# MooER_pytorch
## 论文
- https://arxiv.org/abs/2408.05101
## 模型结构
MooER模型是一个由摩尔线程开发的、基于大语言模型(Large Language Model,LLM)的语音识别和语音翻译系统。模型结构如图:
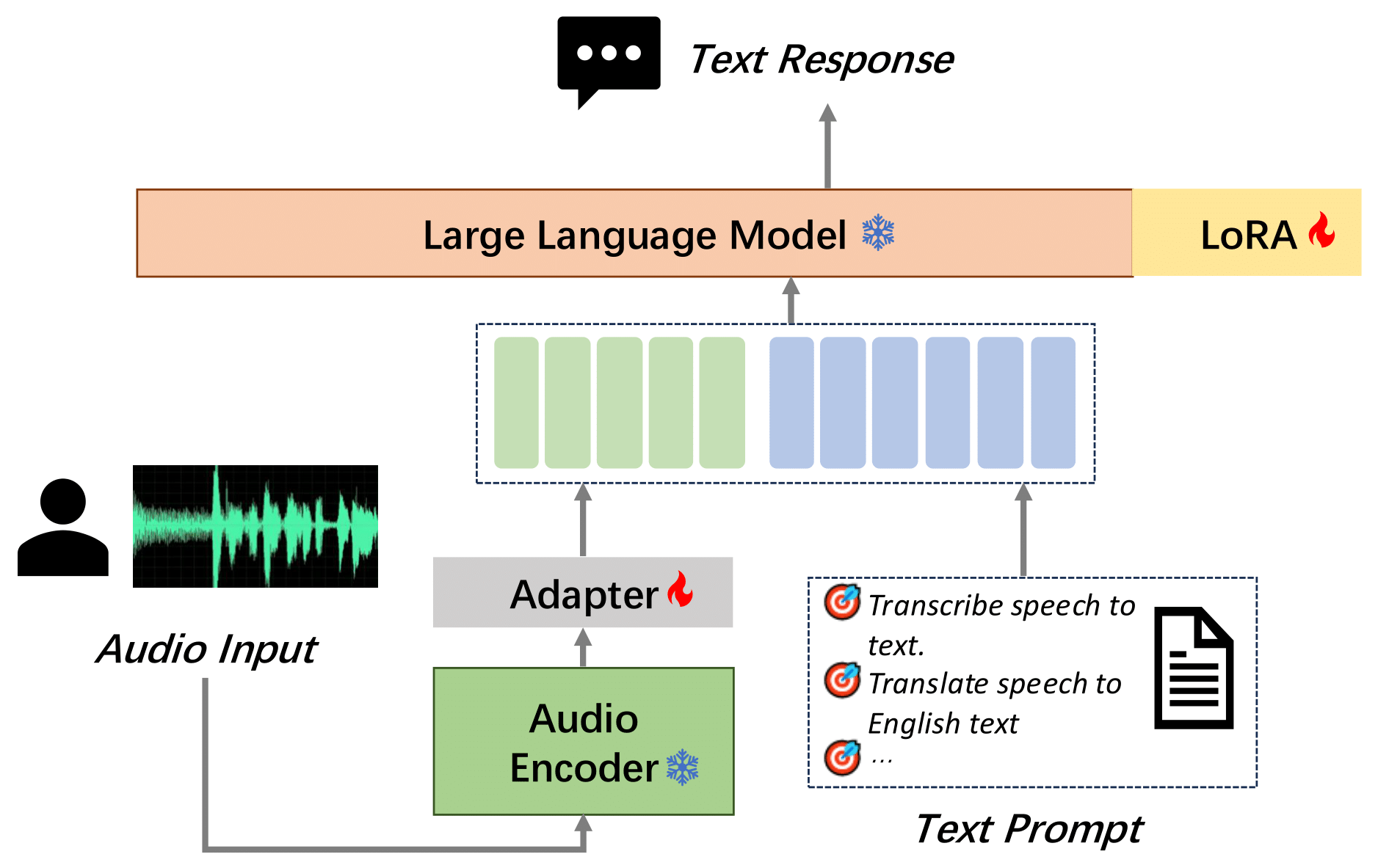
## 算法原理
通过摩耳框架,您可以基于大语言模型(Large Language Model,LLM),以端到端的方式,将输入语音自动转录为文本(即语音识别),并将其翻译为其它语言(即语音翻译)
## 环境配置
### Docker(方法一)
此处提供[光源](https://sourcefind.cn/#/main-page)拉取镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.2-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
# 安装依赖项:
pip install -r requirements.txt
```
### Dockerfile(方法二)
此处提供Dockerfile的使用方法
```
cd ./docker
docker build --no-cache -t mooer:latest
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
pip install -r requirements.txt
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk24,04,2
Python:3.10
touch:2.3.0
torchaudio:2.1.2
```
Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应
其它非深度学习库参照requirements.txt安装:
```
pip install -r requirements.txt
```
## 数据集
无
## 训练
无
## 推理
1:首先从[ModelScope](https://modelscope.cn/models/MooreThreadsSpeech/MooER-MTL-5K)或者[HF-Mirror](https://hf-mirror.com/mtspeech/MooER-MTL-5K)下载官方提供的预训练模型。
```
# 使用ModelScope
git lfs clone https://modelscope.cn/models/MooreThreadsSpeech/MooER-MTL-5K
# 使用HF-Mirror
git lfs clone https://hf-mirror.com/mtspeech/MooER-MTL-5K
```
将下载后的文件放置在 `pretrained_models` 文件夹中。
```shell
cp MooER-MTL-5K/* pretrained_models
```
2:下载 [`Qwen2-7B-Instruct`](https://modelscope.cn/models/qwen/qwen2-7b-instruct) :
```
# 使用ModelScope
git lfs clone https://modelscope.cn/models/qwen/qwen2-7b-instruct
# 使用HuggingFace
git lfs clone https://hf-mirror.com/Qwen/Qwen2-7B-Instruct
```
将下载后的文件放在 `pretrained_models/Qwen2-7B-Instruct` 文件夹中。
最后,确保下载的文件按照下面的文件结构放置。模型文件损坏或安放位置不正确会导致运行出错。
```text
./pretrained_models/
|-- paraformer_encoder
| |-- am.mvn
| `-- paraformer-encoder.pth
|-- asr
| |-- adapter_project.pt
| `-- lora_weights
| |-- README.md
| |-- adapter_config.json
| `-- adapter_model.bin
|-- ast
| |-- adapter_project.pt
| `-- lora_weights
| |-- README.md
| |-- adapter_config.json
| `-- adapter_model.bin
|-- asr_ast_mtl
| |-- adapter_project.pt
| `-- lora_weights
| |-- README.md
| |-- adapter_config.json
| `-- adapter_model.bin
|-- Qwen2-7B-Instruct
| |-- model-00001-of-00004.safetensors
| |-- model-00002-of-00004.safetensors
| |-- model-00003-of-00004.safetensors
| |-- model-00004-of-00004.safetensors
| |-- model.safetensors.index.json
| |-- config.json
| |-- configuration.json
| |-- generation_config.json
| |-- merges.txt
| |-- tokenizer.json
| |-- tokenizer_config.json
| |-- vocab.json
| |-- LICENSE
| `-- README.md
|-- README.md
`-- configuration.json
```
3:最后,在上述工作准备好后可以执行代码进行推理:
在`demo`文件夹下提供了一个示例语音文件用于测试。
首先设置环境变量:
```
# 设置环境变量
export PYTHONIOENCODING=UTF-8
export LC_ALL=C
export PYTHONPATH=$PWD/src:$PYTHONPATH
```
- 同时进行ASR和AST:
```
# 使用指定的音频文件
python inference.py --wav_path /path/to/your_audio_file
```
上述命令会调用一个多任务Mooer大模型,同时输出语音识别和语音翻译的结果。如果运行成功,将在终端看到如下结果。
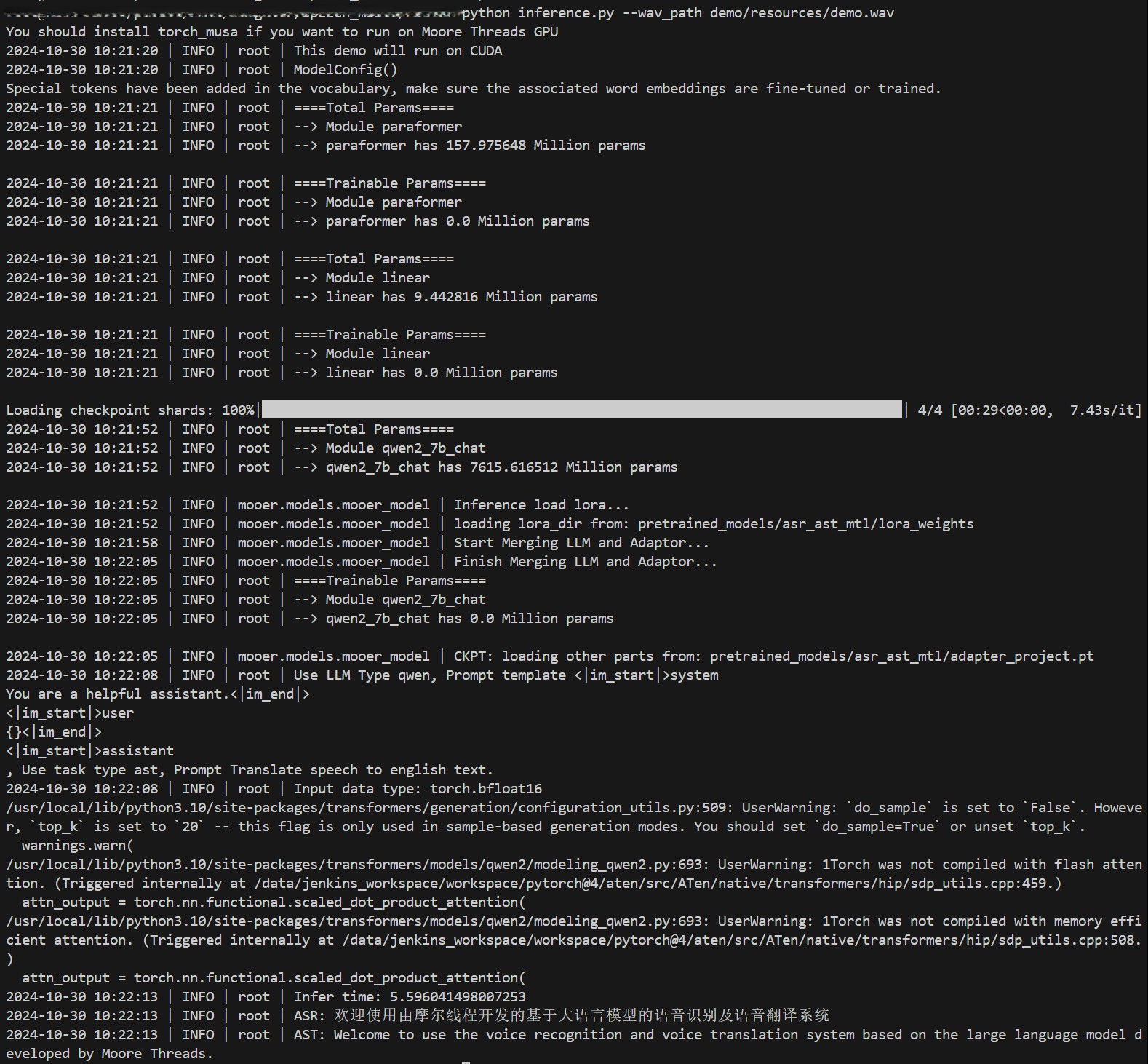
- 指定语音识别模型,仅输出识别结果:
```
python inference.py --task asr \
--cmvn_path pretrained_models/paraformer_encoder/am.mvn \
--encoder_path pretrained_models/paraformer_encoder/paraformer-encoder.pth \
--llm_path pretrained_models/Qwen2-7B-Instruct \
--adapter_path pretrained_models/asr/adapter_project.pt \
--lora_dir pretrained_models/asr/lora_weights \
--wav_path /path/to/your_audio_file
```
上述命令会仅输出语音识别的结果。如果运行成功,将在终端看到如下结果。
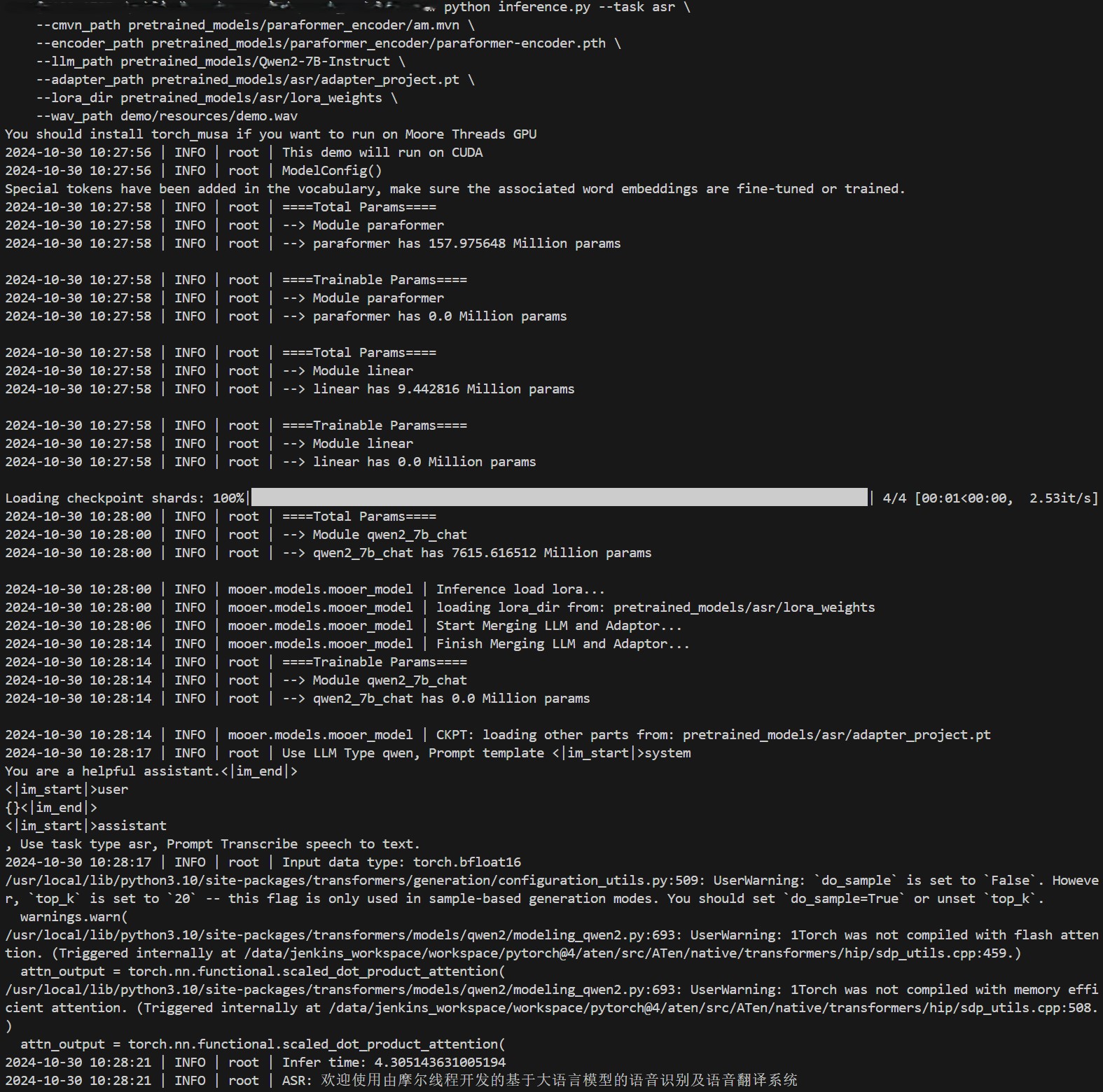
- 指定语音翻译模型,仅输出中译英结果
```
python inference.py --task ast \
--cmvn_path pretrained_models/paraformer_encoder/am.mvn \
--encoder_path pretrained_models/paraformer_encoder/paraformer-encoder.pth \
--llm_path pretrained_models/Qwen2-7B-Instruct \
--adapter_path pretrained_models/ast/adapter_project.pt \
--lora_dir pretrained_models/ast/lora_weights \
--wav_path /path/to/your_audio_file
```
上述命令会仅输出语音翻译的结果。如果运行成功,将在终端看到如下结果。
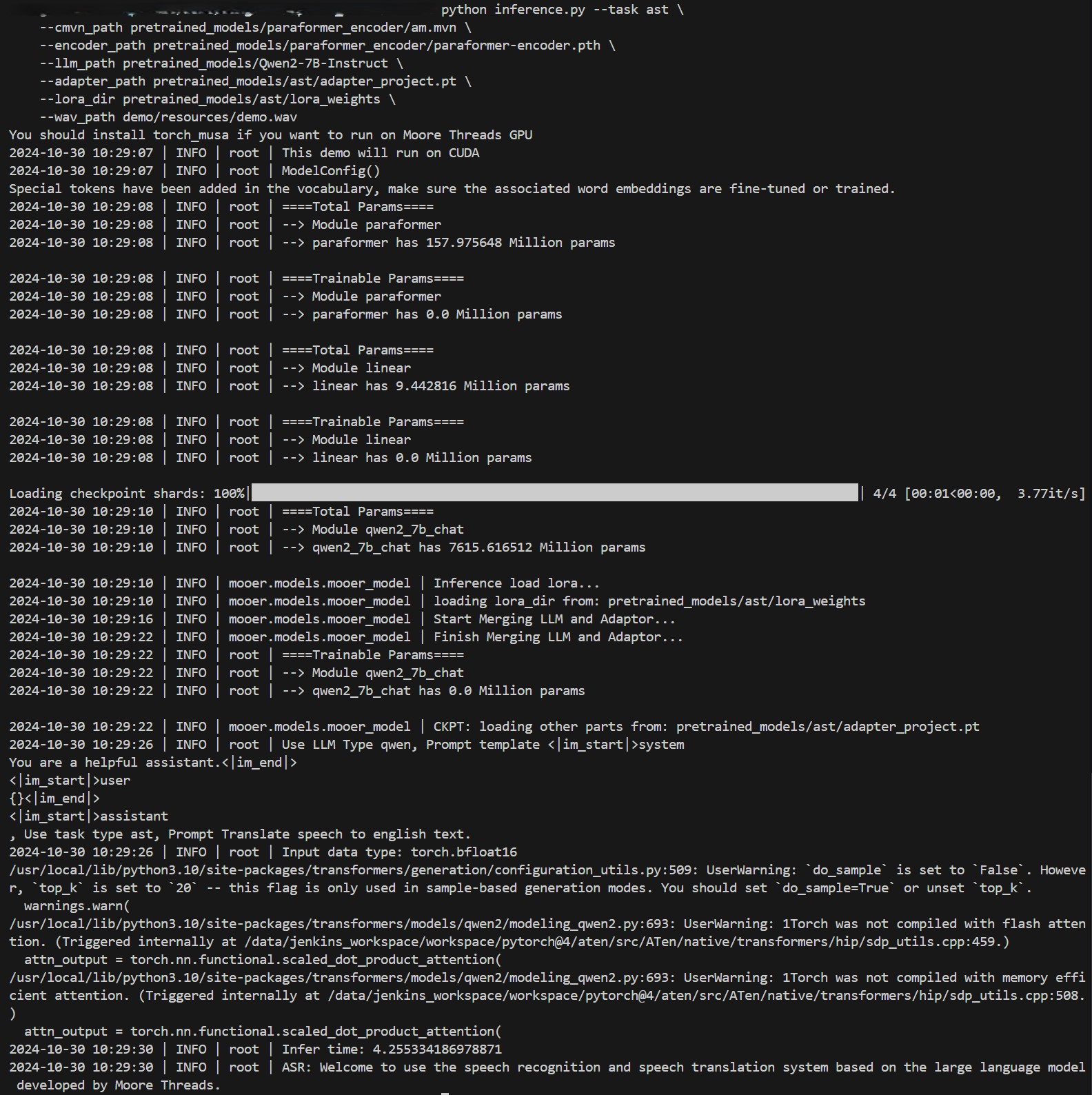
## 应用场景
### 算法分类
语音识别、语音翻译
### 热点应用行业
语音识别、语音翻译、教育、医疗
## 源码仓库及问题反馈
https://developer.sourcefind.cn/codes/modelzoo/mooer_pytorch
## 参考资料
https://github.com/MooreThreads/MooER