# MooER
## 论文
- https://arxiv.org/abs/2408.05101
## 模型结构
MooER模型是一个由摩尔线程开发的、基于大语言模型(Large Language Model,LLM)的语音识别和语音翻译系统。模型结构如图:
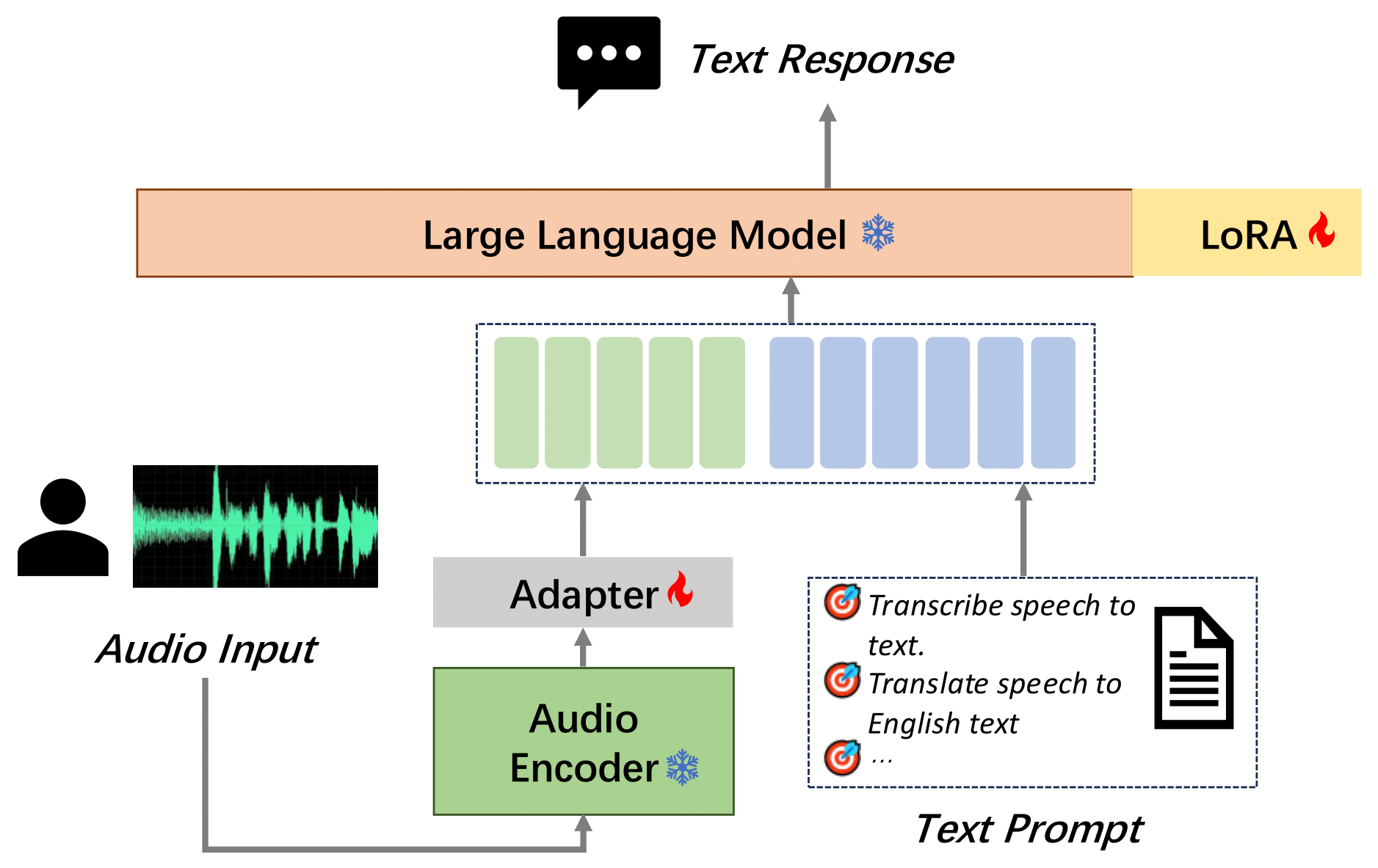
## 算法原理
通过摩耳框架,可以基于大语言模型(Large Language Model,LLM),以端到端的方式,将输入语音自动转录为文本(即语音识别),并将其翻译为其它语言(即语音翻译)。
## 环境配置
### Docker(方法一)
此处提供[光源](https://sourcefind.cn/#/main-page)拉取镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.2-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
# 安装依赖项:
pip install -r requirements.txt
```
### Dockerfile(方法二)
此处提供Dockerfile的使用方法
```
cd ./docker
docker build --no-cache -t mooer:latest
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
pip install -r requirements.txt
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk24.04.2
Python:3.10
torch:2.3.0
torchaudio:2.1.2
```
Tips:以上dtk驱动、python、pytorch等DCU相关工具版本需要严格一一对应
其它非深度学习库参照requirements.txt安装:
```
pip install -r requirements.txt
```
## 数据集
无
## 训练
无
## 推理
1:下载预训练模型MooER-MTL-5K,推荐使用scnet快速下载链接[MooER-MTL-5K](http://113.200.138.88:18080/aimodels/mooer-mtl-5k-asr),官方下载地址[ModelScope](https://modelscope.cn/models/MooreThreadsSpeech/MooER-MTL-5K)或者[HF-Mirror](https://hf-mirror.com/mtspeech/MooER-MTL-5K)。
```
将下载后的文件放置在 `pretrained_models` 文件夹中。
cp MooER-MTL-5K/* pretrained_models
```
2:下载Qwen2-7B-Instruct,推荐使用scnet快速下载链接 [`Qwen2-7B-Instruct`](http://113.200.138.88:18080/aimodels/Qwen2-7B-Instruct)官方下载地址[ModelScope](https://modelscope.cn/models/qwen/qwen2-7b-instruct)或者[HF-Mirror](https://hf-mirror.com/Qwen/Qwen2-7B-Instruct)。
将下载后的文件放在 `pretrained_models/Qwen2-7B-Instruct` 文件夹中。
最后,确保下载的文件按照下面的文件结构放置。模型文件损坏或安放位置不正确会导致运行出错。
```text
./pretrained_models/
|-- paraformer_encoder
| |-- am.mvn
| `-- paraformer-encoder.pth
|-- asr
| |-- adapter_project.pt
| `-- lora_weights
| |-- README.md
| |-- adapter_config.json
| `-- adapter_model.bin
|-- ast
| |-- adapter_project.pt
| `-- lora_weights
| |-- README.md
| |-- adapter_config.json
| `-- adapter_model.bin
|-- asr_ast_mtl
| |-- adapter_project.pt
| `-- lora_weights
| |-- README.md
| |-- adapter_config.json
| `-- adapter_model.bin
|-- Qwen2-7B-Instruct
| |-- model-00001-of-00004.safetensors
| |-- model-00002-of-00004.safetensors
| |-- model-00003-of-00004.safetensors
| |-- model-00004-of-00004.safetensors
| |-- model.safetensors.index.json
| |-- config.json
| |-- configuration.json
| |-- generation_config.json
| |-- merges.txt
| |-- tokenizer.json
| |-- tokenizer_config.json
| |-- vocab.json
| |-- LICENSE
| `-- README.md
|-- README.md
`-- configuration.json
```
3:最后,在上述工作准备好后可以执行代码进行推理:
在`demo`文件夹下提供了一个示例语音文件用于测试。
首先设置环境变量:
```
# 设置环境变量
export PYTHONIOENCODING=UTF-8
export LC_ALL=C
export PYTHONPATH=$PWD/src:$PYTHONPATH
```
**同时进行ASR和AST:**
```
# 使用指定的音频文件
python inference.py --wav_path /path/to/your_audio_file
```
**指定语音识别模型,仅输出识别结果:**
```
python inference.py --task asr \
--cmvn_path pretrained_models/paraformer_encoder/am.mvn \
--encoder_path pretrained_models/paraformer_encoder/paraformer-encoder.pth \
--llm_path pretrained_models/Qwen2-7B-Instruct \
--adapter_path pretrained_models/asr/adapter_project.pt \
--lora_dir pretrained_models/asr/lora_weights \
--wav_path /path/to/your_audio_file
```
**指定语音翻译模型,仅输出中译英结果**
```
python inference.py --task ast \
--cmvn_path pretrained_models/paraformer_encoder/am.mvn \
--encoder_path pretrained_models/paraformer_encoder/paraformer-encoder.pth \
--llm_path pretrained_models/Qwen2-7B-Instruct \
--adapter_path pretrained_models/ast/adapter_project.pt \
--lora_dir pretrained_models/ast/lora_weights \
--wav_path /path/to/your_audio_file
```
## result
**ASR和AST**
```
ASR: 欢迎使用由摩尔线程开发的基于大语言模型的语音识别及语音翻译系统
AST: Welcome to use the voice recognition and voice translation system based on the large language model developed by Moore Threads.
```
**ASR**
```
ASR: 欢迎使用由摩尔线程开发的基于大语言模型的语音识别及语音翻译系统
```
**AST**
```
AST: Welcome to use the voice recognition and voice translation system based on the large language model developed by Moore Threads.
```
### 精度
无
## 应用场景
### 算法分类
`语音识别,语音翻译`
### 热点应用行业
`教育,医疗,科研`
## 源码仓库及问题反馈
https://developer.sourcefind.cn/codes/modelzoo/mooer_pytorch
## 参考资料
https://github.com/MooreThreads/MooER