Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
MiniMax-M2_vllm
Commits
688d8492
Commit
688d8492
authored
Jan 26, 2026
by
chenych
Browse files
Update minimax-m2.1 tool call
parent
9d2097be
Changes
7
Show whitespace changes
Inline
Side-by-side
Showing
7 changed files
with
1075 additions
and
118 deletions
+1075
-118
README.md
README.md
+47
-6
codes/minimax_m2_reasoning_parser.py
codes/minimax_m2_reasoning_parser.py
+110
-0
codes/minimax_m2_tool_parser.py
codes/minimax_m2_tool_parser.py
+879
-0
config.json
config.json
+0
-112
doc/result-minimax-m2_1.png
doc/result-minimax-m2_1.png
+0
-0
doc/results-minimax-m2_1-tool.png
doc/results-minimax-m2_1-tool.png
+0
-0
offline_tools.py
offline_tools.py
+39
-0
No files found.
README.md
View file @
688d8492
...
...
@@ -38,6 +38,12 @@ docker run -it --shm-size 60g --network=host --name minimax_m2 --privileged --de
更多镜像可前往
[
光源
](
https://sourcefind.cn/#/service-list
)
下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从
[
光合
](
https://developer.sourcefind.cn/tool/
)
开发者社区下载安装。
vllm文件替换
```
bash
# /path/of/vllm 可以通过 "pip show vllm" 中的 "Location" 字段来获取环境中vllm所在目录
cp
codes/minimax_m2_tool_parser.py /path/of/vllm/entrypoints/openai/tool_parsers/minimax_m2_tool_parser.py
cp
codes/minimax_m2_reasoning_parser.py /path/of/vllm/reasoning/minimax_m2_reasoning_parser.py
```
## 数据集
暂无
...
...
@@ -71,11 +77,10 @@ cp /path/of/MiniMax/MiniMax-M2/vocab.json /path/of/MiniMax/MiniMax-M2-bf16
### vllm
#### 单机推理
-
MiniMax-M2
```
bash
## serve启动
export
ALLREDUCE_STREAM_WITH_COMPUTE
=
1
export
VLLM_MLA_DISABLE
=
0
export
VLLM_USE_FLASH_MLA
=
1
vllm serve /path/of/MiniMax/MiniMax-M2-bf16/
\
--trust-remote-code
\
...
...
@@ -98,6 +103,38 @@ curl http://localhost:8000/v1/chat/completions \
}'
```
-
MiniMax-M2.1
```
bash
## serve启动
vllm serve /path/of/MiniMax/MiniMax-M2.1-bf16
\
--trust-remote-code
\
--served-model-name
minimax-m2.1
\
--max-model-len
32768
\
--dtype
bfloat16
\
-tp
8
\
--port
8001
\
--enable-auto-tool-choice
\
--tool-call-parser
minimax-m2
\
--enable-expert-parallel
\
--reasoning-parser
minimax_m2
## client访问
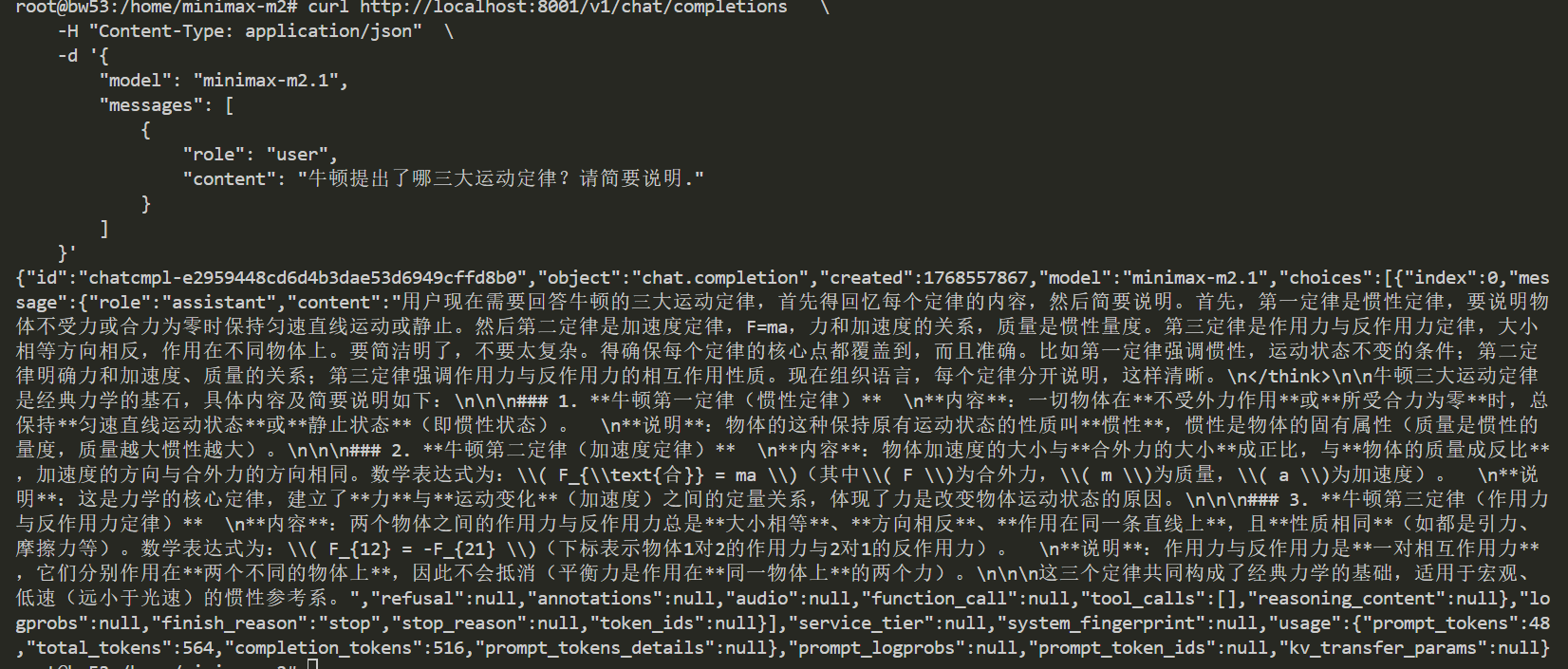
curl http://localhost:8000/v1/chat/completions
\
-H
"Content-Type: application/json"
\
-d
'{
"model": "minimax-m2.1",
"messages": [
{
"role": "user",
"content": "牛顿提出了哪三大运动定律?请简要说明。"
}
]
}'
## 离线工具调用
python offline_tools.py
```
## 效果展示
-
MiniMax-M2 模型效果
<div
align=
center
>
...
...
@@ -105,11 +142,15 @@ curl http://localhost:8000/v1/chat/completions \
</div>
-
MiniMax-M2.1 模型效果
1.
对话
<div
align=
center
>
<img
src=
"./doc/result-minimax-m2_1.png"
/>
</div>
2.
离线工具调用
<div
align=
center
>
<img
src=
"./doc/results-minimax-m2_1-tool.png"
/>
</div>
### 精度
DCU与GPU精度一致,推理框架:vllm。
...
...
@@ -117,8 +158,8 @@ DCU与GPU精度一致,推理框架:vllm。
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 |下载地址|
|:-----:|:----------:|:----------:|:---------------------:|:----------:|
| MiniMax-M2 | 230 B | K100AI | 8 |
[
下载地址
](
https://huggingface.co/MiniMaxAI/MiniMax-M2
)
|
| MiniMax-M2.1 | 230 B | K100AI | 8 |
[
下载地址
](
https://www.modelscope.cn/models/MiniMax/MiniMax-M2.1
)
|
| MiniMax-M2 | 230 B | K100AI
,BW1000
| 8 |
[
下载地址
](
https://huggingface.co/MiniMaxAI/MiniMax-M2
)
|
| MiniMax-M2.1 | 230 B | K100AI
,BW1000
| 8 |
[
下载地址
](
https://www.modelscope.cn/models/MiniMax/MiniMax-M2.1
)
|
## 源码仓库及问题反馈
-
https://developer.sourcefind.cn/codes/modelzoo/minimax-m2_vllm
...
...
codes/minimax_m2_reasoning_parser.py
0 → 100644
View file @
688d8492
# SPDX-License-Identifier: Apache-2.0
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
from
collections.abc
import
Sequence
from
vllm.entrypoints.openai.protocol
import
(
ChatCompletionRequest
,
DeltaMessage
,
ResponsesRequest
,
)
from
vllm.logger
import
init_logger
from
vllm.reasoning
import
ReasoningParser
,
ReasoningParserManager
from
vllm.reasoning.basic_parsers
import
BaseThinkingReasoningParser
from
vllm.transformers_utils.tokenizer
import
AnyTokenizer
logger
=
init_logger
(
__name__
)
@
ReasoningParserManager
.
register_module
(
"minimax_m2"
)
class
MiniMaxM2ReasoningParser
(
BaseThinkingReasoningParser
):
"""
Reasoning parser for MiniMax M2 model.
MiniMax M2 models don't generate <think> start token, only </think> end
token. All content before </think> is reasoning, content after is the
actual response.
"""
@
property
def
start_token
(
self
)
->
str
:
"""The token that starts reasoning content."""
return
"<think>"
@
property
def
end_token
(
self
)
->
str
:
"""The token that ends reasoning content."""
return
"</think>"
def
extract_reasoning_streaming
(
self
,
previous_text
:
str
,
current_text
:
str
,
delta_text
:
str
,
previous_token_ids
:
Sequence
[
int
],
current_token_ids
:
Sequence
[
int
],
delta_token_ids
:
Sequence
[
int
],
)
->
DeltaMessage
|
None
:
"""
Extract reasoning content from a delta message for streaming.
MiniMax M2 models don't generate <think> start token, so we assume
all content is reasoning until we encounter the </think> end token.
"""
# Skip single end token
if
len
(
delta_token_ids
)
==
1
and
delta_token_ids
[
0
]
==
self
.
end_token_id
:
return
None
# Check if end token has already appeared in previous tokens
# meaning we're past the reasoning phase
if
self
.
end_token_id
in
previous_token_ids
:
# We're past the reasoning phase, this is content
return
DeltaMessage
(
content
=
delta_text
)
# Check if end token is in delta tokens
if
self
.
end_token_id
in
delta_token_ids
:
# End token in delta, split reasoning and content
end_index
=
delta_text
.
find
(
self
.
end_token
)
reasoning
=
delta_text
[:
end_index
]
content
=
delta_text
[
end_index
+
len
(
self
.
end_token
)
:]
return
DeltaMessage
(
reasoning
=
reasoning
if
reasoning
else
None
,
content
=
content
if
content
else
None
,
)
# No end token yet, all content is reasoning
return
DeltaMessage
(
reasoning
=
delta_text
)
class
MiniMaxM2AppendThinkReasoningParser
(
ReasoningParser
):
"""
Reasoning parser for MiniMax M2 model.
"""
def
__init__
(
self
,
tokenizer
:
AnyTokenizer
,
*
args
,
**
kwargs
):
super
().
__init__
(
tokenizer
,
*
args
,
**
kwargs
)
self
.
end_token_id
=
self
.
vocab
.
get
(
"</think>"
)
def
is_reasoning_end
(
self
,
input_ids
:
Sequence
[
int
])
->
bool
:
end_token_id
=
self
.
end_token_id
return
any
(
input_id
==
end_token_id
for
input_id
in
reversed
(
input_ids
))
def
extract_content_ids
(
self
,
input_ids
:
list
[
int
])
->
list
[
int
]:
return
input_ids
def
extract_reasoning_streaming
(
self
,
previous_text
:
str
,
current_text
:
str
,
delta_text
:
str
,
previous_token_ids
:
Sequence
[
int
],
current_token_ids
:
Sequence
[
int
],
delta_token_ids
:
Sequence
[
int
],
)
->
DeltaMessage
|
None
:
if
len
(
previous_token_ids
)
==
0
:
delta_text
=
"<think>"
+
delta_text
return
DeltaMessage
(
content
=
delta_text
)
def
extract_reasoning
(
self
,
model_output
:
str
,
request
:
ChatCompletionRequest
|
ResponsesRequest
)
->
tuple
[
str
|
None
,
str
|
None
]:
return
None
,
"<think>"
+
model_output
\ No newline at end of file
codes/minimax_m2_tool_parser.py
0 → 100644
View file @
688d8492
# SPDX-License-Identifier: Apache-2.0
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
import
json
import
uuid
from
collections.abc
import
Sequence
from
typing
import
Any
import
regex
as
re
from
vllm.entrypoints.openai.protocol
import
(
ChatCompletionRequest
,
DeltaFunctionCall
,
DeltaMessage
,
DeltaToolCall
,
ExtractedToolCallInformation
,
FunctionCall
,
ToolCall
,
)
from
vllm.entrypoints.openai.tool_parsers.abstract_tool_parser
import
(
ToolParser
,
ToolParserManager
)
from
vllm.logger
import
init_logger
from
vllm.transformers_utils.tokenizer
import
AnyTokenizer
logger
=
init_logger
(
__name__
)
@
ToolParserManager
.
register_module
(
"minimax-m2"
)
class
MinimaxM2ToolParser
(
ToolParser
):
def
__init__
(
self
,
tokenizer
:
AnyTokenizer
):
super
().
__init__
(
tokenizer
)
self
.
prev_tool_call_arr
:
list
[
dict
]
=
[]
# Sentinel tokens
self
.
tool_call_start_token
:
str
=
"<minimax:tool_call>"
self
.
tool_call_end_token
:
str
=
"</minimax:tool_call>"
self
.
invoke_start_prefix
:
str
=
"<invoke name="
self
.
invoke_end_token
:
str
=
"</invoke>"
self
.
parameter_prefix
:
str
=
"<parameter name="
self
.
parameter_end_token
:
str
=
"</parameter>"
# Streaming state variables
self
.
current_tool_name_sent
:
bool
=
False
# Override base class type - we use string IDs for tool calls
self
.
current_tool_id
:
str
|
None
=
None
# type: ignore
self
.
streamed_args_for_tool
:
list
[
str
]
=
[]
self
.
is_tool_call_started
:
bool
=
False
self
.
failed_count
:
int
=
0
# Initialize streaming state variables
self
.
current_tool_index
:
int
=
0
self
.
invoke_index
:
int
=
0
self
.
header_sent
:
bool
=
False
self
.
current_function_name
:
str
|
None
=
None
self
.
current_param_name
:
str
|
None
=
None
self
.
current_param_value
:
str
=
""
self
.
param_count
:
int
=
0
self
.
in_param
:
bool
=
False
self
.
in_function
:
bool
=
False
self
.
accumulated_text
:
str
=
""
self
.
json_started
:
bool
=
False
self
.
json_closed
:
bool
=
False
self
.
accumulated_params
:
dict
=
{}
self
.
streaming_request
:
ChatCompletionRequest
|
None
=
None
# Enhanced streaming state - reset for each new message
self
.
_reset_streaming_state
()
# Regex patterns for complete parsing
self
.
tool_call_complete_regex
=
re
.
compile
(
r
"<minimax:tool_call>(.*?)</minimax:tool_call>"
,
re
.
DOTALL
)
# Improved regex: capture only the name attribute value (quoted or unquoted)
# and ignore any additional attributes that may follow
self
.
invoke_complete_regex
=
re
.
compile
(
r
"""
<invoke\s+name= # Match tag start and name attribute key
( # Start Group 1: Name value
"[^"]+" # Double-quoted string
| # OR
'[^']+' # Single-quoted string
| # OR
[^\s>]+ # Unquoted value (no whitespace or >)
) # End Group 1
(?:\s+[^>]*)? # Optional: Extra attributes (ignored)
\s*> # Closing bracket of opening tag
(.*?) # Group 2: Content (non-greedy)
</invoke> # Closing tag
"""
,
re
.
VERBOSE
|
re
.
DOTALL
,
)
# Improved regex for parameters: capture name attribute and content separately
# Handles cases where model may include description text in attributes
self
.
parameter_complete_regex
=
re
.
compile
(
r
"""
<parameter\s+name= # Match tag start and name attribute key
( # Start Group 1: Name value
"[^"]+" # Double-quoted string
| # OR
'[^']+' # Single-quoted string
| # OR
[^\s>]+ # Unquoted value (no whitespace or >)
) # End Group 1
(?:\s+[^>]*)? # Optional: Extra attributes (ignored)
\s*> # Closing bracket of opening tag
(.*?) # Group 2: Content (non-greedy)
</parameter> # Closing tag
"""
,
re
.
VERBOSE
|
re
.
DOTALL
,
)
if
not
self
.
model_tokenizer
:
raise
ValueError
(
"The model tokenizer must be passed to the ToolParser "
"constructor during construction."
)
self
.
tool_call_start_token_id
=
self
.
vocab
.
get
(
self
.
tool_call_start_token
)
self
.
tool_call_end_token_id
=
self
.
vocab
.
get
(
self
.
tool_call_end_token
)
if
self
.
tool_call_start_token_id
is
None
or
self
.
tool_call_end_token_id
is
None
:
raise
RuntimeError
(
"MiniMax M2 Tool parser could not locate tool call start/end "
"tokens in the tokenizer!"
)
logger
.
debug
(
"vLLM Successfully import tool parser %s !"
,
self
.
__class__
.
__name__
)
def
_generate_tool_call_id
(
self
)
->
str
:
"""Generate a unique tool call ID."""
return
f
"call_
{
uuid
.
uuid4
().
hex
[:
24
]
}
"
def
_reset_streaming_state
(
self
):
"""Reset all streaming state."""
self
.
current_tool_index
=
0
self
.
invoke_index
=
0
self
.
is_tool_call_started
=
False
self
.
header_sent
=
False
self
.
current_tool_id
=
None
self
.
current_function_name
=
None
self
.
current_param_name
=
None
self
.
current_param_value
=
""
self
.
param_count
=
0
self
.
in_param
=
False
self
.
in_function
=
False
self
.
accumulated_text
=
""
self
.
json_started
=
False
self
.
json_closed
=
False
# Store accumulated parameters for type conversion
self
.
accumulated_params
=
{}
self
.
streaming_request
=
None
# Clear previous tool call history to avoid state pollution
self
.
prev_tool_call_arr
.
clear
()
# Reset streamed args tracking
self
.
streamed_args_for_tool
.
clear
()
def
_extract_name
(
self
,
name_str
:
str
)
->
str
:
"""Extract name from quoted string."""
name_str
=
name_str
.
strip
()
if
(
name_str
.
startswith
(
'"'
)
and
name_str
.
endswith
(
'"'
)
or
name_str
.
startswith
(
"'"
)
and
name_str
.
endswith
(
"'"
)
):
return
name_str
[
1
:
-
1
]
return
name_str
def
_parse_name_from_attributes
(
self
,
attr_section
:
str
)
->
str
:
"""Helper to extract name from attribute section string.
Handles quoted and unquoted names, ignoring extra attributes."""
# Check for quoted name first
if
attr_section
.
startswith
(
'"'
):
# Find closing quote
close_quote
=
attr_section
.
find
(
'"'
,
1
)
if
close_quote
!=
-
1
:
name_raw
=
attr_section
[:
close_quote
+
1
]
else
:
name_raw
=
attr_section
elif
attr_section
.
startswith
(
"'"
):
# Find closing single quote
close_quote
=
attr_section
.
find
(
"'"
,
1
)
if
close_quote
!=
-
1
:
name_raw
=
attr_section
[:
close_quote
+
1
]
else
:
name_raw
=
attr_section
else
:
# Unquoted name - take until first whitespace
space_idx
=
-
1
for
i
,
c
in
enumerate
(
attr_section
):
if
c
.
isspace
():
space_idx
=
i
break
name_raw
=
attr_section
[:
space_idx
]
if
space_idx
!=
-
1
else
attr_section
return
self
.
_extract_name
(
name_raw
)
def
_convert_param_value
(
self
,
value
:
str
,
param_type
:
str
)
->
Any
:
"""Convert parameter value to the correct type (legacy single-type version)."""
return
self
.
_convert_param_value_with_types
(
value
,
[
param_type
])
def
_extract_types_from_schema
(
self
,
schema
:
Any
)
->
list
[
str
]:
"""
Extract all possible types from a JSON schema definition.
Handles anyOf, oneOf, allOf, type arrays, and enum fields.
Args:
schema: The JSON schema definition for a parameter
Returns:
List of type strings (e.g., ["string", "integer", "null"])
"""
if
schema
is
None
:
return
[
"string"
]
if
not
isinstance
(
schema
,
dict
):
return
[
"string"
]
types
:
set
[
str
]
=
set
()
# Handle direct "type" field
if
"type"
in
schema
:
type_value
=
schema
[
"type"
]
if
isinstance
(
type_value
,
str
):
types
.
add
(
type_value
)
elif
isinstance
(
type_value
,
list
):
for
t
in
type_value
:
if
isinstance
(
t
,
str
):
types
.
add
(
t
)
# Handle enum - infer types from enum values
if
"enum"
in
schema
and
isinstance
(
schema
[
"enum"
],
list
)
and
schema
[
"enum"
]:
for
value
in
schema
[
"enum"
]:
if
value
is
None
:
types
.
add
(
"null"
)
elif
isinstance
(
value
,
bool
):
types
.
add
(
"boolean"
)
elif
isinstance
(
value
,
int
):
types
.
add
(
"integer"
)
elif
isinstance
(
value
,
float
):
types
.
add
(
"number"
)
elif
isinstance
(
value
,
str
):
types
.
add
(
"string"
)
elif
isinstance
(
value
,
list
):
types
.
add
(
"array"
)
elif
isinstance
(
value
,
dict
):
types
.
add
(
"object"
)
# Handle anyOf, oneOf, allOf - recursively extract types
for
choice_field
in
(
"anyOf"
,
"oneOf"
,
"allOf"
):
if
choice_field
in
schema
and
isinstance
(
schema
[
choice_field
],
list
):
for
choice
in
schema
[
choice_field
]:
extracted
=
self
.
_extract_types_from_schema
(
choice
)
types
.
update
(
extracted
)
# If no types found, default to string
if
not
types
:
return
[
"string"
]
return
list
(
types
)
def
_convert_param_value_with_types
(
self
,
value
:
str
,
param_types
:
list
[
str
]
)
->
Any
:
"""
Convert parameter value to the correct type based on a list of possible types.
Tries each type in order until one succeeds.
Args:
value: The string value to convert
param_types: List of possible type strings
Returns:
The converted value
"""
# Check if the VALUE itself indicates null (not just if null is allowed)
if
value
.
lower
()
in
(
"null"
,
"none"
,
"nil"
):
return
None
# Normalize types
normalized_types
=
[
t
.
lower
()
for
t
in
param_types
]
# Try each type in order of preference (most specific first, string as fallback)
# Priority: integer > number > boolean > object > array > string
type_priority
=
[
"integer"
,
"int"
,
"number"
,
"float"
,
"boolean"
,
"bool"
,
"object"
,
"array"
,
"string"
,
"str"
,
"text"
,
]
for
param_type
in
type_priority
:
if
param_type
not
in
normalized_types
:
continue
if
param_type
in
[
"string"
,
"str"
,
"text"
]:
return
value
elif
param_type
in
[
"integer"
,
"int"
]:
try
:
return
int
(
value
)
except
(
ValueError
,
TypeError
):
continue
elif
param_type
in
[
"number"
,
"float"
]:
try
:
val
=
float
(
value
)
return
val
if
val
!=
int
(
val
)
else
int
(
val
)
except
(
ValueError
,
TypeError
):
continue
elif
param_type
in
[
"boolean"
,
"bool"
]:
lower_val
=
value
.
lower
().
strip
()
if
lower_val
in
[
"true"
,
"1"
,
"yes"
,
"on"
]:
return
True
elif
lower_val
in
[
"false"
,
"0"
,
"no"
,
"off"
]:
return
False
continue
elif
param_type
in
[
"object"
,
"array"
]:
try
:
return
json
.
loads
(
value
)
except
json
.
JSONDecodeError
:
continue
# Fallback: try JSON parse, then return as string
try
:
return
json
.
loads
(
value
)
except
json
.
JSONDecodeError
:
return
value
def
_get_param_types_from_config
(
self
,
param_name
:
str
,
param_config
:
dict
)
->
list
[
str
]:
"""
Get parameter types from parameter configuration.
Handles anyOf, oneOf, allOf, and direct type definitions.
Args:
param_name: The name of the parameter
param_config: The properties dict from the tool schema
Returns:
List of type strings
"""
if
param_name
not
in
param_config
:
return
[
"string"
]
param_schema
=
param_config
[
param_name
]
if
not
isinstance
(
param_schema
,
dict
):
return
[
"string"
]
return
self
.
_extract_types_from_schema
(
param_schema
)
def
_parse_single_invoke
(
self
,
invoke_str
:
str
,
tools
:
list
|
None
)
->
ToolCall
|
None
:
"""Parse a single <invoke> block.
Args:
invoke_str: For legacy regex, this is the full content after
'<invoke name='. For new regex with groups, this is
a tuple of (name, content).
tools: List of available tools for type information.
Returns:
Parsed ToolCall or None if parsing fails.
"""
# Handle both old format (string) and new format (tuple from regex groups)
if
isinstance
(
invoke_str
,
tuple
):
# New regex format: (name_raw, content)
function_name
=
self
.
_extract_name
(
invoke_str
[
0
])
invoke_content
=
invoke_str
[
1
]
if
len
(
invoke_str
)
>
1
else
""
else
:
# Fallback for unexpected string input
# (should generally be tuple from regex)
# Try to extract similarly to tuple case
match
=
self
.
invoke_complete_regex
.
search
(
invoke_str
)
if
match
:
function_name
=
self
.
_extract_name
(
match
.
group
(
1
))
invoke_content
=
match
.
group
(
2
)
else
:
# Basic fallback if regex doesn't match
name_match
=
re
.
search
(
r
"^([^>]+)"
,
invoke_str
)
if
not
name_match
:
return
None
function_name
=
self
.
_extract_name
(
name_match
.
group
(
1
))
# Extract content after the closing '>'
content_match
=
re
.
search
(
r
"^[^>]+>(.*)"
,
invoke_str
,
re
.
DOTALL
)
invoke_content
=
content_match
.
group
(
1
)
if
content_match
else
""
# Get parameter configuration
param_config
=
{}
if
tools
:
for
tool
in
tools
:
if
(
hasattr
(
tool
,
"function"
)
and
tool
.
function
.
name
==
function_name
and
hasattr
(
tool
.
function
,
"parameters"
)
):
params
=
tool
.
function
.
parameters
if
isinstance
(
params
,
dict
)
and
"properties"
in
params
:
param_config
=
params
[
"properties"
]
break
# Extract parameters using the improved regex
param_dict
=
{}
for
match
in
self
.
parameter_complete_regex
.
findall
(
invoke_content
):
# match is now a tuple: (param_name_raw, param_value)
if
isinstance
(
match
,
tuple
)
and
len
(
match
)
>=
2
:
param_name
=
self
.
_extract_name
(
match
[
0
])
param_value
=
match
[
1
].
strip
()
else
:
# Fallback for unexpected format
param_match
=
re
.
search
(
r
"^([^>]+)>(.*)"
,
str
(
match
),
re
.
DOTALL
)
if
not
param_match
:
continue
param_name
=
self
.
_extract_name
(
param_match
.
group
(
1
))
param_value
=
param_match
.
group
(
2
).
strip
()
if
param_value
.
startswith
(
"
\n
"
):
param_value
=
param_value
[
1
:]
if
param_value
.
endswith
(
"
\n
"
):
param_value
=
param_value
[:
-
1
]
# Get parameter types (supports anyOf/oneOf/allOf)
param_type
=
self
.
_get_param_types_from_config
(
param_name
,
param_config
)
# Convert value
param_dict
[
param_name
]
=
self
.
_convert_param_value_with_types
(
param_value
,
param_type
)
return
ToolCall
(
type
=
"function"
,
function
=
FunctionCall
(
name
=
function_name
,
arguments
=
json
.
dumps
(
param_dict
,
ensure_ascii
=
False
),
),
)
def
extract_tool_calls
(
self
,
model_output
:
str
,
request
:
ChatCompletionRequest
,
)
->
ExtractedToolCallInformation
:
"""Extract tool calls from complete model output (non-streaming)."""
# Quick check
if
self
.
tool_call_start_token
not
in
model_output
:
return
ExtractedToolCallInformation
(
tools_called
=
False
,
tool_calls
=
[],
content
=
model_output
)
try
:
tool_calls
=
[]
# Find all complete tool_call blocks
for
tool_call_match
in
self
.
tool_call_complete_regex
.
findall
(
model_output
):
# Find all invokes within this tool_call
for
invoke_match
in
self
.
invoke_complete_regex
.
findall
(
tool_call_match
):
tool_call
=
self
.
_parse_single_invoke
(
invoke_match
,
request
.
tools
if
request
else
None
)
if
tool_call
:
tool_calls
.
append
(
tool_call
)
if
not
tool_calls
:
return
ExtractedToolCallInformation
(
tools_called
=
False
,
tool_calls
=
[],
content
=
model_output
)
# Update prev_tool_call_arr
self
.
prev_tool_call_arr
.
clear
()
for
tool_call
in
tool_calls
:
self
.
prev_tool_call_arr
.
append
(
{
"name"
:
tool_call
.
function
.
name
,
"arguments"
:
tool_call
.
function
.
arguments
,
}
)
# Extract content before first tool call
first_tool_idx
=
model_output
.
find
(
self
.
tool_call_start_token
)
content
=
model_output
[:
first_tool_idx
]
if
first_tool_idx
>
0
else
None
return
ExtractedToolCallInformation
(
tools_called
=
True
,
tool_calls
=
tool_calls
,
content
=
content
)
except
Exception
:
logger
.
exception
(
"Error extracting tool calls"
)
return
ExtractedToolCallInformation
(
tools_called
=
False
,
tool_calls
=
[],
content
=
model_output
)
def
extract_tool_calls_streaming
(
self
,
previous_text
:
str
,
current_text
:
str
,
delta_text
:
str
,
previous_token_ids
:
Sequence
[
int
],
# pylint: disable=unused-argument
current_token_ids
:
Sequence
[
int
],
# pylint: disable=unused-argument
delta_token_ids
:
Sequence
[
int
],
request
:
ChatCompletionRequest
,
)
->
DeltaMessage
|
None
:
"""Extract tool calls from streaming model output."""
# Store request for type conversion
if
not
previous_text
or
self
.
tool_call_start_token
in
delta_text
:
self
.
_reset_streaming_state
()
self
.
streaming_request
=
request
# If no delta text, return None unless it's an EOS token after tools
if
not
delta_text
:
# Check if this is an EOS token after all tool calls are complete
if
delta_token_ids
and
self
.
tool_call_end_token_id
not
in
delta_token_ids
:
# Count complete tool calls
complete_calls
=
len
(
self
.
tool_call_complete_regex
.
findall
(
current_text
)
)
# If we have completed tool calls and populated prev_tool_call_arr
if
complete_calls
>
0
and
len
(
self
.
prev_tool_call_arr
)
>
0
:
# Check if all tool calls are closed
open_calls
=
current_text
.
count
(
self
.
tool_call_start_token
)
-
current_text
.
count
(
self
.
tool_call_end_token
)
if
open_calls
==
0
:
# Return empty delta for finish_reason processing
return
DeltaMessage
(
content
=
""
)
elif
not
self
.
is_tool_call_started
and
current_text
:
# This is a regular content response that's now complete
return
DeltaMessage
(
content
=
""
)
return
None
# Update accumulated text
self
.
accumulated_text
=
current_text
# Check if we need to advance to next tool
if
self
.
json_closed
and
not
self
.
in_function
:
# Check if this tool call has ended
invoke_ends
=
current_text
.
count
(
self
.
invoke_end_token
)
if
invoke_ends
>
self
.
current_tool_index
:
# This tool has ended, advance to next
self
.
current_tool_index
+=
1
self
.
header_sent
=
False
self
.
param_count
=
0
self
.
json_started
=
False
self
.
json_closed
=
False
self
.
in_function
=
False
# Now we can safely set this to False
self
.
accumulated_params
=
{}
# Continue processing next tool
return
None
# Handle normal content before tool calls
if
not
self
.
is_tool_call_started
:
# Check if tool call is starting
if
(
self
.
tool_call_start_token_id
in
delta_token_ids
or
self
.
tool_call_start_token
in
delta_text
):
self
.
is_tool_call_started
=
True
# Return any content before the tool call
if
self
.
tool_call_start_token
in
delta_text
:
content_before
=
delta_text
[
:
delta_text
.
index
(
self
.
tool_call_start_token
)
]
if
content_before
:
return
DeltaMessage
(
content
=
content_before
)
return
None
else
:
# Check if we're between tool calls - skip whitespace
if
(
current_text
.
rstrip
().
endswith
(
self
.
tool_call_end_token
)
and
delta_text
.
strip
()
==
""
):
# We just ended a tool call, skip whitespace
return
None
# Normal content, no tool call
return
DeltaMessage
(
content
=
delta_text
)
# Check if we're between tool calls (waiting for next one)
invoke_starts_count
=
current_text
.
count
(
self
.
invoke_start_prefix
)
if
self
.
current_tool_index
>=
invoke_starts_count
:
# We're past all tool calls, shouldn't be here
return
None
# Find the current tool call portion
invoke_start_positions
:
list
[
int
]
=
[]
idx
=
0
while
True
:
idx
=
current_text
.
find
(
self
.
invoke_start_prefix
,
idx
)
if
idx
==
-
1
:
break
invoke_start_positions
.
append
(
idx
)
idx
+=
len
(
self
.
invoke_start_prefix
)
if
self
.
current_tool_index
>=
len
(
invoke_start_positions
):
# No more tool calls to process yet
return
None
invoke_start_idx
=
invoke_start_positions
[
self
.
current_tool_index
]
# Find where this tool call ends (or current position if not ended yet)
invoke_end_idx
=
current_text
.
find
(
self
.
invoke_end_token
,
invoke_start_idx
)
if
invoke_end_idx
==
-
1
:
tool_text
=
current_text
[
invoke_start_idx
:]
else
:
tool_text
=
current_text
[
invoke_start_idx
:
invoke_end_idx
+
len
(
self
.
invoke_end_token
)
]
# Looking for function header
if
not
self
.
header_sent
:
if
self
.
invoke_start_prefix
in
tool_text
:
func_start
=
tool_text
.
find
(
self
.
invoke_start_prefix
)
+
len
(
self
.
invoke_start_prefix
)
# Find the end of the opening tag
func_end
=
tool_text
.
find
(
">"
,
func_start
)
if
func_end
!=
-
1
:
# Found complete function name
# Handle cases where model may add extra attributes after name
attr_section
=
tool_text
[
func_start
:
func_end
]
self
.
current_function_name
=
self
.
_parse_name_from_attributes
(
attr_section
)
self
.
current_tool_id
=
self
.
_generate_tool_call_id
()
self
.
header_sent
=
True
self
.
in_function
=
True
# Add to prev_tool_call_arr immediately when we detect a tool call
# Each tool call should be recorded regardless of function name
# Ensure we don't add the same tool call index multiple times
if
len
(
self
.
prev_tool_call_arr
)
<=
self
.
current_tool_index
:
self
.
prev_tool_call_arr
.
append
(
{
"name"
:
self
.
current_function_name
,
"arguments"
:
{},
# Placeholder, will be updated later
}
)
# Initialize streamed_args_for_tool for this tool call
if
len
(
self
.
streamed_args_for_tool
)
<=
self
.
current_tool_index
:
self
.
streamed_args_for_tool
.
append
(
""
)
# Send header with function info
return
DeltaMessage
(
tool_calls
=
[
DeltaToolCall
(
index
=
self
.
current_tool_index
,
id
=
self
.
current_tool_id
,
function
=
DeltaFunctionCall
(
name
=
self
.
current_function_name
,
arguments
=
""
),
type
=
"function"
,
)
]
)
return
None
# We've sent header, now handle function body
if
self
.
in_function
:
# Send opening brace if not sent yet
if
self
.
in_function
and
not
self
.
json_started
:
self
.
json_started
=
True
# Update streamed_args_for_tool for opening brace
if
self
.
current_tool_index
<
len
(
self
.
streamed_args_for_tool
):
self
.
streamed_args_for_tool
[
self
.
current_tool_index
]
+=
"{"
return
DeltaMessage
(
tool_calls
=
[
DeltaToolCall
(
index
=
self
.
current_tool_index
,
function
=
DeltaFunctionCall
(
arguments
=
"{"
),
)
]
)
# Make sure json_started is set if we're processing parameters
if
not
self
.
json_started
:
self
.
json_started
=
True
# Check for function end in accumulated text
if
not
self
.
json_closed
and
self
.
invoke_end_token
in
tool_text
:
# Count total parameters in the tool text
total_param_count
=
tool_text
.
count
(
self
.
parameter_prefix
)
# Only close JSON if all parameters have been processed
if
self
.
param_count
>=
total_param_count
:
# Close JSON
self
.
json_closed
=
True
# Extract complete tool call
# Find the invoke content
invoke_start
=
tool_text
.
find
(
self
.
invoke_start_prefix
)
+
len
(
self
.
invoke_start_prefix
)
invoke_content_end
=
tool_text
.
find
(
self
.
invoke_end_token
,
invoke_start
)
if
invoke_content_end
!=
-
1
:
invoke_content
=
tool_text
[
invoke_start
:
invoke_content_end
]
# Parse to get the complete arguments
try
:
parsed_tool
=
self
.
_parse_single_invoke
(
invoke_content
,
self
.
streaming_request
.
tools
if
self
.
streaming_request
else
None
,
)
if
parsed_tool
and
self
.
current_tool_index
<
len
(
self
.
prev_tool_call_arr
):
# Update existing entry in prev_tool_call_arr
args
=
parsed_tool
.
function
.
arguments
self
.
prev_tool_call_arr
[
self
.
current_tool_index
][
"arguments"
]
=
json
.
loads
(
args
)
except
Exception
:
pass
# Ignore parsing errors during streaming
result
=
DeltaMessage
(
tool_calls
=
[
DeltaToolCall
(
index
=
self
.
current_tool_index
,
function
=
DeltaFunctionCall
(
arguments
=
"}"
),
)
]
)
# Update streamed_args_for_tool for closing brace
if
self
.
current_tool_index
<
len
(
self
.
streamed_args_for_tool
):
self
.
streamed_args_for_tool
[
self
.
current_tool_index
]
+=
"}"
# Reset state for next tool
self
.
json_closed
=
True
self
.
in_function
=
False
self
.
accumulated_params
=
{}
logger
.
debug
(
"[M2_STREAMING] Tool call completed"
)
return
result
else
:
# Don't close JSON yet, continue processing parameters
return
None
# Look for parameters
# Find all parameter starts
param_starts
=
[]
idx
=
0
while
True
:
idx
=
tool_text
.
find
(
self
.
parameter_prefix
,
idx
)
if
idx
==
-
1
:
break
param_starts
.
append
(
idx
)
idx
+=
len
(
self
.
parameter_prefix
)
# Check if we should start a new parameter
if
(
not
self
.
in_param
and
self
.
param_count
<
len
(
param_starts
)
and
len
(
param_starts
)
>
self
.
param_count
):
# Process the next parameter
param_idx
=
param_starts
[
self
.
param_count
]
param_start
=
param_idx
+
len
(
self
.
parameter_prefix
)
remaining
=
tool_text
[
param_start
:]
if
">"
in
remaining
:
# We have the complete parameter name
# Handle cases where model may add extra attributes after name
# e.g., <parameter name="cmd" description="(e.g. ls)">
name_end
=
remaining
.
find
(
">"
)
attr_section
=
remaining
[:
name_end
]
self
.
current_param_name
=
self
.
_parse_name_from_attributes
(
attr_section
)
# Find the parameter value
value_start
=
param_start
+
name_end
+
1
value_text
=
tool_text
[
value_start
:]
if
value_text
.
startswith
(
"
\n
"
):
value_text
=
value_text
[
1
:]
# Find where this parameter ends
param_end_idx
=
value_text
.
find
(
self
.
parameter_end_token
)
if
param_end_idx
==
-
1
:
# No closing tag, look for next parameter or function end
next_param_idx
=
value_text
.
find
(
self
.
parameter_prefix
)
func_end_idx
=
value_text
.
find
(
self
.
invoke_end_token
)
if
next_param_idx
!=
-
1
and
(
func_end_idx
==
-
1
or
next_param_idx
<
func_end_idx
):
param_end_idx
=
next_param_idx
elif
func_end_idx
!=
-
1
:
param_end_idx
=
func_end_idx
else
:
# Neither found, check if tool call is complete
if
self
.
invoke_end_token
in
tool_text
:
# Tool call and parameter is complete
param_end_idx
=
len
(
value_text
)
else
:
# Still streaming, wait for more content
return
None
if
param_end_idx
!=
-
1
:
# Complete parameter found
param_value
=
value_text
[:
param_end_idx
]
if
param_value
.
endswith
(
"
\n
"
):
param_value
=
param_value
[:
-
1
]
# Store raw value for later processing
self
.
accumulated_params
[
self
.
current_param_name
]
=
param_value
# Get parameter configuration with anyOf support
param_config
=
{}
if
self
.
streaming_request
and
self
.
streaming_request
.
tools
:
for
tool
in
self
.
streaming_request
.
tools
:
if
(
hasattr
(
tool
,
"function"
)
and
tool
.
function
.
name
==
self
.
current_function_name
and
hasattr
(
tool
.
function
,
"parameters"
)
):
params
=
tool
.
function
.
parameters
if
(
isinstance
(
params
,
dict
)
and
"properties"
in
params
):
param_config
=
params
[
"properties"
]
break
# Get parameter types (supports anyOf/oneOf/allOf)
param_type
=
self
.
_get_param_types_from_config
(
self
.
current_param_name
,
param_config
)
converted_value
=
self
.
_convert_param_value_with_types
(
param_value
,
param_type
)
# Build JSON fragment based on the converted type
# Use json.dumps to properly serialize the value
serialized_value
=
json
.
dumps
(
converted_value
,
ensure_ascii
=
False
)
if
self
.
param_count
==
0
:
json_fragment
=
(
f
'"
{
self
.
current_param_name
}
":
{
serialized_value
}
'
)
else
:
json_fragment
=
(
f
', "
{
self
.
current_param_name
}
":
{
serialized_value
}
'
)
self
.
param_count
+=
1
# Update streamed_args_for_tool for this tool call
if
self
.
current_tool_index
<
len
(
self
.
streamed_args_for_tool
):
self
.
streamed_args_for_tool
[
self
.
current_tool_index
]
+=
(
json_fragment
)
return
DeltaMessage
(
tool_calls
=
[
DeltaToolCall
(
index
=
self
.
current_tool_index
,
function
=
DeltaFunctionCall
(
arguments
=
json_fragment
),
)
]
)
return
None
\ No newline at end of file
config.json
deleted
100644 → 0
View file @
9d2097be
{
"architectures"
:
[
"MiniMaxM2ForCausalLM"
],
"attention_dropout"
:
0.0
,
"attn_type_list"
:
[
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
,
1
],
"auto_map"
:
{
"AutoConfig"
:
"configuration_minimax_m2.MiniMaxM2Config"
,
"AutoModelForCausalLM"
:
"modeling_minimax_m2.MiniMaxM2ForCausalLM"
},
"bos_token_id"
:
null
,
"eos_token_id"
:
null
,
"head_dim"
:
128
,
"hidden_act"
:
"silu"
,
"hidden_size"
:
3072
,
"initializer_range"
:
0.02
,
"intermediate_size"
:
1536
,
"layernorm_full_attention_beta"
:
1.0
,
"layernorm_linear_attention_beta"
:
1.0
,
"layernorm_mlp_beta"
:
1.0
,
"max_position_embeddings"
:
196608
,
"mlp_intermediate_size"
:
8192
,
"model_type"
:
"minimax_m2"
,
"mtp_transformer_layers"
:
1
,
"num_attention_heads"
:
48
,
"num_experts_per_tok"
:
8
,
"num_hidden_layers"
:
62
,
"num_key_value_heads"
:
8
,
"num_local_experts"
:
256
,
"num_mtp_modules"
:
3
,
"output_router_logits"
:
false
,
"qk_norm_type"
:
"per_layer"
,
"rms_norm_eps"
:
1e-06
,
"rope_theta"
:
5000000
,
"rotary_dim"
:
64
,
"router_aux_loss_coef"
:
0.001
,
"router_jitter_noise"
:
0.0
,
"scoring_func"
:
"sigmoid"
,
"shared_intermediate_size"
:
0
,
"shared_moe_mode"
:
"sigmoid"
,
"sliding_window"
:
null
,
"tie_word_embeddings"
:
false
,
"transformers_version"
:
"4.57.1"
,
"use_cache"
:
true
,
"use_mtp"
:
true
,
"use_qk_norm"
:
true
,
"use_routing_bias"
:
true
,
"vocab_size"
:
200064
}
doc/result-minimax-m2_1.png
View replaced file @
9d2097be
View file @
688d8492
232 KB
|
W:
|
H:
257 KB
|
W:
|
H:
2-up
Swipe
Onion skin
doc/results-minimax-m2_1-tool.png
0 → 100644
View file @
688d8492
129 KB
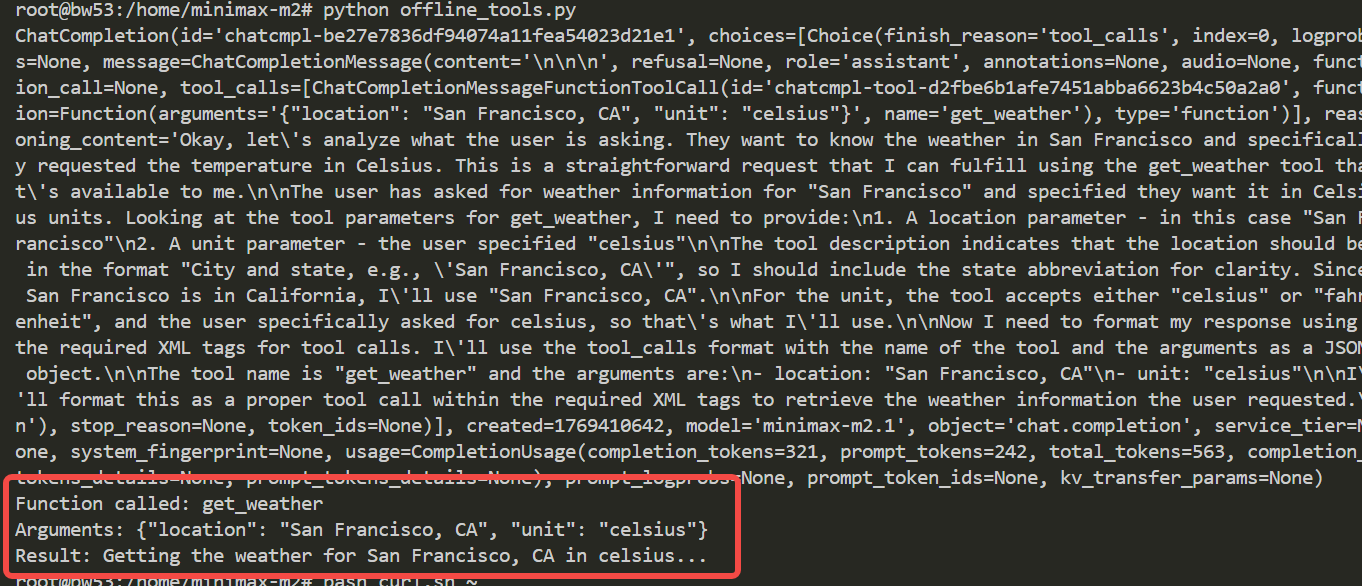
offline_tools.py
0 → 100644
View file @
688d8492
from
openai
import
OpenAI
import
json
client
=
OpenAI
(
base_url
=
"http://localhost:8001/v1"
,
api_key
=
"dummy"
)
def
get_weather
(
location
:
str
,
unit
:
str
):
return
f
"Getting the weather for
{
location
}
in
{
unit
}
..."
tool_functions
=
{
"get_weather"
:
get_weather
}
tools
=
[{
"type"
:
"function"
,
"function"
:
{
"name"
:
"get_weather"
,
"description"
:
"Get the current weather in a given location"
,
"parameters"
:
{
"type"
:
"object"
,
"properties"
:
{
"location"
:
{
"type"
:
"string"
,
"description"
:
"City and state, e.g., 'San Francisco, CA'"
},
"unit"
:
{
"type"
:
"string"
,
"enum"
:
[
"celsius"
,
"fahrenheit"
]}
},
"required"
:
[
"location"
,
"unit"
]
}
}
}]
response
=
client
.
chat
.
completions
.
create
(
model
=
client
.
models
.
list
().
data
[
0
].
id
,
messages
=
[{
"role"
:
"user"
,
"content"
:
"What's the weather like in San Francisco? use celsius."
}],
tools
=
tools
,
tool_choice
=
"auto"
)
print
(
response
)
tool_call
=
response
.
choices
[
0
].
message
.
tool_calls
[
0
].
function
print
(
f
"Function called:
{
tool_call
.
name
}
"
)
print
(
f
"Arguments:
{
tool_call
.
arguments
}
"
)
print
(
f
"Result:
{
get_weather
(
**
json
.
loads
(
tool_call
.
arguments
))
}
"
)
\ No newline at end of file
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}
{kind=link}