
Initial commit
Showing
.gitignore
0 → 100644
.vscode/settings.json
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_en.md
0 → 100644
This diff is collapsed.
README_zh_minicpm.md
0 → 100644
This diff is collapsed.
assets/dtk.png
0 → 100644
{kind=link}
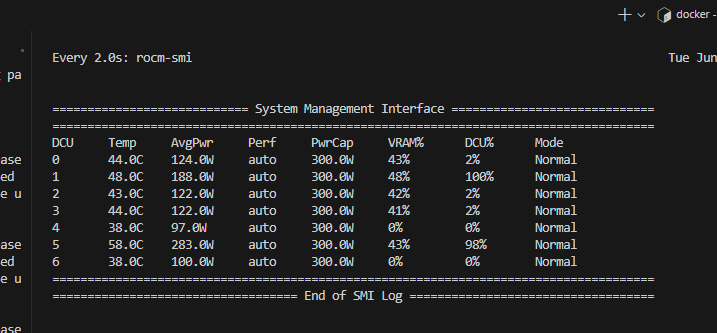
15.6 KB
File added
assets/radar_omnilmm12b.png
0 → 100644
{kind=link}
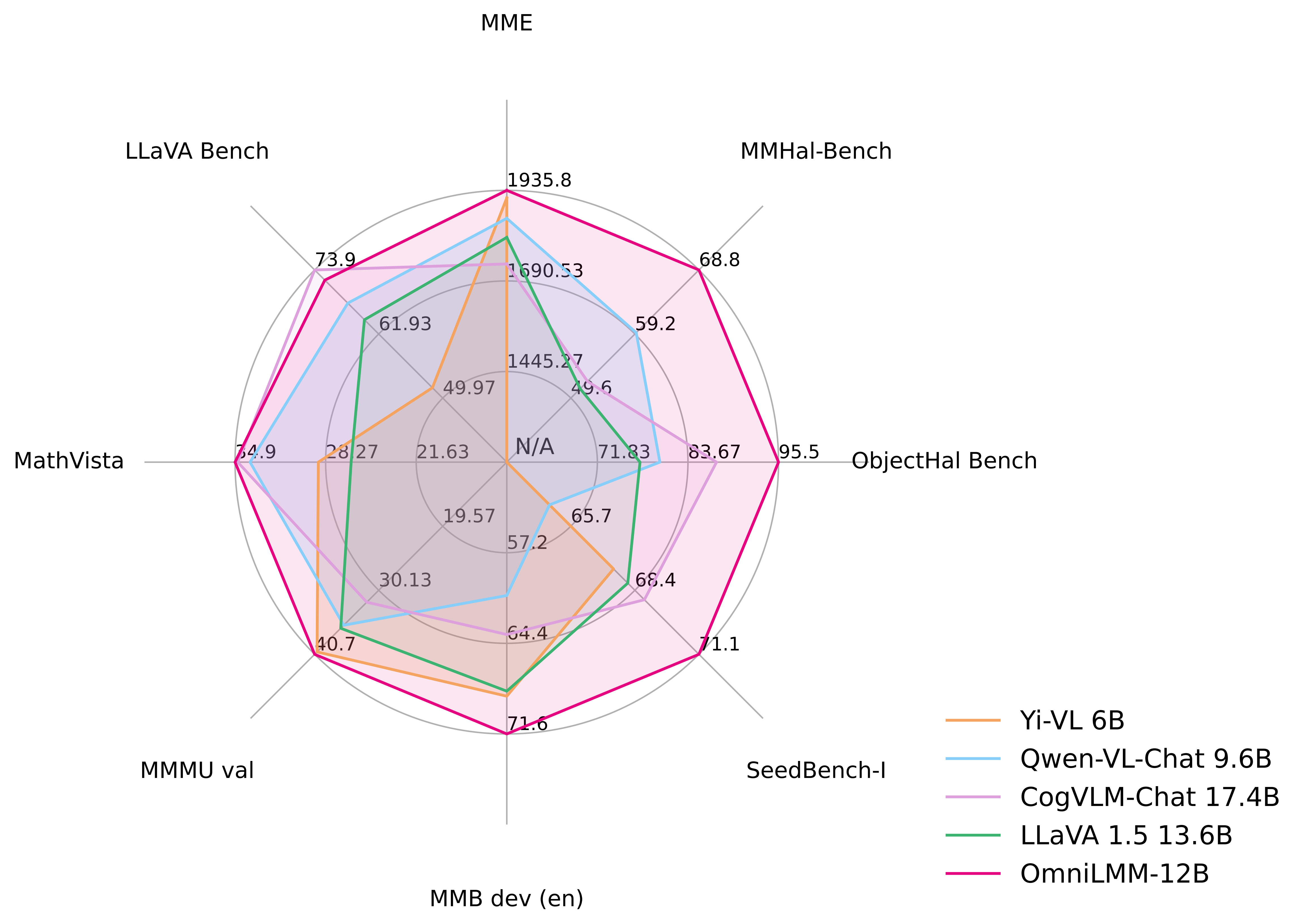
784 KB
assets/result_1.png
0 → 100644
{kind=link}
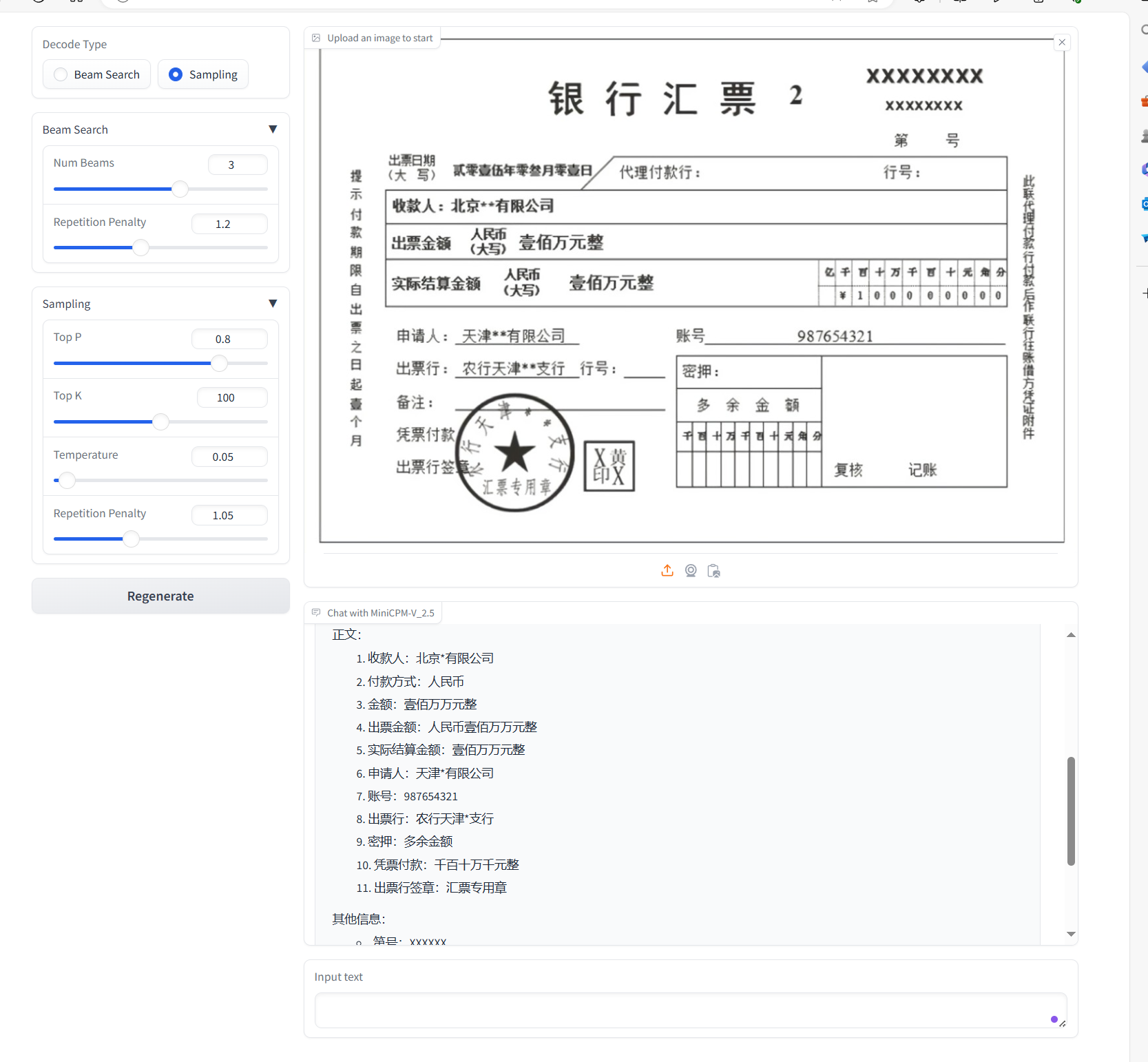
447 KB
assets/result_2.png
0 → 100644
{kind=link}
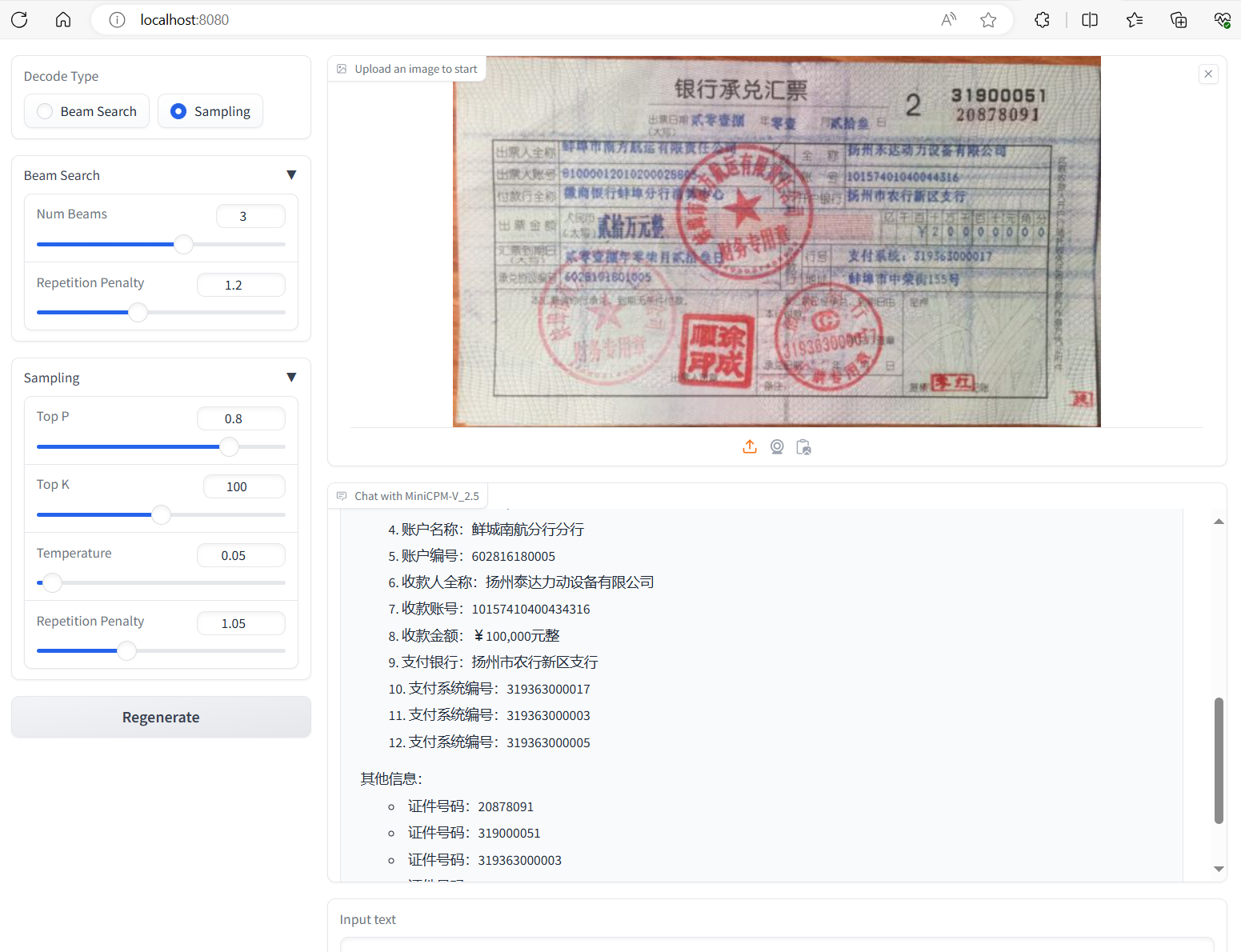
1.06 MB
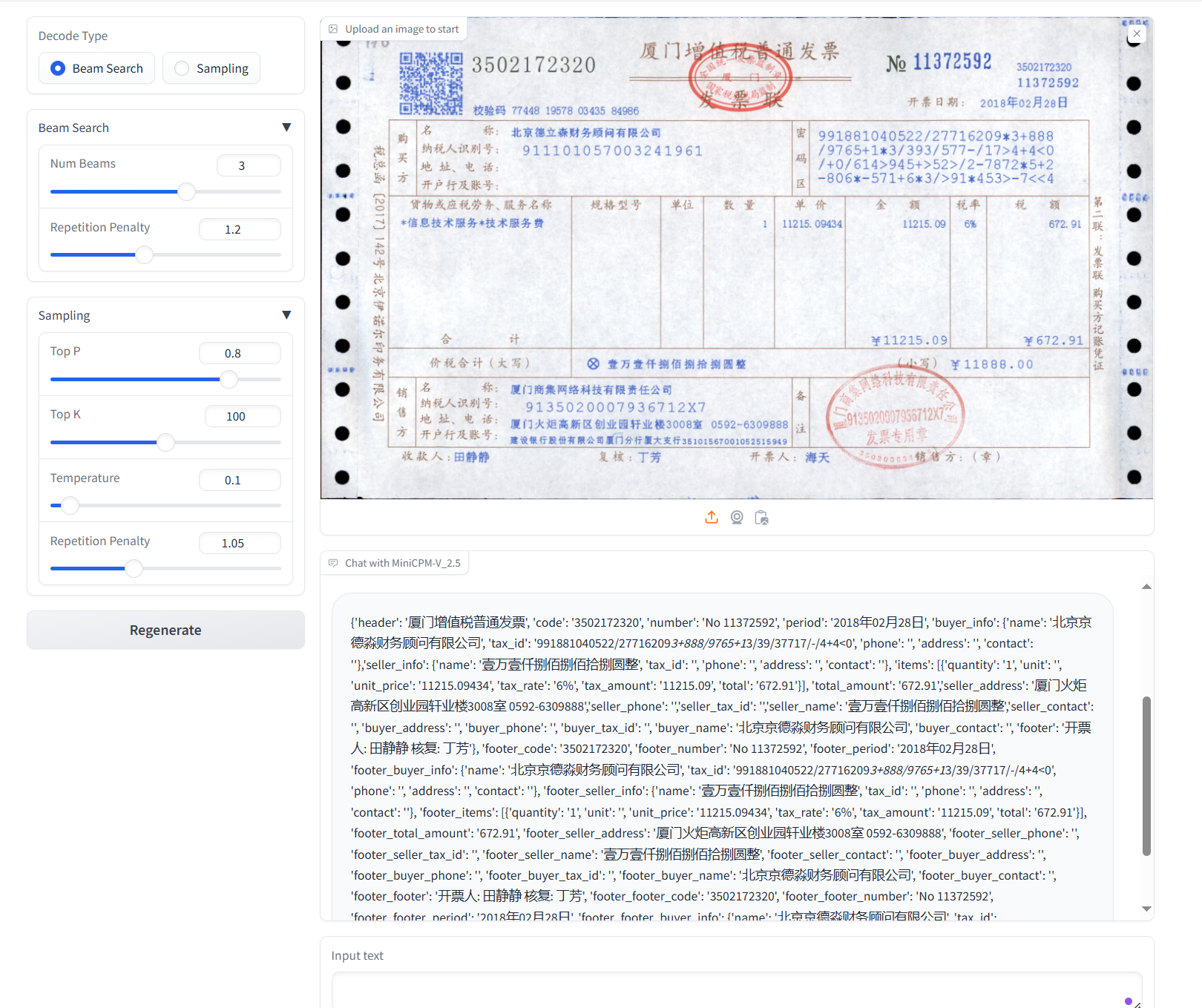
assets/result_3.png
0 → 100644
{kind=link}
1.51 MB
assets/title-2.png
0 → 100644
{kind=link}

45.6 KB
assets/transformer.jpg
0 → 100644
{kind=link}
87.9 KB
assets/transformer.png
0 → 100644
{kind=link}
112 KB
chat.py
0 → 100644