# Llama
彻底开源预训练大模型,本项目能够预训练出超出qwen2.5、llama3效果的大语言模型,为一些人工智能大厂的训练代码。
目前各种SOTA NLP大模型算法都与Llama高度相似,故Llama适合作为算法研发的蓝底,本项目首次从数据集、预训练到调优完全开源大模型算法代码,帮助全世界所有算法研究人员共同研究以促进人类文明进步。

## 论文
`Open and Efficient Foundation Language Models`
- https://arxiv.org/pdf/2302.13971
## 模型结构
Llama系列采用极简Decoder-only结构,Llama源自基本的transformer结构,主体为attention(QKV自点积)+ffn(全连接),最后外加一个softmax进行概率转换输出即可,为了使数据分布归一化方便训练收敛,在attention、ffn、softmax前分别再加一个RMS Norm。
总体而言,Llama系列模型结构高度相似,llama1在GPT基础上引入旋转矩阵解决之前绝对位置编码复杂的问题,引入RMSNorm解决LayerNorm计算量大的问题,llama2在llama1的基础上引入GQA进一步减小计算量, llama3在llama2的基础上引入蒸馏、剪枝、量化等再进一步减小计算量,模型中其它模块(如flash-attn2、KV cache)只是增加训练推理效率的模块,本项目兼容Llama系列,以下分别为读者提供Llama的简图和详图帮助读者全方位理解。
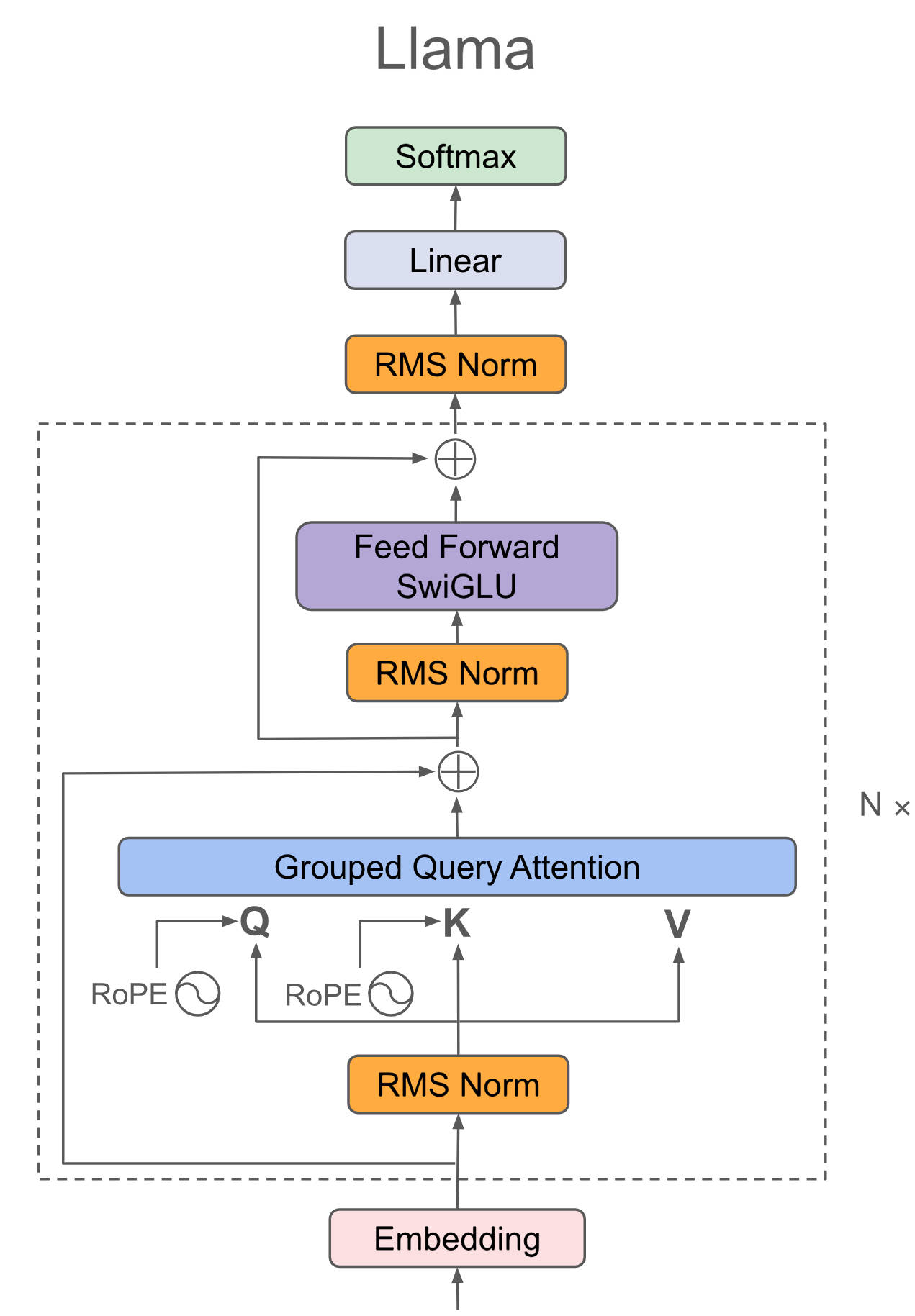
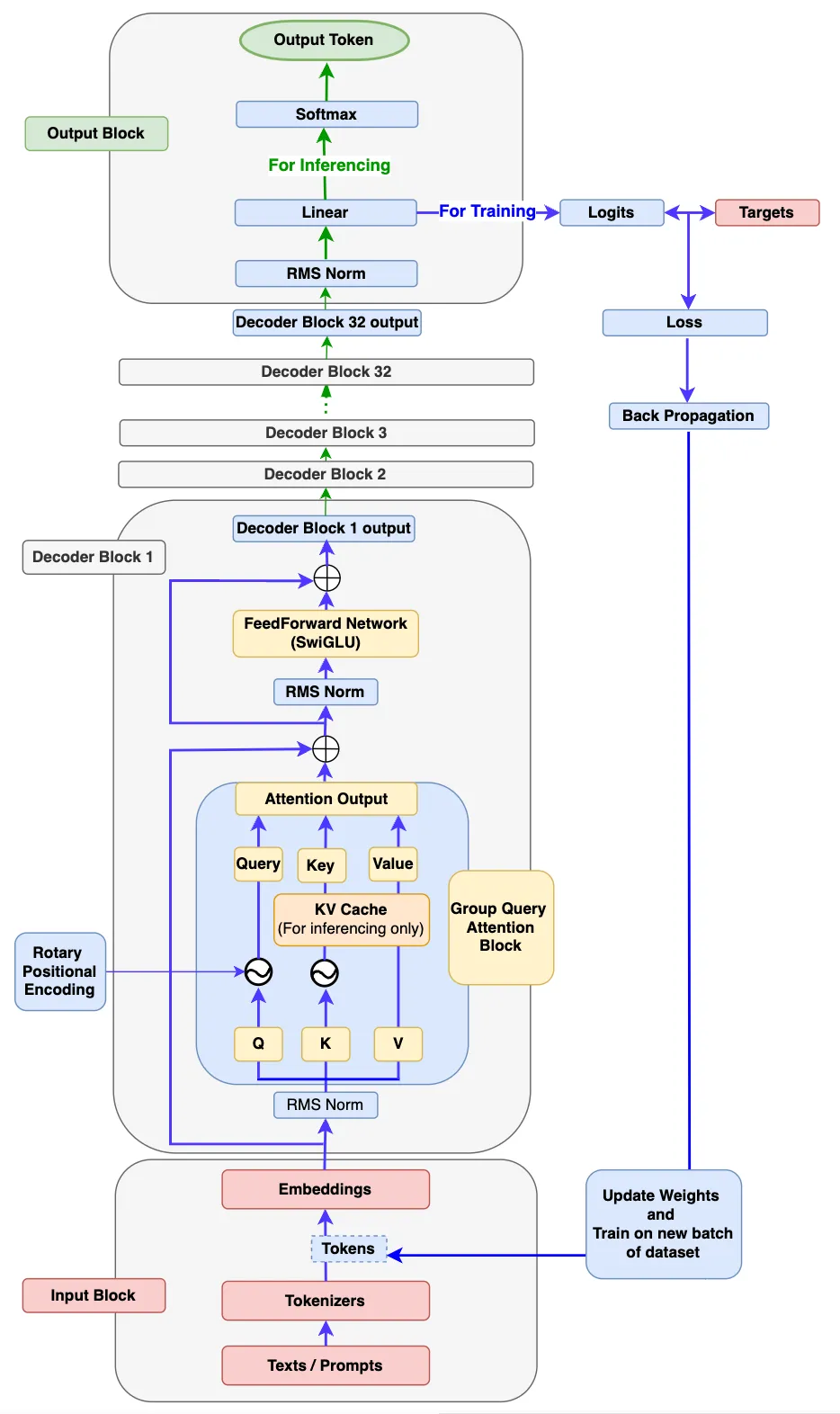
Facebook官网最原始的llama3请参考代码:[`Llama3`](https://github.com/meta-llama/llama3/blob/main/llama/model.py),本项目中的llama结构在ffn等层上略有修改,其它不同点只是模型规模参数和实现方式,读者若需要纯原版llama3可自行修改。
## 算法原理
整个Llama算法都体现出大道至简的思想。
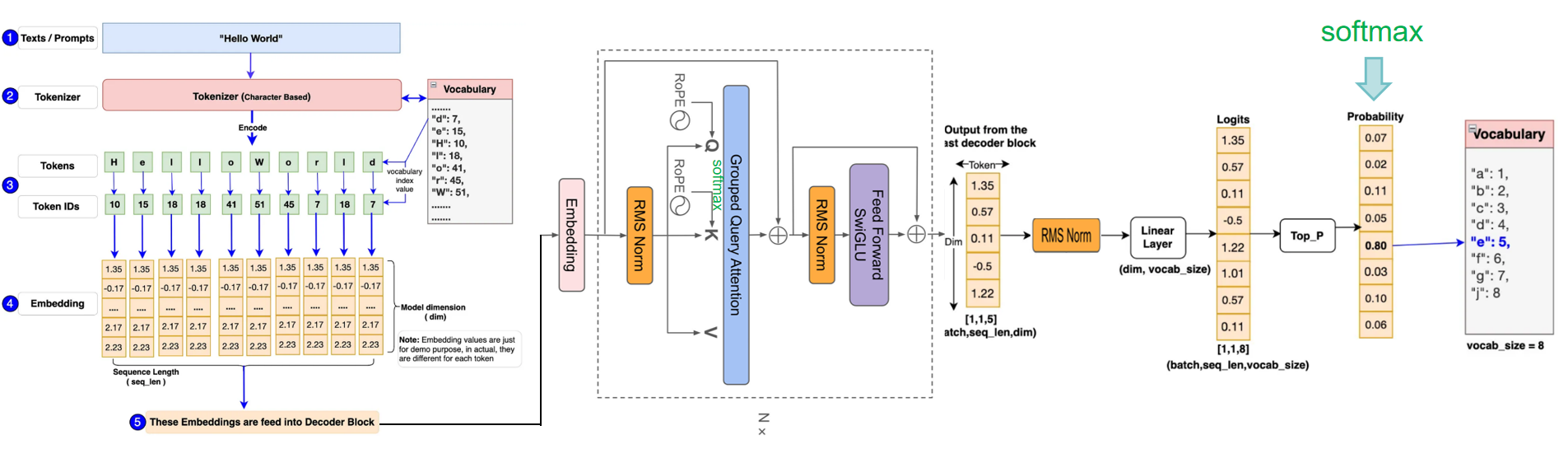
原理采用极简的纯矩阵计算,llama将输入embedding(将语句根据词汇量和词的位置、属性转换成数字化矩阵)后放入attention+ffn等提取特征,最后利用Softmax将解码器最后一层产生的未经归一化的分数向量(logits)转换为概率分布,其中每个元素表示生成对应词汇的概率,这使得模型可以生成一个分布,并从中选择最可能的词作为预测结果,然后一个字一个预测出来就是咱们看到的对话生成效果。
损失函数采用最简单方便的CE(cross entropy) loss便可。
## 环境配置
```
mv nanotron_pytorch nanotron # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-py3.10-dtk24.04.3-ubuntu20.04
# 为以上拉取的docker的镜像ID替换,本镜像为:b272aae8ec72
docker run -it --shm-size=64G -v $PWD/nanotron:/home/nanotron -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name llama bash
cd /home/nanotron
pip install -r requirements.txt
pip install -e . #安装nanotron==0.4库
pip install whl/rotary_emb-0.1.0+das.opt2.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl # 安装rotary_emb==0.1.0
```
### Dockerfile(方法二)
```
cd cd /home/nanotron/docker
docker build --no-cache -t llama:latest .
docker run --shm-size=64G --name llama -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../nanotron:/home/nanotron -it llama bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
cd /home/nanotron
pip install -e . #安装nanotron==0.4库
pip install whl/rotary_emb-0.1.0+das.opt2.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl # 安装rotary_emb==0.1.0
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.hpccube.com/tool/
```
DTK驱动:dtk24.04.3
python:python3.10
torch:2.3.0
torchvision:0.18.1
torchaudio:2.1.2
triton:2.1.0
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.3.0
xformers:0.0.25
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/nanotron
pip install -r requirements.txt
pip install -e . #安装nanotron==0.4库
pip install whl/rotary_emb-0.1.0+das.opt2.dtk24043-cp310-cp310-manylinux_2_28_x86_64.whl # 安装rotary_emb==0.1.0
```
## 数据集
实验性的迷你数据集[`openwebtext-10k`](./openwebtext-10k.tar.xz)源于openwebtext,仅供试验,实际训练中读者可在HF下载`*.parquet`开源数据集使用,或将自己的数据集按HF的官方说明制作成此类格式使用。
数据集在训练之前需要用tokenlizer处理成NLP模型的输入tokens,Facebook官方采用tiktoken库制作tockens便可训练出SOTA模型:[`llama3 tokenizer`](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py),本项目可根据读者需求自由选择各种HF的开源tokenlizer,将其填写在`config`的`.yaml`中便可自动被项目调用。
`openwebtext-10k`用于tiny llama预训练示例,[`fineweb-edu-dedup`](http://113.200.138.88:18080/aidatasets/argilla-warehouse/fineweb-edu-dedup-filtered.git) 用于smollm预训练示例(HF公司自研人工智能模型),从SCNet快速下载通道下载后重命名即可,原始`fineweb-edu-dedup`数据(`*.parquet`)可通过以下命令转换成`fineweb-edu-dedup-ds`数据(`*.ds`),`datatrove`制作`*.ds`数据参考[`Nanosets`](./docs/nanoset.md):
```
sh convert_data_to_ds.sh
```
```
datatrove库Tokenizer bug solve: Exception: Is a directory (os error 21)
vim /usr/local/lib/python3.10/site-packages/datatrove/utils/tokenization.py , line 19
modify:
# return Tokenizer.from_file(name_or_path)
return Tokenizer.from_file(name_or_path + "/tokenizer.json")
```
```
datasets库load_dataset bug solve: OSError: Not enough disk space.
vim /usr/local/lib/python3.10/site-packages/datatrove/pipeline/readers/huggingface.py , line 95
modify:
def run(self, data: DocumentsPipeline = None, rank: int = 0, world_size: int = 1) -> DocumentsPipeline:
from datasets import load_dataset # type: ignore
to:
def run(self, data: DocumentsPipeline = None, rank: int = 0, world_size: int = 1) -> DocumentsPipeline:
from datasets import load_dataset # type: ignore
import datasets
datasets.builder.has_sufficient_disk_space = lambda needed_bytes, directory='.': True
```
项目中已包含`tokenlizer`:[`dummy`](./robot-test/dummy-tokenizer-wordlevel) 、[`cosmo2`](./HuggingFaceTB/cosmo2-tokenizer) ,其它tokenizer(如:llama3)根据读者需求可自行下载。
预训练数据的完整目录结构如下:
```
/home/nanotron
├── openwebtext-10k.tar.xz
├── stas/openwebtext-10k
├── dataset_infos.json
├── openwebtext-10k.py
├── process.txt
└── README.md
├── datasets/fineweb-edu-dedup
├── train-00000-of-00002.parquet
├── train-00001-of-00002.parquet
└── datasets/fineweb-edu-dedup-ds
├── 00000_unshuffled.ds
├── 00000_unshuffled.ds.index
├── 00000_unshuffled.ds.metadata
...
```
`备注:`本项目灵活度大,仅适于算法基础较好的研究人员使用,对算法基础和代码基础有一定的需求,其它人员可能存在一定的上手门槛,可参考光源上预训练项目[`allamo_pytorch`](http://developer.sourcefind.cn/codes/modelzoo/allamo_pytorch.git)中的简单预训练代码llama3__scratch进行上手学习。
## 训练
### 单机多卡
本项目的最大特点是完全开源、营造自由科研环境,项目中的算法、模型读者可自由修改、研发以提出自己的算法来为社会做贡献,在[`llama`](./src/nanotron/models/llama.py)修改模型文件,但为了方便介绍,本步骤说明以小规模模型tiny llama作为示例:
```
cd /home/nanotron
sh train.sh # 不同卡数的训练方式参照train.sh中的说明,完整规模llama3的训练方式可参考train.sh中的说明。
# 遇到Do you wish to run the custom code? [y/N],填y。
# 其它功能正在优化中,欢迎共同优化和拓展。
```
```
datasets库load_dataset bug solve: OSError: Not enough disk space.
vim /home/nanotron/src/nanotron/dataloader.py , line 22
modify:
try:
import datasets
to:
try:
import datasets
datasets.builder.has_sufficient_disk_space = lambda needed_bytes, directory='.': True
```
Facebook原版llama3的模型参数可参考[`Llama-3.1-8B`](./checkpoints/Nanotron-Llama-3.1-8B/model_config.json)、[`Llama-3.2-3B`](./checkpoints/Nanotron-Llama-3.2-3B/model_config.json),这两个参数文件根据以下命令可获取:
```
sh convert_hf_to_nanotron.sh # Llama系列的基础模型皆支持转换
# 若已预训练完成某个模型,可转换成HF格式权重进行发布,以及用其它开源库继续微调,不同模型请读者根据具体参数修改此文件中的相应参数进行转换。
# sh convert_nanotron_to_hf.sh
```
为了方便读者借鉴HF官方的预训练方式,项目中还提供了`smollm`的预训练示例,参考文档[`pre-training`](https://github.com/huggingface/smollm/tree/main/pre-training):
```
sh train_smollm1_135M_demo.sh # Demo仅供试用,细节请自行研究,若读者具备超算集群,可参照launch.slurm编写自己具体的slurm脚本。
```
`Tips :`通过本项目获得自主研发模型的预训练权重后,后续微调模型放在[`LLaMA-Factory`](https://github.com/hiyouga/LLaMA-Factory.git)、[`ollama`](https://github.com/ollama/ollama.git)、公开「后训练」一切的[`open-instruct`](https://github.com/allenai/open-instruct.git)等工具中进行更方便。
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## 推理
```
sh infer.sh # 以checkpoints/10中的权重作为示例,其他权重请参照此示例修改权重路径。
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## result
由于示例训练数据较少、模型为简化模型且训练时间短,此推理仅供参考显示效果,以方便读者了解项目使用方法,根据官方示例所得:
`输入: `
```
input: [CLS] the [UNK] [UNK] [UNK] is [SEP]
```
`输出:`
```
generation: [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP] [SEP]
```
上述重复字符为示例Demo的tokenlizer过于简单导致的正常现象,更换一个复杂的tokenlizer便可输出正常结果,例如使用`cosmo2-tokenizer`预训练:
```
CUDA_DEVICE_MAX_CONNECTIONS=1 torchrun --nproc_per_node=4 run_train.py --config-file examples/config_tiny_llama_cosmo2tokenizer.yaml
```
由此可见,不同tokenlizer会对训练结果造成明显差别,故建议实际训练中选择设计更好的tokenlizer。
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`制造,广媒,金融,能源,医疗,家居,教育`
## 预训练权重
预训练权重快速下载中心:[SCNet AIModels](http://113.200.138.88:18080/aimodels) ,项目中的预训练权重可从快速下载通道下载:[Llama-3.1-8B](http://113.200.138.88:18080/aimodels/meta-llama/Meta-Llama-3.1-8B.git) 、[Llama-3.2-3B](http://113.200.138.88:18080/aimodels/meta-llama/Llama-3.2-3B.git) 。
Hugging Face下载地址为:[meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) 、[meta-llama/Llama-3.2-3B](https://huggingface.co/meta-llama/Llama-3.2-3B)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/nanotron_pytorch.git
## 参考资料
- https://github.com/huggingface/nanotron.git
- https://github.com/meta-llama/llama3.git
- https://github.com/hiyouga/LLaMA-Factory.git
- https://github.com/ollama/ollama.git
- https://github.com/allenai/open-instruct.git