# mPLUG-DocOwl
mPLUG-DocOwl 1.5 是阿里巴巴mPLUG团队在多模态文档图片理解领域的最新开源工作,在10个文档理解benchmark上达到最优效果,5个数据集上提升超过10个点,部分数据集上超过智谱17.3B的CogAgent,在DocVQA上达到82.2的效果。
## 论文
- [mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding](https://arxiv.org/abs/2403.12895)
## 模型结构
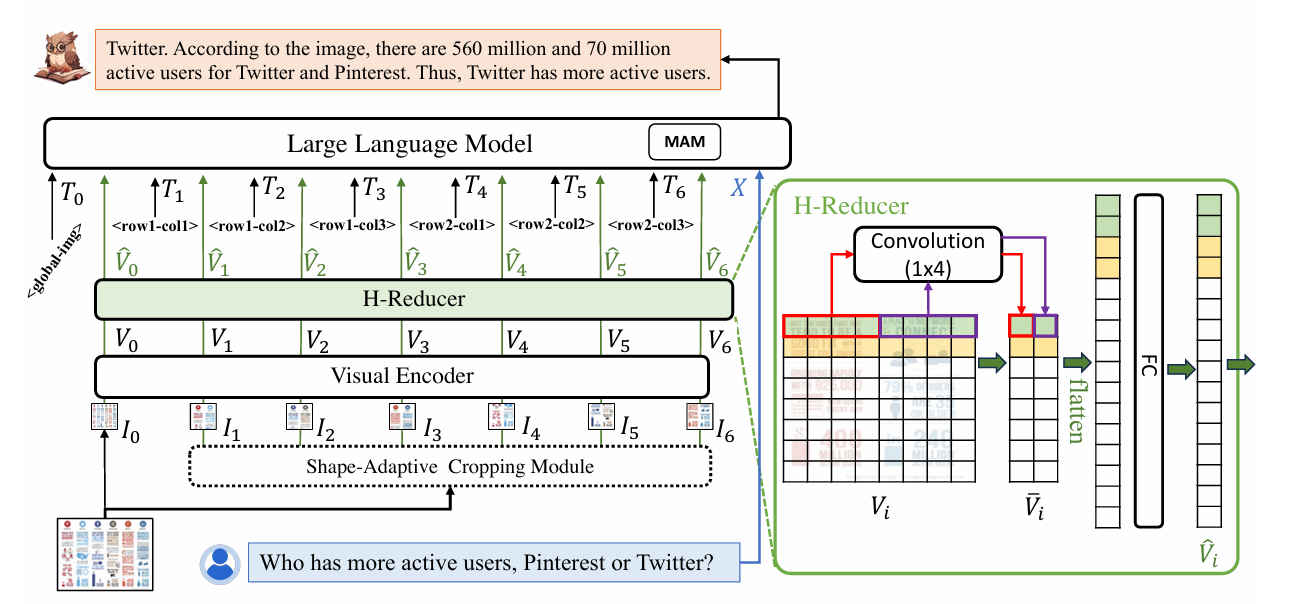
DocOwl 1.5强调文档图片理解中对于“文档结构”理解的重要性,提出对于所有文字信息丰富的图片进行统一的结构学习。DocOwl 1.5延续该团队前序工作DocOwl以及UReader处理高分辨率文档图片的方式,采用一个形状适应的切图模块将高分辨率图片切为多个大小一致的子图。为了更好的将图片的文字布局信息传递给LLM,同时避免在处理高分辨率文档图片时视觉特征过长,DocOwl 1.5提出来一个基于卷积的连接结构H-Reducer,其在水平方向上混合4个视觉特征,模型结构如下图所示。
## 算法原理
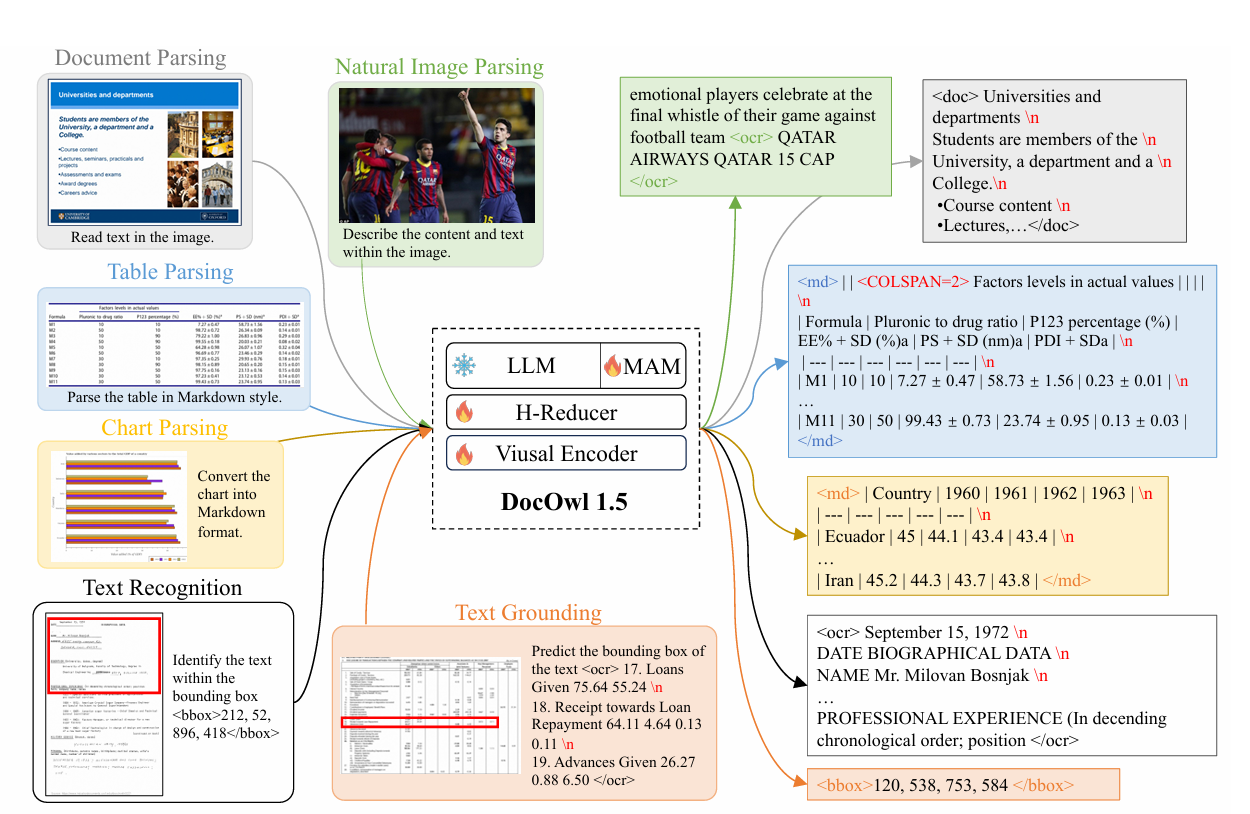
为了进行统一的文档结构学习,该工作基于开源数据集构建了一个全面的结构化解析数据集DocStruct4M。对于文档图片或者网页截图,主要采用空格和换行表示文字布局;对于表格,其改进的Markdown语法既能表示跨行跨列,又相比html缩减了大量标签;对于图表,同样采用markdown来表示其数学特征,并且限定数值的有效位以保证其在图片中视觉可见;对于自然图,采用描述加上ocr文本的形式。
## 环境配置
### Docker(方法一)
[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=64G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name mplug-doclocal bash
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Dockerfile(方法二)
```
cd /path/your_code_data/
docker build --no-cache -t mplug-doclocal:latest .
docker run --shm-size=64G --name mplug-doclocal -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it mplug-doclocal bash
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.1
python:3.10
torch:2.1
torchvision: 0.16.0
deepspped: 0.12.3
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
conda create -n mplug-doclocal python=3.10
conda activate mplug-doclocal
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple
```
## 数据集
迷你数据集 [mini DocLocal4K](./DocLocal4K/mini_imges.jsonl)
完整[DocLocal4K](https://www.modelscope.cn/datasets/iic/DocLocal4K)数据集下载路径
预训练需要准备你的训练数据,需要将所有样本放到一个列表中并存入json文件中。每个样本对应一个字典,包含以下信息,示例如下所示:用于正常训练的完整数据集请按此目录结构进行制备:
```
{"image": ["./imgs/DUE_Benchmark/DocVQA/pngs/xnbl0037_1.png"], "messages": [{"role": "user", "content": "<|image|>what is the date mentioned in this letter?"}, {"role": "assistant", "content": "1/8/93"}], "task_name": "qa_sft", "dataset_name": "DocVQA"}
```
数据集目录结构如下:
```
── DocLocal4K
│ ├── imgs
│ │ ├── ChartQA
│ │ │
│ │ ├── DUE_Benchmark
│ │ │
│ │ ├── TextVQA
│ │ │
│ │ └── VisualMRC
│ ├── dataset_infos.json
│ ├── mini_imges.jsonl
│ ├── text_grounding.jsonl
│ ├── text_recognition.jsonl
│ └── README.md
```
## 训练
根据实际情况在脚本中修相关路径,快速测试data_path可使用./DocLocal4K/mini_imges.jsonl,整体测试可选./DocLocal4K/text_recognition.jsonl、./DocLocal4K/text_grounding.jsonl
--deepspeed
--model_name_or_path
--data_path
--image_folder
--output_dir
### 单机多卡
```
sh finetune_docowl_lora_dcu.sh
```
## 推理
### 单机单卡
mPLUG-DocOwl 1.5 对英文文档表现优异,中文后续优化。
若出现以下报错,点击Regenerate后尝试:
`NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.`
### 指令问答
```
python docowl_infer.py
```
## result
### 指令问答
```
image: './image/pic.jpg'
query: '详细描述这张图片'
answer: 'christmas decorations in a store window 1 '
```
```
image: './image/car.jpg'
query: '详细描述这张图片'
answer: 'A blue license plate with the characters A KC087 '
```
### 精度
测试数据: [mini DocLocal4K](./DocLocal4K/mini_imges.jsonl),使用的加速卡:K100/A800。
| device | train_loss |
| :------: | :------: |
| K100*2 | 10.3234 |
| A800*2 | 10.3188 |
## 应用场景
### 算法类别
`OCR`
### 热点应用行业
`金融,教育,政府,交通`
## 预训练权重
- [iic/DocOwl1.5-Omni](https://www.modelscope.cn/models/iic/DocOwl1.5-Omni/)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/mplug-docowl_pytorch.git
## 参考资料
- [iic/DocOwl1.5-Omni 魔搭](https://www.modelscope.cn/models/iic/DocOwl1.5-Omni/)
- [mPLUG-DocOwl 1.5 github](https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5)