Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
MLPerf_BERT_paddle
Commits
141fb0e0
"docs/vscode:/vscode.git/clone" did not exist on "fee37d9e8da009534765768d0a09224914ad8f61"
Commit
141fb0e0
authored
Oct 10, 2023
by
liangjing
Browse files
unpdat
parent
ae0ccb1c
Changes
4
Show whitespace changes
Inline
Side-by-side
Showing
4 changed files
with
9 additions
and
20 deletions
+9
-20
README.md
README.md
+8
-19
bert.png
bert.png
+0
-0
model.properties
model.properties
+1
-1
result.png
result.png
+0
-0
No files found.
README.md
View file @
141fb0e0
...
...
@@ -16,16 +16,7 @@ BERT模型的核心是Transformer编码器,BERT-large是BERT模型的一个更
BERT用大量的无监督文本通过自监督训练的方式训练,把文本中包含的语言知识(包括:词法、语法、语义等特征)以参数的形式编码到Transformer-encoder layer中,即用了Masked LM及Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
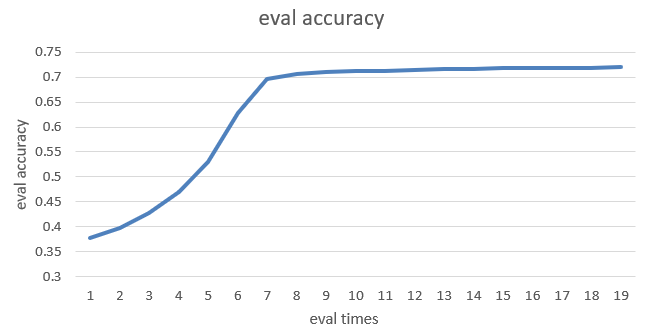
## 目标精度
0.
72 Mask-LM accuracy
## MLPerf代码参考版本
版本:v2.1
原始代码位置:
*
https://github.com/mlcommons/training_results_v2.1/tree/main/Baidu/benchmarks/bert/implementations/8_node_64_A100_PaddlePaddle

## 环境配置
...
...
@@ -47,13 +38,6 @@ BERT用大量的无监督文本通过自监督训练的方式训练,把文本
/root/mlperf-paddle_bert.20220919-training-bert/training/bert
```
## 预训练模型
/workspace/bert_data文件夹存放预训练模型如下:
├── /workpalce/bert_data/phase1
└── └──model.ckpt-28252.tf_pickled #预训练模型
## 数据集
模型训练的数据集来自Wikipedia 2020/01/01,即一种常用的自然语言处理数据集,它包含了维基百科上的文章和对应的摘要(即第一段内容),可用于各种文本相关的任务,例如文本分类、文本摘要、命名实体识别等。
...
...
@@ -85,7 +69,11 @@ BERT用大量的无监督文本通过自监督训练的方式训练,把文本
#不同环境的配置及数据的存放路径会有不同,请根据实际情况进行调整run_benchmark_8gpu.sh脚本中的如下内容:
BASE_DATA_DIR=${BASE_DATA_DIR:-"/public/DL_DATA/mlperf/bert"} //调整为具体的数据的路径
### result
## result

## 精度
采用上述输入数据,加速卡采用Z100L
*
8,可最终达到官方收敛要求,即达到目标精度0.72 Mask-LM accuracy;
...
...
@@ -101,7 +89,7 @@ BERT用大量的无监督文本通过自监督训练的方式训练,把文本
### 热点应用行业
零售
、
广媒
零售
,
广媒
## 源码仓库及问题反馈
...
...
@@ -110,3 +98,4 @@ BERT用大量的无监督文本通过自监督训练的方式训练,把文本
## 参考
*
https://mlcommons.org/en/
*
https://github.com/mlcommons
*
https://github.com/mlcommons/training_results_v2.1/tree/main/Baidu/benchmarks/bert/implementations/8_node_64_A100_PaddlePaddle
bert.png
0 → 100644
View file @
141fb0e0
108 KB
model.properties
View file @
141fb0e0
...
...
@@ -5,7 +5,7 @@ modelName=mlperf_bert_paddle
# 模型描述
modelDescription
=
BERT是一种基于Transformer架构的预训练语言模型
# 应用场景
appScenario
=
训练,NLP
appScenario
=
训练,NLP
,零售,广媒
# 框架类型
frameType
=
Paddle
result.png
0 → 100644
View file @
141fb0e0
10.2 KB
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}