Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
Mixtral_vllm
Commits
a22a3a6a
Commit
a22a3a6a
authored
Dec 20, 2024
by
laibao
Browse files
No commit message
No commit message
parent
19858495
Changes
3
Show whitespace changes
Inline
Side-by-side
Showing
3 changed files
with
7 additions
and
12 deletions
+7
-12
README.md
README.md
+7
-12
docs/GLM.png
docs/GLM.png
+0
-0
docs/transformers.jpg
docs/transformers.jpg
+0
-0
No files found.
README.md
View file @
a22a3a6a
...
@@ -13,23 +13,18 @@ Mixtral `: Mixture of Experts`
...
@@ -13,23 +13,18 @@ Mixtral `: Mixture of Experts`
## 模型结构
## 模型结构
Mixtral 8x7B 是 Mistral AI 公司开源的大型语言模型,采用稀疏混合专家架构(Sparse Mixture of Experts),包含 8 个专家网络,每个专家具有 70 亿参数。Mixtral 8x7B 在推理时仅使用 2 个最相关的专家网络进行计算,使其在保持 470 亿参数规模训练效果的同时,实际推理时仅需要约 140 亿参数的计算量。该模型支持多语言处理能力,能够在英语、法语、德语、西班牙语、意大利语等多种语言中表现出色。通过在高质量数据集上的训练,结合多专家架构和新颖的路由算法,Mixtral 8x7B 在数学推理、代码生成、知识问答等多个基准测试中均超越了同规模的其他开源模型。作为一个完全开源的模型,Mixtral 8x7B 提供了 Apache 2.0 许可证下的模型权重和推理代码,支持商用,并可在消费级显卡上直接部署运行,为开源AI社区带来了具有里程碑意义的贡献
。
Mixtral 8x7B 是 Mistral AI 公司开源的大型语言模型,采用稀疏混合专家架构(Sparse Mixture of Experts),包含 8 个专家网络,每个专家具有 70 亿参数。Mixtral 8x7B 在推理时仅使用 2 个最相关的专家网络进行计算,使其在保持 470 亿参数规模训练效果的同时,实际推理时仅需要约 140 亿参数的计算量。该模型支持多语言处理能力,能够在英语、法语、德语、西班牙语、意大利语等多种语言中表现出色。通过在高质量数据集上的训练,结合多专家架构和新颖的路由算法,Mixtral 8x7B 在数学推理、代码生成、知识问答等多个基准测试中均超越了同规模的其他开源模型。作为一个完全开源的模型,Mixtral 8x7B 提供了 Apache 2.0 许可证下的模型权重和推理代码,支持商用,并可在消费级显卡上直接部署运行,为开源AI社区带来了具有里程碑意义的贡献
<div
align=
"center"
>
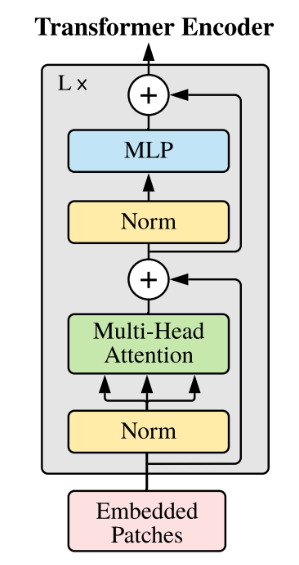
以下是Mixtral系列模型的主要网络参数配置:
<img
src=
"docs/transformers.jpg"
width=
"300"
height=
"400"
>
</div>
以下是ChatGLM系列模型的主要网络参数配置:
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 位置编码 | 最大序列长度 |
| 模型名称 | 总参数量 | 每次激活参数量 | 专家数 | 每个专家参数量 | 最大序列长度 |
| ----------- | ---------- | ---- | ---- | -------- | -------- | ------------ |
| ------------------ | -------- | -------------- | ------ | -------------- | ------------ |
| ChatGLM2-6B | 4096 | 28 | 32 | 65024 | RoPE | 8192 |
| Mixtral-8×7B-MoE | 467亿 | 129亿 | 8 | 70亿 | 32,768 |
| ChatGLM3-6B | 4096 | 28 | 32 | 65024 | RoPE | 8192 |
| Mixtral-8×22B-MoE | 1,760亿 | 440亿 | 8 | 220亿 | 65,536 |
| glm-4-9b | 4096 | 40 | 32 | 151552 | RoPE | 131072 |
## 算法原理
## 算法原理
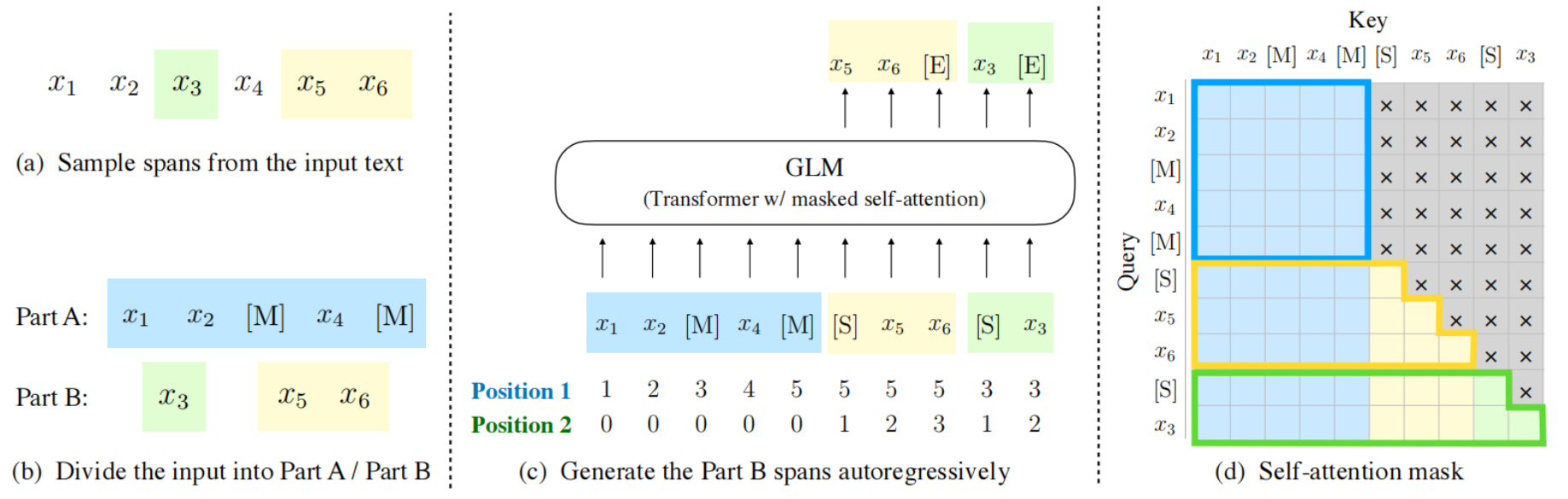
ChatGLM系列模型基于GLM架构开发。GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标, 同时具备自回归和自编码能力
。
Mixtral模型是一种稀疏专家混合(SMoE)语言模型,在每层包含多个前馈网络(专家),通过路由网络为每个输入token选择最相关的专家进行处理,从而在保持高效计算的同时提升模型性能
。
<div
align=
"center"
>
<div
align=
"center"
>
<img
src=
"docs/GLM.png"
width=
"550"
height=
"200"
>
<img
src=
"docs/GLM.png"
width=
"550"
height=
"200"
>
...
...
docs/GLM.png
deleted
100644 → 0
View file @
19858495
261 KB
docs/transformers.jpg
deleted
100644 → 0
View file @
19858495
32.7 KB
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}