# Mini-Gemini
## 论文
- https://arxiv.org/pdf/2403.18814.pdf
## 模型结构
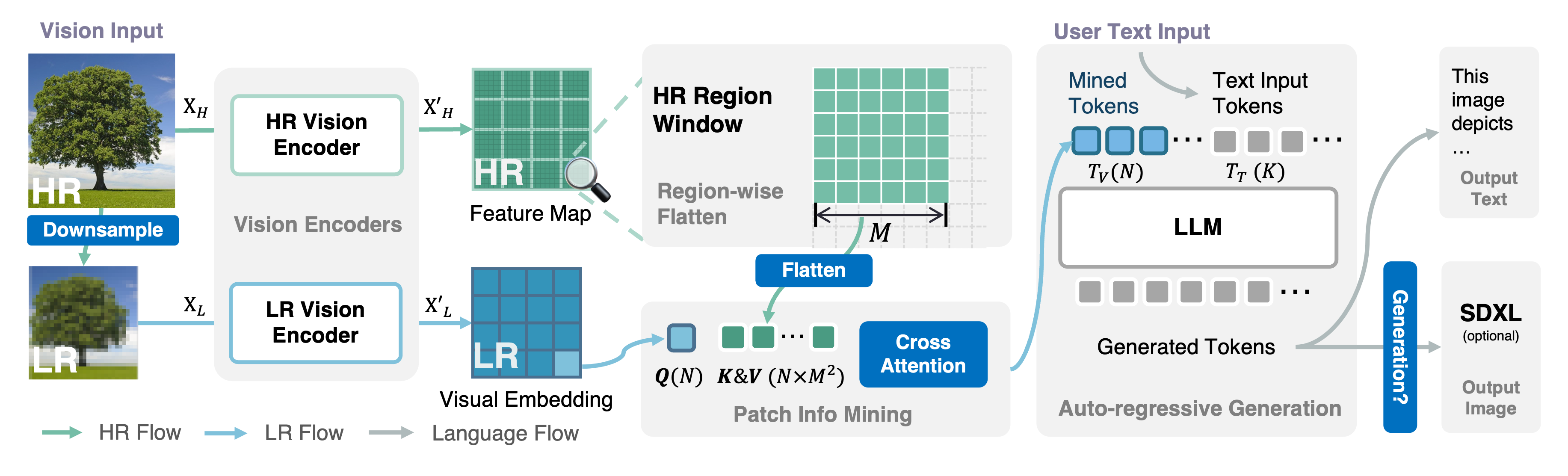
论文探讨了如何在学术环境下以低成本推动视觉语言模型(VLM)的发展,提出Mini-Gemini,通过双视觉编码器、高效处理高分辨率图像和高质量数据,实现了在保持效率的同时提取更多细节。
## 算法原理
论文主要从三个方面探索VLM(视觉大语言模型)的能力,分别是:
- 高分辨率的视觉tokens:
主要是通过双路视觉编码器,和其他多模态大模型不同的是,一路使用LAION-pretrained ConvNeXt-L作为视觉编码器处理高分辨率图像得到注意力机制中的K、V,另一路使用CLIP-pretrained-ViT作为视觉编码器处理低分辨率图像得到Q,然后通过CrossAttention(交叉注意力)得到增强后的视觉token,并且没有增加token的数量
- 高质量的数据:
主要是来源于之前其他多模态大模型研究中使用的公开数据集,再加上作者通过GPT4-Turbo得到的图像生成的指令数据集
- 扩展应用--指导图片生成模型:
通过讲用户指令转换成高质量的提示词使用文生图模型生成更高质量的图片
## 环境配置
### Docker(方法一)
从[光源](https://www.sourcefind.cn/#/service-list)中拉取docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
```
创建容器并挂载目录进行开发:
```
docker run -it --name {name} --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v {}:{} {docker_image} /bin/bash
# 修改1 {name} 需要改为自定义名称,建议命名{框架_dtk版本_使用者姓名},如果有特殊用途可在命名框架前添加命名
# 修改2 {docker_image} 需要需要创建容器的对应镜像名称,如: pytorch:1.10.0-centos7.6-dtk-23.04-py37-latest【镜像名称:tag名称】
# 修改3 -v 挂载路径到容器指定路径
pip install -e .
# paddlepaddle安装,使用DAS1.1版本的paddlepaddle,whl直链下载安装:
wget https://cancon.hpccube.com:65024/directlink/4/paddle/DAS1.1/paddlepaddle-2.5.2_dtk2404_git7ad272b3-cp310-cp310-manylinux2014_x86_64.whl
pip install paddlepaddle-2.5.2_dtk2404_git7ad272b3-cp310-cp310-manylinux2014_x86_64.whl
# 然后再安装pddleocr
pip install paddleocr==2.7.3
```
### Dockerfile(方法二)
```
cd docker
docker build --no-cache -t mgm_pytorch:1.0 .
docker run -it --name {name} --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v {}:{} {docker_image} /bin/bash
pip install -e .
# paddlepaddle安装,使用DAS1.1版本的paddlepaddle,whl直链下载安装:
wget https://cancon.hpccube.com:65024/directlink/4/paddle/DAS1.1/paddlepaddle-2.5.2_dtk2404_git7ad272b3-cp310-cp310-manylinux2014_x86_64.whl
pip install paddlepaddle-2.5.2_dtk2404_git7ad272b3-cp310-cp310-manylinux2014_x86_64.whl
# 然后再安装pddleocr
pip install paddleocr==2.7.3
```
### Anaconda(方法三)
线上节点推荐使用conda进行环境配置。
创建python=3.10的conda环境并激活
```
conda create -n mgm python=3.10
conda activate mgm
```
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.1
python:python3.10
pytorch:2.1.0
torchvision:0.16.0
```
安装其他依赖包
```
pip install -e .
# paddlepaddle安装,使用DAS1.1版本的paddlepaddle,whl直链下载安装:
wget https://cancon.hpccube.com:65024/directlink/4/paddle/DAS1.1/paddlepaddle-2.5.2_dtk2404_git7ad272b3-cp310-cp310-manylinux2014_x86_64.whl
pip install paddlepaddle-2.5.2_dtk2404_git7ad272b3-cp310-cp310-manylinux2014_x86_64.whl
# 然后再安装pddleocr
pip install paddleocr==2.7.3
```
## 数据集
HuggingFace数据集[下载镜像](https://hf-mirror.com/)
- pretrain数据集
[LLaVA Images](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain) -> data/MGM-Pretrain/images, data/MGM-Finetune/llava/LLaVA-Pretrain/images
[ALLaVA Caption](https://github.com/FreedomIntelligence/ALLaVA) -> data/MGM-Pretrain/ALLaVA-4V
- finetuning数据集
[ChartQA](https://github.com/vis-nlp/ChartQA) -> data/MGM-Finetune/chartqa
- 测试集
[MMMU](https://huggingface.co/datasets/MMMU/MMMU/tree/main) -> data/MGM-Eval/MMMU
[MMB](https://github.com/open-compass/mmbench/) -> data/MGM-Eval/mmbench
[MathVista](https://mathvista.github.io/) -> data/MGM-Eval/MathVista
数据目录结构如下:
```
MGM
├── mgm
├── scripts
├── work_dirs
│ ├── MGM
│ │ ├── MGM-7B-HD
├── model_zoo
│ ├── LLM
│ │ ├── vicuna
│ │ │ ├── 7B-V1.5
│ ├── OpenAI
│ │ ├── clip-vit-large-patch14-336
│ │ ├── openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup
│ ├── StableDiffusion
│ │ ├── stable-diffusion-xl-base-1.0
├── data
│ ├── MGM-Pretrain
│ │ ├── mgm_pretrain.json
│ │ ├── images
│ │ ├── ALLaVA-4V
│ ├── MGM-Finetune
│ │ ├── chartqa
│ ├── MGM-Eval
│ │ ├── MMMU
│ │ ├── mmbench
│ │ ├── MathVista
```
下载其他meta信息并放置在目录结构对应位置:
[mgm_pretrain.json](https://huggingface.co/datasets/YanweiLi/MGM-Pretrain)
[mgm_instruction.json](https://huggingface.co/datasets/YanweiLi/MGM-Instruction)
[mm_projector.bin](https://huggingface.co/YanweiLi/MGM-Pretrain/tree/main)
## 训练
下载CLIP、LLM以及MGM的预训练权重:
CLIP预训练权重:
[CLIP-Vit-L-336](https://huggingface.co/openai/clip-vit-large-patch14-336)
[OpenCLIP-ConvNeXt-L](https://huggingface.co/laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft-soup)
LLM模型:
[Vicuna-7b-v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5)
[stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main)
MGM模型:
[MGM-7B-HD](https://huggingface.co/YanweiLi/MGM-7B-HD)
保存到目录结构对应位置。
本项目的pretrain和finetune仅使用了上述的部分数据集,pretrian使用[LLaVA Images](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain) -> data/MGM-Pretrain/images,finetune使用[ChartQA](https://github.com/vis-nlp/ChartQA) -> data/MGM-Finetune/chartqa,因为原项目是给了整个pretrain和finetune的文件索引json文件,在__getitem__会报错(没有对应的目录),修改了加载json文件的代码:
```
[-] self.list_data_dict = list_data_dict
[+] list_data_dict_custom = []
[+] for data_dict in list_data_dict:
[+] if 'image' not in data_dict:
[+] continue
[+] if data_dict['image'].split('/')[0] == 'images' or data_dict['image'].split('/')[0] == 'chartqa':
[+] list_data_dict_custom.append(data_dict)
[+] rank0_print("Formatting inputs...Skip in lazy mode")
[+] self.list_data_dict = list_data_dict_custom
```
### 单机单卡
```
# 修改--include="localhost:4",调整显卡
# 可以选择wandb进行可视化,需要登录wandb账户
# Pretrain,使用的数据集较小,损失优化不稳定
bash scripts/llama/train/stage_1_2_full_v7b_336_hr_768_pretrain.sh
# Finetune
bash scripts/llama/train/stage_1_2_full_v7b_336_hr_768_finetune.sh
```
### 单机多卡
```
# 修改--include="localhost:3,4",调整显卡
# Pretrain
bash scripts/llama/train/stage_1_2_full_v7b_336_hr_768_pretrain.sh
# Pretrain
bash scripts/llama/train/stage_1_2_full_v7b_336_hr_768_finetune.sh
```
## 测试
```
# 修改HIP_VISIBLE_DEVICES='5',调整显卡
# 需要调整transformers版本
pip install transformers==4.37.2
bash scripts/llama/eval/mmmu.sh
```
## 推理
```
# 需要调整transformers版本
pip install transformers==4.37.2
# 模型推理,可以修改model-path调整推理模型,--gen使用stabledefussion
python -m mgm.serve.cli \
--model-path work_dirs/MGM/MGM-7B-HD \
--image-file images/dog.jpeg \
--gen
```
## result
输入图片为:
提示词:
```
what if my dog wear a scarf?
```
模型生成图片:
### Web UI推理
1、Launch a controller.
```
python -m mgm.serve.controller --host 0.0.0.0 --port 10000
```
2、Launch a gradio web server.
```
# 屏幕会输出一个URL链接,可以通过URL打开web界面,但此时还没有加载模型
python -m mgm.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
```
3、Launch a model worker.
```
# 加载模型,然后刷新上面的界面
python -m mgm.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path work_dirs/MGM/MGM-8B
```
### 精度
模型在MMMU测试数据集的测试指标:
| 模型 | 数据类型 | acc |
| :------: | :------: | :------: |
| [MGM-2B](https://huggingface.co/YanweiLi/MGM-2B) | fp16 | 0.3233 |
| [MGM-7B-HD](https://huggingface.co/YanweiLi/MGM-8B) | fp16 | 0.3733 |
## 应用场景
### 算法类别
多模态
### 热点应用行业
AIGC,设计,教育
## 源码仓库及问题反馈
[https://developer.hpccube.com/codes/modelzoo/Mini-Gemini_pytorch](https://developer.hpccube.com/codes/modelzoo/Mini-Gemini_pytorch)
## 参考资料
[https://github.com/dvlab-research/MiniGemini](https://github.com/dvlab-research/MiniGemini)