n",
" h=h, \n",
" dropout=dropout, \n",
" ff_dim=ff_dim) \n",
" for _ in range(n_block)]\n",
"\n",
" self.mixing_block = nn.Sequential(*mixing_layers)\n",
"\n",
" # Linear output with Loss dependent dimensions\n",
" self.out = nn.Linear(in_features=ff_dim, \n",
" out_features=self.loss.outputsize_multiplier * n_series)\n",
"\n",
"\n",
" def forward(self, windows_batch):\n",
" # Parse batch\n",
" x = windows_batch['insample_y'] # [batch_size (B), input_size (L), n_series (N)]\n",
" hist_exog = windows_batch['hist_exog'] # [B, hist_exog_size (X), L, N]\n",
" futr_exog = windows_batch['futr_exog'] # [B, futr_exog_size (F), L + h, N]\n",
" stat_exog = windows_batch['stat_exog'] # [N, stat_exog_size (S)]\n",
" batch_size, input_size = x.shape[:2]\n",
"\n",
" # Add channel dimension to x\n",
" x = x.unsqueeze(1) # [B, L, N] -> [B, 1, L, N]\n",
"\n",
" # Apply revin to x\n",
" if self.revin:\n",
" x = self.norm(x) # [B, 1, L, N] -> [B, 1, L, N]\n",
" \n",
" # Concatenate x with historical exogenous\n",
" if self.hist_exog_size > 0:\n",
" x = torch.cat((x, hist_exog), dim=1) # [B, 1, L, N] + [B, X, L, N] -> [B, 1 + X, L, N]\n",
"\n",
" # Concatenate x with future exogenous of input sequence\n",
" if self.futr_exog_size > 0:\n",
" futr_exog_hist = futr_exog[:, :, :input_size] # [B, F, L + h, N] -> [B, F, L, N]\n",
" x = torch.cat((x, futr_exog_hist), dim=1) # [B, 1 + X, L, N] + [B, F, L, N] -> [B, 1 + X + F, L, N]\n",
" \n",
" # Temporal projection & feature mixing of x\n",
" x = x.permute(0, 1, 3, 2) # [B, 1 + X + F, L, N] -> [B, 1 + X + F, N, L]\n",
" x = self.temporal_projection(x) # [B, 1 + X + F, N, L] -> [B, 1 + X + F, N, h]\n",
" x = x.permute(0, 3, 1, 2) # [B, 1 + X + F, N, h] -> [B, h, 1 + X + F, N]\n",
" x = x.reshape(batch_size, self.h, -1) # [B, h, 1 + X + F, N] -> [B, h, (1 + X + F) * N]\n",
" x = self.feature_mixer_hist(x) # [B, h, (1 + X + F) * N] -> [B, h, ff_dim] \n",
"\n",
" # Concatenate x with future exogenous of output horizon\n",
" if self.futr_exog_size > 0:\n",
" x_futr = futr_exog[:, :, input_size:] # [B, F, L + h, N] -> [B, F, h, N] \n",
" x_futr = x_futr.permute(0, 2, 1, 3) # [B, F, h, N] -> [B, h, F, N] \n",
" x_futr = x_futr.reshape(batch_size, \n",
" self.h, -1) # [B, h, N, F] -> [B, h, N * F]\n",
" x_futr = self.feature_mixer_futr(x_futr) # [B, h, N * F] -> [B, h, ff_dim] \n",
" x = torch.cat((x, x_futr), dim=2) # [B, h, ff_dim] + [B, h, ff_dim] -> [B, h, 2 * ff_dim]\n",
"\n",
" # Concatenate x with static exogenous\n",
" if self.stat_exog_size > 0:\n",
" stat_exog = stat_exog.reshape(-1) # [N, S] -> [N * S]\n",
" stat_exog = stat_exog.unsqueeze(0)\\\n",
" .unsqueeze(1)\\\n",
" .repeat(batch_size, \n",
" self.h, \n",
" 1) # [N * S] -> [B, h, N * S]\n",
" x_stat = self.feature_mixer_stat(stat_exog) # [B, h, N * S] -> [B, h, ff_dim] \n",
" x = torch.cat((x, x_stat), dim=2) # [B, h, 2 * ff_dim] + [B, h, ff_dim] -> [B, h, 3 * ff_dim] \n",
"\n",
" # First mixing layer\n",
" x = self.first_mixing(x) # [B, h, 3 * ff_dim] -> [B, h, ff_dim] \n",
"\n",
" # N blocks of mixing layers\n",
" if self.stat_exog_size > 0:\n",
" x, _ = self.mixing_block((x, stat_exog)) # [B, h, ff_dim], [B, h, N * S] -> [B, h, ff_dim] \n",
" else:\n",
" x = self.mixing_block(x) # [B, h, ff_dim] -> [B, h, ff_dim] \n",
" \n",
" # Fully connected output layer\n",
" x = self.out(x) # [B, h, ff_dim] -> [B, h, N * n_outputs]\n",
" \n",
" # Reverse Instance Normalization on output\n",
" if self.revin:\n",
" x = x.reshape(batch_size, \n",
" self.h, \n",
" self.loss.outputsize_multiplier,\n",
" -1) # [B, h, N * n_outputs] -> [B, h, n_outputs, N]\n",
" x = self.norm.reverse(x)\n",
" x = x.reshape(batch_size, self.h, -1) # [B, h, n_outputs, N] -> [B, h, n_outputs * N]\n",
"\n",
" # Map to loss domain\n",
" forecast = self.loss.domain_map(x)\n",
"\n",
" # domain_map might have squeezed the last dimension in case n_series == 1\n",
" # Note that this fails in case of a tuple loss, but Multivariate does not support tuple losses yet.\n",
" if forecast.ndim == 2:\n",
" return forecast.unsqueeze(-1)\n",
" else:\n",
" return forecast"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"show_doc(TSMixerx)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"show_doc(TSMixerx.fit, name='TSMixerx.fit')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"show_doc(TSMixerx.predict, name='TSMixerx.predict')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| hide\n",
"import logging\n",
"import warnings\n",
"import pandas as pd\n",
"\n",
"from neuralforecast import NeuralForecast\n",
"from neuralforecast.utils import AirPassengersPanel, AirPassengersStatic, generate_series\n",
"from neuralforecast.losses.pytorch import MAE, MSE, RMSE, MAPE, SMAPE, MASE, relMSE, QuantileLoss, MQLoss, DistributionLoss,PMM, GMM, NBMM, HuberLoss, TukeyLoss, HuberQLoss, HuberMQLoss\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| hide\n",
"# Test losses\n",
"logging.getLogger(\"pytorch_lightning\").setLevel(logging.ERROR)\n",
"warnings.filterwarnings(\"ignore\")\n",
"\n",
"Y_train_df = AirPassengersPanel[AirPassengersPanel.ds=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True) # 12 test\n",
"\n",
"AirPassengersStatic_single = AirPassengersStatic[AirPassengersStatic[\"unique_id\"] == 'Airline1']\n",
"Y_train_df_single = Y_train_df[Y_train_df[\"unique_id\"] == 'Airline1']\n",
"Y_test_df_single = Y_test_df[Y_test_df[\"unique_id\"] == 'Airline1']\n",
"\n",
"losses = [MAE(), MSE(), RMSE(), MAPE(), SMAPE(), MASE(seasonality=12), relMSE(y_train=Y_train_df), QuantileLoss(q=0.5), MQLoss(), DistributionLoss(distribution='Bernoulli'), DistributionLoss(distribution='Normal'), DistributionLoss(distribution='Poisson'), DistributionLoss(distribution='StudentT'), DistributionLoss(distribution='NegativeBinomial'), DistributionLoss(distribution='Tweedie'), PMM(), GMM(), NBMM(), HuberLoss(), TukeyLoss(), HuberQLoss(q=0.5), HuberMQLoss()]\n",
"valid_losses = [MAE(), MSE(), RMSE(), MAPE(), SMAPE(), MASE(seasonality=12), relMSE(y_train=Y_train_df), QuantileLoss(q=0.5), MQLoss(), DistributionLoss(distribution='Bernoulli'), DistributionLoss(distribution='Normal'), DistributionLoss(distribution='Poisson'), DistributionLoss(distribution='StudentT'), DistributionLoss(distribution='NegativeBinomial'), DistributionLoss(distribution='Tweedie'), PMM(), GMM(), NBMM(), HuberLoss(), TukeyLoss(), HuberQLoss(q=0.5), HuberMQLoss()]\n",
"\n",
"for loss, valid_loss in zip(losses, valid_losses):\n",
" try:\n",
" model = TSMixerx(h=12,\n",
" input_size=24,\n",
" n_series=2,\n",
" stat_exog_list=['airline1'],\n",
" futr_exog_list=['trend'],\n",
" n_block=4,\n",
" ff_dim=4,\n",
" revin=True,\n",
" scaler_type='standard',\n",
" max_steps=2,\n",
" early_stop_patience_steps=-1,\n",
" val_check_steps=5,\n",
" learning_rate=1e-3,\n",
" loss=loss,\n",
" valid_loss=valid_loss,\n",
" batch_size=32\n",
" )\n",
"\n",
" fcst = NeuralForecast(models=[model], freq='M')\n",
" fcst.fit(df=Y_train_df, static_df=AirPassengersStatic, val_size=12)\n",
" forecasts = fcst.predict(futr_df=Y_test_df)\n",
" except Exception as e:\n",
" assert str(e) == f\"{loss} is not supported in a Multivariate model.\"\n",
"\n",
"\n",
"# Test n_series = 1\n",
"model = TSMixerx(h=12,\n",
" input_size=24,\n",
" n_series=1,\n",
" stat_exog_list=['airline1'],\n",
" futr_exog_list=['trend'],\n",
" n_block=4,\n",
" ff_dim=4,\n",
" revin=True,\n",
" scaler_type='standard',\n",
" max_steps=2,\n",
" early_stop_patience_steps=-1,\n",
" val_check_steps=5,\n",
" learning_rate=1e-3,\n",
" loss=MAE(),\n",
" valid_loss=MAE(),\n",
" batch_size=32\n",
" )\n",
"fcst = NeuralForecast(models=[model], freq='M')\n",
"fcst.fit(df=Y_train_df_single, static_df=AirPassengersStatic_single, val_size=12)\n",
"forecasts = fcst.predict(futr_df=Y_test_df_single) \n",
"\n",
"# Test n_series > 1024\n",
"# See issue: https://github.com/Nixtla/neuralforecast/issues/948\n",
"n_series = 1111\n",
"Y_df, S_df = generate_series(n_series=n_series, n_temporal_features=2, n_static_features=2)\n",
"\n",
"model = TSMixerx(\n",
" h=12,\n",
" input_size=24,\n",
" n_series=n_series,\n",
" stat_exog_list=['static_0', 'static_1'],\n",
" hist_exog_list=[\"temporal_0\", \"temporal_1\"],\n",
" n_block=4,\n",
" ff_dim=3,\n",
" revin=True,\n",
" scaler_type=\"standard\",\n",
" max_steps=5,\n",
" early_stop_patience_steps=-1,\n",
" val_check_steps=5,\n",
" learning_rate=1e-3,\n",
" loss=MAE(),\n",
" valid_loss=MAE(),\n",
" batch_size=32,\n",
")\n",
"\n",
"fcst = NeuralForecast(models=[model], freq=\"D\")\n",
"fcst.fit(df=Y_df, static_df=S_df, val_size=12)\n",
"forecasts = fcst.predict()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3. Usage Examples"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Train model and forecast future values with `predict` method."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| eval: false\n",
"import numpy as np\n",
"import pandas as pd\n",
"import pytorch_lightning as pl\n",
"import matplotlib.pyplot as plt\n",
"\n",
"from neuralforecast import NeuralForecast\n",
"from neuralforecast.utils import AirPassengersPanel, AirPassengersStatic\n",
"from neuralforecast.losses.pytorch import MAE\n",
"\n",
"Y_train_df = AirPassengersPanel[AirPassengersPanel.ds=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True) # 12 test\n",
"\n",
"model = TSMixerx(h=12,\n",
" input_size=24,\n",
" n_series=2,\n",
" stat_exog_list=['airline1'],\n",
" futr_exog_list=['trend'],\n",
" n_block=4,\n",
" ff_dim=4,\n",
" revin=True,\n",
" scaler_type='standard',\n",
" max_steps=200,\n",
" early_stop_patience_steps=-1,\n",
" val_check_steps=5,\n",
" learning_rate=1e-3,\n",
" loss=MAE(),\n",
" valid_loss=MAE(),\n",
" batch_size=32\n",
" )\n",
"\n",
"fcst = NeuralForecast(models=[model], freq='M')\n",
"fcst.fit(df=Y_train_df, static_df=AirPassengersStatic, val_size=12)\n",
"forecasts = fcst.predict(futr_df=Y_test_df)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| eval: false\n",
"# Plot predictions\n",
"fig, ax = plt.subplots(1, 1, figsize = (20, 7))\n",
"Y_hat_df = forecasts.reset_index(drop=False).drop(columns=['unique_id','ds'])\n",
"plot_df = pd.concat([Y_test_df, Y_hat_df], axis=1)\n",
"plot_df = pd.concat([Y_train_df, plot_df])\n",
"\n",
"plot_df = plot_df[plot_df.unique_id=='Airline1'].drop('unique_id', axis=1)\n",
"plt.plot(plot_df['ds'], plot_df['y'], c='black', label='True')\n",
"plt.plot(plot_df['ds'], plot_df['TSMixerx'], c='blue', label='Forecast')\n",
"ax.set_title('AirPassengers Forecast', fontsize=22)\n",
"ax.set_ylabel('Monthly Passengers', fontsize=20)\n",
"ax.set_xlabel('Year', fontsize=20)\n",
"ax.legend(prop={'size': 15})\n",
"ax.grid()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Using `cross_validation` to forecast multiple historic values."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| eval: false\n",
"fcst = NeuralForecast(models=[model], freq='M')\n",
"forecasts = fcst.cross_validation(df=AirPassengersPanel, static_df=AirPassengersStatic, n_windows=2, step_size=12)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| eval: false\n",
"# Plot predictions\n",
"fig, ax = plt.subplots(1, 1, figsize = (20, 7))\n",
"Y_hat_df = forecasts.loc['Airline1']\n",
"Y_df = AirPassengersPanel[AirPassengersPanel['unique_id']=='Airline1']\n",
"\n",
"plt.plot(Y_df['ds'], Y_df['y'], c='black', label='True')\n",
"plt.plot(Y_hat_df['ds'], Y_hat_df['TSMixerx'], c='blue', label='Forecast')\n",
"ax.set_title('AirPassengers Forecast', fontsize=22)\n",
"ax.set_ylabel('Monthly Passengers', fontsize=20)\n",
"ax.set_xlabel('Year', fontsize=20)\n",
"ax.legend(prop={'size': 15})\n",
"ax.grid()"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "python3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}