{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| default_exp models.timellm"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| hide\n",
"\n",
"%load_ext autoreload\n",
"%autoreload 2"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Time-LLM"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Time-LLM is a reprogramming framework to repurpose LLMs for general time series forecasting with the backbone language models kept intact. In other words, it transforms a forecasting task into a \"language task\" that can be tackled by an off-the-shelf LLM."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**References**
\n",
"- [Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, Qingsong Wen. \"Time-LLM: Time Series Forecasting by Reprogramming Large Language Models\"](https://arxiv.org/abs/2310.01728)
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"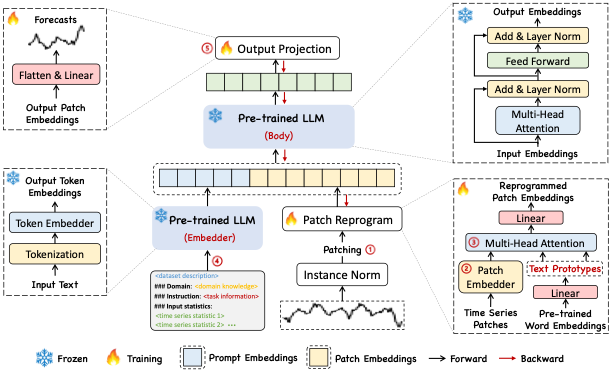"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| export\n",
"import math\n",
"from typing import Optional\n",
"\n",
"import torch\n",
"import torch.nn as nn\n",
"\n",
"from neuralforecast.common._base_windows import BaseWindows\n",
"\n",
"from neuralforecast.losses.pytorch import MAE\n",
"\n",
"try:\n",
" from transformers import GPT2Config, GPT2Model, GPT2Tokenizer\n",
" IS_TRANSFORMERS_INSTALLED = True\n",
"except ImportError:\n",
" IS_TRANSFORMERS_INSTALLED = False"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| hide\n",
"from fastcore.test import test_eq\n",
"from nbdev.showdoc import show_doc"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1. Auxiliary Functions"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| export\n",
"\n",
"class ReplicationPad1d(nn.Module):\n",
" def __init__(self, padding):\n",
" super(ReplicationPad1d, self).__init__()\n",
" self.padding = padding\n",
"\n",
" def forward(self, input):\n",
" replicate_padding = input[:, :, -1].unsqueeze(-1).repeat(1, 1, self.padding[-1])\n",
" output = torch.cat([input, replicate_padding], dim=-1)\n",
" return output\n",
" \n",
"class TokenEmbedding(nn.Module):\n",
" def __init__(self, c_in, d_model):\n",
" super(TokenEmbedding, self).__init__()\n",
" padding = 1 if torch.__version__ >= '1.5.0' else 2\n",
" self.tokenConv = nn.Conv1d(in_channels=c_in, out_channels=d_model,\n",
" kernel_size=3, padding=padding, padding_mode='circular', bias=False)\n",
" for m in self.modules():\n",
" if isinstance(m, nn.Conv1d):\n",
" nn.init.kaiming_normal_(\n",
" m.weight, mode='fan_in', nonlinearity='leaky_relu')\n",
"\n",
" def forward(self, x):\n",
" x = self.tokenConv(x.permute(0, 2, 1)).transpose(1, 2)\n",
" return x\n",
" \n",
"class PatchEmbedding(nn.Module):\n",
" def __init__(self, d_model, patch_len, stride, dropout):\n",
" super(PatchEmbedding, self).__init__()\n",
" # Patching\n",
" self.patch_len = patch_len\n",
" self.stride = stride\n",
" self.padding_patch_layer = ReplicationPad1d((0, stride))\n",
"\n",
" # Backbone, Input encoding: projection of feature vectors onto a d-dim vector space\n",
" self.value_embedding = TokenEmbedding(patch_len, d_model)\n",
"\n",
" # Positional embedding\n",
" # self.position_embedding = PositionalEmbedding(d_model)\n",
"\n",
" # Residual dropout\n",
" self.dropout = nn.Dropout(dropout)\n",
"\n",
" def forward(self, x):\n",
" # do patching\n",
" n_vars = x.shape[1]\n",
" x = self.padding_patch_layer(x)\n",
" x = x.unfold(dimension=-1, size=self.patch_len, step=self.stride)\n",
" x = torch.reshape(x, (x.shape[0] * x.shape[1], x.shape[2], x.shape[3]))\n",
" # Input encoding\n",
" x = self.value_embedding(x)\n",
" return self.dropout(x), n_vars\n",
" \n",
"class FlattenHead(nn.Module):\n",
" def __init__(self, n_vars, nf, target_window, head_dropout=0):\n",
" super().__init__()\n",
" self.n_vars = n_vars\n",
" self.flatten = nn.Flatten(start_dim=-2)\n",
" self.linear = nn.Linear(nf, target_window)\n",
" self.dropout = nn.Dropout(head_dropout)\n",
"\n",
" def forward(self, x):\n",
" x = self.flatten(x)\n",
" x = self.linear(x)\n",
" x = self.dropout(x)\n",
" return x\n",
" \n",
"class ReprogrammingLayer(nn.Module):\n",
" def __init__(self, d_model, n_heads, d_keys=None, d_llm=None, attention_dropout=0.1):\n",
" super(ReprogrammingLayer, self).__init__()\n",
"\n",
" d_keys = d_keys or (d_model // n_heads)\n",
"\n",
" self.query_projection = nn.Linear(d_model, d_keys * n_heads)\n",
" self.key_projection = nn.Linear(d_llm, d_keys * n_heads)\n",
" self.value_projection = nn.Linear(d_llm, d_keys * n_heads)\n",
" self.out_projection = nn.Linear(d_keys * n_heads, d_llm)\n",
" self.n_heads = n_heads\n",
" self.dropout = nn.Dropout(attention_dropout)\n",
"\n",
" def forward(self, target_embedding, source_embedding, value_embedding):\n",
" B, L, _ = target_embedding.shape\n",
" S, _ = source_embedding.shape\n",
" H = self.n_heads\n",
"\n",
" target_embedding = self.query_projection(target_embedding).view(B, L, H, -1)\n",
" source_embedding = self.key_projection(source_embedding).view(S, H, -1)\n",
" value_embedding = self.value_projection(value_embedding).view(S, H, -1)\n",
"\n",
" out = self.reprogramming(target_embedding, source_embedding, value_embedding)\n",
"\n",
" out = out.reshape(B, L, -1)\n",
"\n",
" return self.out_projection(out)\n",
"\n",
" def reprogramming(self, target_embedding, source_embedding, value_embedding):\n",
" B, L, H, E = target_embedding.shape\n",
"\n",
" scale = 1. / math.sqrt(E)\n",
"\n",
" scores = torch.einsum(\"blhe,she->bhls\", target_embedding, source_embedding)\n",
"\n",
" A = self.dropout(torch.softmax(scale * scores, dim=-1))\n",
" reprogramming_embedding = torch.einsum(\"bhls,she->blhe\", A, value_embedding)\n",
"\n",
" return reprogramming_embedding\n",
" \n",
"class Normalize(nn.Module):\n",
" def __init__(self, num_features: int, eps=1e-5, affine=False, subtract_last=False, non_norm=False):\n",
" \"\"\"\n",
" :param num_features: the number of features or channels\n",
" :param eps: a value added for numerical stability\n",
" :param affine: if True, RevIN has learnable affine parameters\n",
" \"\"\"\n",
" super(Normalize, self).__init__()\n",
" self.num_features = num_features\n",
" self.eps = eps\n",
" self.affine = affine\n",
" self.subtract_last = subtract_last\n",
" self.non_norm = non_norm\n",
" if self.affine:\n",
" self._init_params()\n",
"\n",
" def forward(self, x, mode: str):\n",
" if mode == 'norm':\n",
" self._get_statistics(x)\n",
" x = self._normalize(x)\n",
" elif mode == 'denorm':\n",
" x = self._denormalize(x)\n",
" else:\n",
" raise NotImplementedError\n",
" return x\n",
"\n",
" def _init_params(self):\n",
" # initialize RevIN params: (C,)\n",
" self.affine_weight = nn.Parameter(torch.ones(self.num_features))\n",
" self.affine_bias = nn.Parameter(torch.zeros(self.num_features))\n",
"\n",
" def _get_statistics(self, x):\n",
" dim2reduce = tuple(range(1, x.ndim - 1))\n",
" if self.subtract_last:\n",
" self.last = x[:, -1, :].unsqueeze(1)\n",
" else:\n",
" self.mean = torch.mean(x, dim=dim2reduce, keepdim=True).detach()\n",
" self.stdev = torch.sqrt(torch.var(x, dim=dim2reduce, keepdim=True, unbiased=False) + self.eps).detach()\n",
"\n",
" def _normalize(self, x):\n",
" if self.non_norm:\n",
" return x\n",
" if self.subtract_last:\n",
" x = x - self.last\n",
" else:\n",
" x = x - self.mean\n",
" x = x / self.stdev\n",
" if self.affine:\n",
" x = x * self.affine_weight\n",
" x = x + self.affine_bias\n",
" return x\n",
"\n",
" def _denormalize(self, x):\n",
" if self.non_norm:\n",
" return x\n",
" if self.affine:\n",
" x = x - self.affine_bias\n",
" x = x / (self.affine_weight + self.eps * self.eps)\n",
" x = x * self.stdev\n",
" if self.subtract_last:\n",
" x = x + self.last\n",
" else:\n",
" x = x + self.mean\n",
" return x"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2. Model"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| export\n",
"\n",
"class TimeLLM(BaseWindows):\n",
"\n",
" \"\"\" TimeLLM\n",
"\n",
" Time-LLM is a reprogramming framework to repurpose an off-the-shelf LLM for time series forecasting.\n",
"\n",
" It trains a reprogramming layer that translates the observed series into a language task. This is fed to the LLM and an output\n",
" projection layer translates the output back to numerical predictions.\n",
"\n",
" **Parameters:**
\n",
" `h`: int, Forecast horizon.
\n",
" `input_size`: int, autorregresive inputs size, y=[1,2,3,4] input_size=2 -> y_[t-2:t]=[1,2].
\n",
" `patch_len`: int=16, length of patch.
\n",
" `stride`: int=8, stride of patch.
\n",
" `d_ff`: int=128, dimension of fcn.
\n",
" `top_k`: int=5, top tokens to consider.
\n",
" `d_llm`: int=768, hidden dimension of LLM.
\n",
" `d_model`: int=32, dimension of model.
\n",
" `n_heads`: int=8, number of heads in attention layer.
\n",
" `enc_in`: int=7, encoder input size.
\n",
" `dec_in`: int=7, decoder input size.
\n",
" `llm` = None, LLM model to use. If not specified, it will use GPT-2 from https://huggingface.co/openai-community/gpt2\"
\n",
" `llm_config` = None, configuration of LLM. If not specified, it will use the configuration of GPT-2 from https://huggingface.co/openai-community/gpt2\"
\n",
" `llm_tokenizer` = None, tokenizer of LLM. If not specified, it will use the GPT-2 tokenizer from https://huggingface.co/openai-community/gpt2\"
\n",
" `llm_num_hidden_layers` = 32, hidden layers in LLM\n",
" `llm_output_attention`: bool = True, whether to output attention in encoder.
\n",
" `llm_output_hidden_states`: bool = True, whether to output hidden states.
\n",
" `prompt_prefix`: str=None, prompt to inform the LLM about the dataset.
\n",
" `dropout`: float=0.1, dropout rate.
\n",
" `stat_exog_list`: str list, static exogenous columns.
\n",
" `hist_exog_list`: str list, historic exogenous columns.
\n",
" `futr_exog_list`: str list, future exogenous columns.
\n",
" `loss`: PyTorch module, instantiated train loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).
\n",
" `valid_loss`: PyTorch module=`loss`, instantiated valid loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).
\n",
" `learning_rate`: float=1e-3, Learning rate between (0, 1).
\n",
" `max_steps`: int=1000, maximum number of training steps.
\n",
" `num_lr_decays`: int=-1, Number of learning rate decays, evenly distributed across max_steps.
\n",
" `early_stop_patience_steps`: int=-1, Number of validation iterations before early stopping.
\n",
" `val_check_steps`: int=100, Number of training steps between every validation loss check.
\n",
" `batch_size`: int=32, number of different series in each batch.
\n",
" `valid_batch_size`: int=None, number of different series in each validation and test batch, if None uses batch_size.
\n",
" `windows_batch_size`: int=1024, number of windows to sample in each training batch, default uses all.
\n",
" `inference_windows_batch_size`: int=1024, number of windows to sample in each inference batch.
\n",
" `start_padding_enabled`: bool=False, if True, the model will pad the time series with zeros at the beginning, by input size.
\n",
" `step_size`: int=1, step size between each window of temporal data.
\n",
" `scaler_type`: str='identity', type of scaler for temporal inputs normalization see [temporal scalers](https://nixtla.github.io/neuralforecast/common.scalers.html).
\n",
" `random_seed`: int, random_seed for pytorch initializer and numpy generators.
\n",
" `num_workers_loader`: int=os.cpu_count(), workers to be used by `TimeSeriesDataLoader`.
\n",
" `drop_last_loader`: bool=False, if True `TimeSeriesDataLoader` drops last non-full batch.
\n",
" `alias`: str, optional, Custom name of the model.
\n",
" `optimizer`: Subclass of 'torch.optim.Optimizer', optional, user specified optimizer instead of the default choice (Adam).
\n",
" `optimizer_kwargs`: dict, optional, list of parameters used by the user specified `optimizer`.
\n",
" `**trainer_kwargs`: int, keyword trainer arguments inherited from [PyTorch Lighning's trainer](https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.trainer.trainer.Trainer.html?highlight=trainer).
\n",
"\n",
" **References:**
\n",
" -[Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, Qingsong Wen. \"Time-LLM: Time Series Forecasting by Reprogramming Large Language Models\"](https://arxiv.org/abs/2310.01728)\n",
" \n",
" \"\"\"\n",
"\n",
" SAMPLING_TYPE = 'windows'\n",
"\n",
" def __init__(self,\n",
" h,\n",
" input_size,\n",
" patch_len: int = 16,\n",
" stride: int = 8,\n",
" d_ff: int = 128,\n",
" top_k: int = 5,\n",
" d_llm: int = 768,\n",
" d_model: int = 32,\n",
" n_heads: int = 8,\n",
" enc_in: int = 7,\n",
" dec_in: int = 7,\n",
" llm = None,\n",
" llm_config = None,\n",
" llm_tokenizer = None,\n",
" llm_num_hidden_layers = 32,\n",
" llm_output_attention: bool = True,\n",
" llm_output_hidden_states: bool = True,\n",
" prompt_prefix: Optional[str] = None,\n",
" dropout: float = 0.1,\n",
" stat_exog_list = None,\n",
" hist_exog_list = None,\n",
" futr_exog_list = None,\n",
" loss = MAE(),\n",
" valid_loss = None,\n",
" learning_rate: float = 1e-4,\n",
" max_steps: int = 5,\n",
" val_check_steps: int = 100,\n",
" batch_size: int = 32,\n",
" valid_batch_size: Optional[int] = None,\n",
" windows_batch_size: int = 1024,\n",
" inference_windows_batch_size: int = 1024,\n",
" start_padding_enabled: bool = False,\n",
" step_size: int = 1,\n",
" num_lr_decays: int = 0,\n",
" early_stop_patience_steps: int = -1,\n",
" scaler_type: str = 'identity',\n",
" num_workers_loader: int = 0,\n",
" drop_last_loader: bool = False,\n",
" random_seed: int = 1,\n",
" optimizer = None,\n",
" optimizer_kwargs = None,\n",
" **trainer_kwargs):\n",
" super(TimeLLM, self).__init__(h=h,\n",
" input_size=input_size,\n",
" hist_exog_list=hist_exog_list,\n",
" stat_exog_list=stat_exog_list,\n",
" futr_exog_list = futr_exog_list,\n",
" loss=loss,\n",
" valid_loss=valid_loss,\n",
" max_steps=max_steps,\n",
" learning_rate=learning_rate,\n",
" num_lr_decays=num_lr_decays,\n",
" early_stop_patience_steps=early_stop_patience_steps,\n",
" val_check_steps=val_check_steps,\n",
" batch_size=batch_size,\n",
" valid_batch_size=valid_batch_size,\n",
" windows_batch_size=windows_batch_size,\n",
" inference_windows_batch_size=inference_windows_batch_size,\n",
" start_padding_enabled=start_padding_enabled,\n",
" step_size=step_size,\n",
" scaler_type=scaler_type,\n",
" num_workers_loader=num_workers_loader,\n",
" drop_last_loader=drop_last_loader,\n",
" random_seed=random_seed,\n",
" optimizer=optimizer,\n",
" optimizer_kwargs=optimizer_kwargs,\n",
" **trainer_kwargs)\n",
" \n",
" # Asserts\n",
" if stat_exog_list is not None:\n",
" raise Exception(\"TimeLLM does not support static exogenous variables\")\n",
" if futr_exog_list is not None:\n",
" raise Exception(\"TimeLLM does not support future exogenous variables\")\n",
" if hist_exog_list is not None:\n",
" raise Exception(\"TimeLLM does not support historical exogenous variables\")\n",
"\n",
" # Architecture\n",
" self.patch_len = patch_len\n",
" self.stride = stride\n",
" self.d_ff = d_ff\n",
" self.top_k = top_k\n",
" self.d_llm = d_llm\n",
" self.d_model = d_model\n",
" self.dropout = dropout\n",
" self.n_heads = n_heads\n",
" self.enc_in = enc_in\n",
" self.dec_in = dec_in\n",
"\n",
" self.llm_config = llm_config\n",
" self.llm = llm\n",
" self.llm_tokenizer = llm_tokenizer\n",
"\n",
" if self.llm is None:\n",
" if not IS_TRANSFORMERS_INSTALLED:\n",
" raise ImportError(\"Please install `transformers` to use the default LLM\")\n",
" \n",
" print(\"Using GPT2 model as default and ignoring `llm_config` and `llm_tokenizer`\")\n",
"\n",
" self.llm_confg = GPT2Config.from_pretrained('openai-community/gpt2')\n",
" self.llm = GPT2Model.from_pretrained('openai-community/gpt2', config=self.llm_confg)\n",
" self.llm_tokenizer = GPT2Tokenizer.from_pretrained('openai-community/gpt2')\n",
"\n",
" self.llm_num_hidden_layers = llm_num_hidden_layers\n",
" self.llm_output_attention = llm_output_attention\n",
" self.llm_output_hidden_states = llm_output_hidden_states\n",
" self.prompt_prefix = prompt_prefix\n",
"\n",
" if self.llm_tokenizer.eos_token:\n",
" self.llm_tokenizer.pad_token = self.llm_tokenizer.eos_token\n",
" else:\n",
" pad_token = '[PAD]'\n",
" self.llm_tokenizer.add_special_tokens({'pad_token': pad_token})\n",
" self.llm_tokenizer.pad_token = pad_token\n",
"\n",
" for param in self.llm.parameters():\n",
" param.requires_grad = False\n",
"\n",
" self.patch_embedding = PatchEmbedding(\n",
" self.d_model, self.patch_len, self.stride, self.dropout)\n",
" \n",
" self.word_embeddings = self.llm.get_input_embeddings().weight\n",
" self.vocab_size = self.word_embeddings.shape[0]\n",
" self.num_tokens = 1024\n",
" self.mapping_layer = nn.Linear(self.vocab_size, self.num_tokens)\n",
"\n",
" self.reprogramming_layer = ReprogrammingLayer(self.d_model, self.n_heads, self.d_ff, self.d_llm)\n",
"\n",
" self.patch_nums = int((input_size - self.patch_len) / self.stride + 2)\n",
" self.head_nf = self.d_ff * self.patch_nums\n",
"\n",
" self.output_projection = FlattenHead(self.enc_in, self.head_nf, self.h, head_dropout=self.dropout)\n",
"\n",
" self.normalize_layers = Normalize(self.enc_in, affine=False)\n",
"\n",
" def forecast(self, x_enc):\n",
"\n",
" x_enc = self.normalize_layers(x_enc, 'norm')\n",
"\n",
" B, T, N = x_enc.size()\n",
" x_enc = x_enc.permute(0, 2, 1).contiguous().reshape(B * N, T, 1)\n",
"\n",
" min_values = torch.min(x_enc, dim=1)[0]\n",
" max_values = torch.max(x_enc, dim=1)[0]\n",
" medians = torch.median(x_enc, dim=1).values\n",
" lags = self.calcute_lags(x_enc)\n",
" trends = x_enc.diff(dim=1).sum(dim=1)\n",
"\n",
" prompt = []\n",
" for b in range(x_enc.shape[0]):\n",
" min_values_str = str(min_values[b].tolist()[0])\n",
" max_values_str = str(max_values[b].tolist()[0])\n",
" median_values_str = str(medians[b].tolist()[0])\n",
" lags_values_str = str(lags[b].tolist())\n",
" prompt_ = (\n",
" f\"<|start_prompt|>{self.prompt_prefix}\"\n",
" f\"Task description: forecast the next {str(self.h)} steps given the previous {str(self.input_size)} steps information; \"\n",
" \"Input statistics: \"\n",
" f\"min value {min_values_str}, \"\n",
" f\"max value {max_values_str}, \"\n",
" f\"median value {median_values_str}, \"\n",
" f\"the trend of input is {'upward' if trends[b] > 0 else 'downward'}, \"\n",
" f\"top 5 lags are : {lags_values_str}<||>\"\n",
" )\n",
"\n",
" prompt.append(prompt_)\n",
"\n",
" x_enc = x_enc.reshape(B, N, T).permute(0, 2, 1).contiguous()\n",
"\n",
" prompt = self.llm_tokenizer(prompt, return_tensors=\"pt\", padding=True, truncation=True, max_length=2048).input_ids\n",
" prompt_embeddings = self.llm.get_input_embeddings()(prompt.to(x_enc.device)) # (batch, prompt_token, dim)\n",
"\n",
" source_embeddings = self.mapping_layer(self.word_embeddings.permute(1, 0)).permute(1, 0)\n",
"\n",
" x_enc = x_enc.permute(0, 2, 1).contiguous()\n",
" enc_out, n_vars = self.patch_embedding(x_enc.to(torch.float32))\n",
" enc_out = self.reprogramming_layer(enc_out, source_embeddings, source_embeddings)\n",
" llm_enc_out = torch.cat([prompt_embeddings, enc_out], dim=1)\n",
" dec_out = self.llm(inputs_embeds=llm_enc_out).last_hidden_state\n",
" dec_out = dec_out[:, :, :self.d_ff]\n",
"\n",
" dec_out = torch.reshape(\n",
" dec_out, (-1, n_vars, dec_out.shape[-2], dec_out.shape[-1]))\n",
" dec_out = dec_out.permute(0, 1, 3, 2).contiguous()\n",
"\n",
" dec_out = self.output_projection(dec_out[:, :, :, -self.patch_nums:])\n",
" dec_out = dec_out.permute(0, 2, 1).contiguous()\n",
"\n",
" dec_out = self.normalize_layers(dec_out, 'denorm')\n",
"\n",
" return dec_out\n",
" \n",
" def calcute_lags(self, x_enc):\n",
" q_fft = torch.fft.rfft(x_enc.permute(0, 2, 1).contiguous(), dim=-1)\n",
" k_fft = torch.fft.rfft(x_enc.permute(0, 2, 1).contiguous(), dim=-1)\n",
" res = q_fft * torch.conj(k_fft)\n",
" corr = torch.fft.irfft(res, dim=-1)\n",
" mean_value = torch.mean(corr, dim=1)\n",
" _, lags = torch.topk(mean_value, self.top_k, dim=-1)\n",
" return lags\n",
" \n",
" def forward(self, windows_batch):\n",
" insample_y = windows_batch['insample_y']\n",
"\n",
" x = insample_y.unsqueeze(-1)\n",
"\n",
" y_pred = self.forecast(x)\n",
" y_pred = y_pred[:, -self.h:, :]\n",
" y_pred = self.loss.domain_map(y_pred)\n",
" \n",
" return y_pred\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"show_doc(TimeLLM)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"show_doc(TimeLLM.fit, name='TimeLLM.fit')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"show_doc(TimeLLM.predict, name='TimeLLM.predict')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Usage example"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| eval: false\n",
"from neuralforecast import NeuralForecast\n",
"from neuralforecast.models import TimeLLM\n",
"from neuralforecast.utils import AirPassengersPanel, augment_calendar_df\n",
"\n",
"from transformers import GPT2Config, GPT2Model, GPT2Tokenizer\n",
"\n",
"AirPassengersPanel, calendar_cols = augment_calendar_df(df=AirPassengersPanel, freq='M')\n",
"\n",
"Y_train_df = AirPassengersPanel[AirPassengersPanel.ds=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True) # 12 test\n",
"\n",
"gpt2_config = GPT2Config.from_pretrained('openai-community/gpt2')\n",
"gpt2 = GPT2Model.from_pretrained('openai-community/gpt2', config=gpt2_config)\n",
"gpt2_tokenizer = GPT2Tokenizer.from_pretrained('openai-community/gpt2')\n",
"\n",
"prompt_prefix = \"The dataset contains data on monthly air passengers. There is a yearly seasonality\"\n",
"\n",
"timellm = TimeLLM(h=12,\n",
" input_size=36,\n",
" llm=gpt2,\n",
" llm_config=gpt2_config,\n",
" llm_tokenizer=gpt2_tokenizer,\n",
" prompt_prefix=prompt_prefix,\n",
" batch_size=24,\n",
" windows_batch_size=24)\n",
"\n",
"nf = NeuralForecast(\n",
" models=[timellm],\n",
" freq='M'\n",
")\n",
"\n",
"nf.fit(df=Y_train_df, val_size=12)\n",
"forecasts = nf.predict(futr_df=Y_test_df)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Tests"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#| eval: false\n",
"\n",
"try:\n",
" from transformers import GPT2Config, GPT2Model, GPT2Tokenizer\n",
"except ImportError:\n",
" raise ImportError('The transformers library is required for Time-LLM to work')\n",
"\n",
"from neuralforecast import NeuralForecast\n",
"from neuralforecast.models import TimeLLM\n",
"\n",
"from neuralforecast.utils import AirPassengersPanel, augment_calendar_df\n",
"\n",
"AirPassengersPanel, calendar_cols = augment_calendar_df(df=AirPassengersPanel, freq='M')\n",
"\n",
"Y_train_df = AirPassengersPanel[AirPassengersPanel.ds=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True) # 12 test\n",
"\n",
"gpt2_config = GPT2Config.from_pretrained('openai-community/gpt2')\n",
"gpt2 = GPT2Model.from_pretrained('openai-community/gpt2', config=gpt2_config)\n",
"gpt2_tokenizer = GPT2Tokenizer.from_pretrained('openai-community/gpt2')\n",
"\n",
"prompt_prefix = \"The dataset contains data on monthly air passengers. There is a yearly seasonality\"\n",
"\n",
"timellm = TimeLLM(h=12,\n",
" input_size=36,\n",
" llm=gpt2,\n",
" llm_config=gpt2_config,\n",
" llm_tokenizer=gpt2_tokenizer,\n",
" prompt_prefix=prompt_prefix,\n",
" batch_size=24,\n",
" windows_batch_size=24)\n",
"\n",
"nf = NeuralForecast(\n",
" models=[timellm],\n",
" freq='M'\n",
")\n",
"\n",
"nf.fit(df=Y_train_df, val_size=12)\n",
"forecasts = nf.predict(futr_df=Y_test_df)\n",
"\n",
"# Asserts\n",
"assert 'TimeLLM' in forecasts.columns, \"The column TimeLLM does not exist. Something went wrong with the model\"\n",
"assert not forecasts['TimeLLM'].isnull().any(), \"Predictions contain NaN values.\""
]
}
],
"metadata": {
"kernelspec": {
"display_name": "python3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}