
v1.0
Showing

32.6 KB

111 KB

42.8 KB

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

67.1 KB
{kind=link}

214 KB
{kind=link}

267 KB
doc/algorithm.png
0 → 100644
{kind=link}
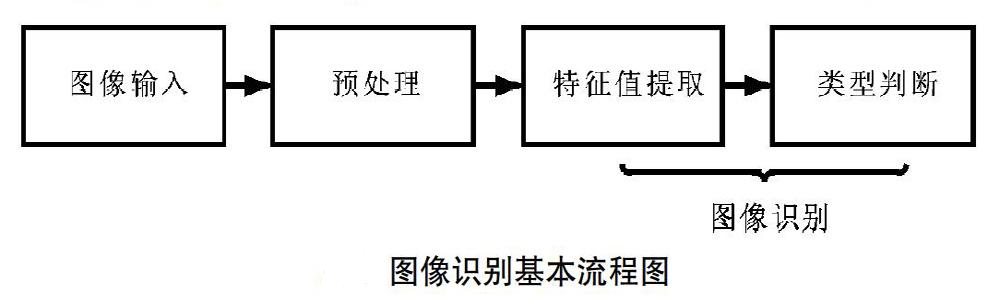
76.7 KB
doc/structure.png
0 → 100644
{kind=link}
137 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
model.properties
0 → 100644
model_config.py
0 → 100644
predict.py
0 → 100644
readme_origin.md
0 → 100644
requirements.txt
0 → 100644
{kind=link}

114 KB
{kind=link}

99.5 KB
train.py
0 → 100644
train.sh
0 → 100644