# MiniCPM-o 2.6
## 论文
[MiniCPM-o 2.6: A GPT-4o Level MLLM for Vision, Speech, and Multimodal Live Streaming on Your Phone](https://openbmb.notion.site/MiniCPM-o-2-6-A-GPT-4o-Level-MLLM-for-Vision-Speech-and-Multimodal-Live-Streaming-on-Your-Phone-185ede1b7a558042b5d5e45e6b237da9)
## 模型结构
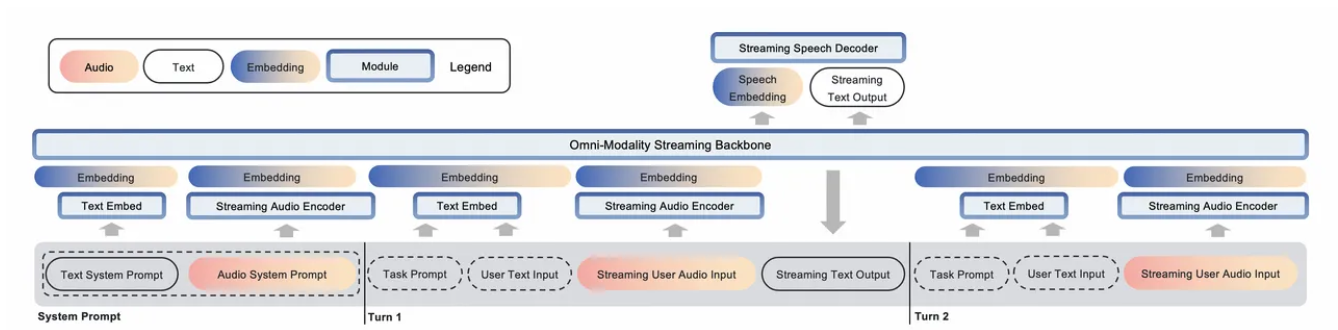
MiniCPM-o 2.6用于端到端全模态建模的整体架构。该模型基于SigLip-400M Whisper-medium-300M ChatTTS-200M和Qwen2.5-7B-Instruct构建,共有8B个参数。总体框架如下所示。
## 算法原理
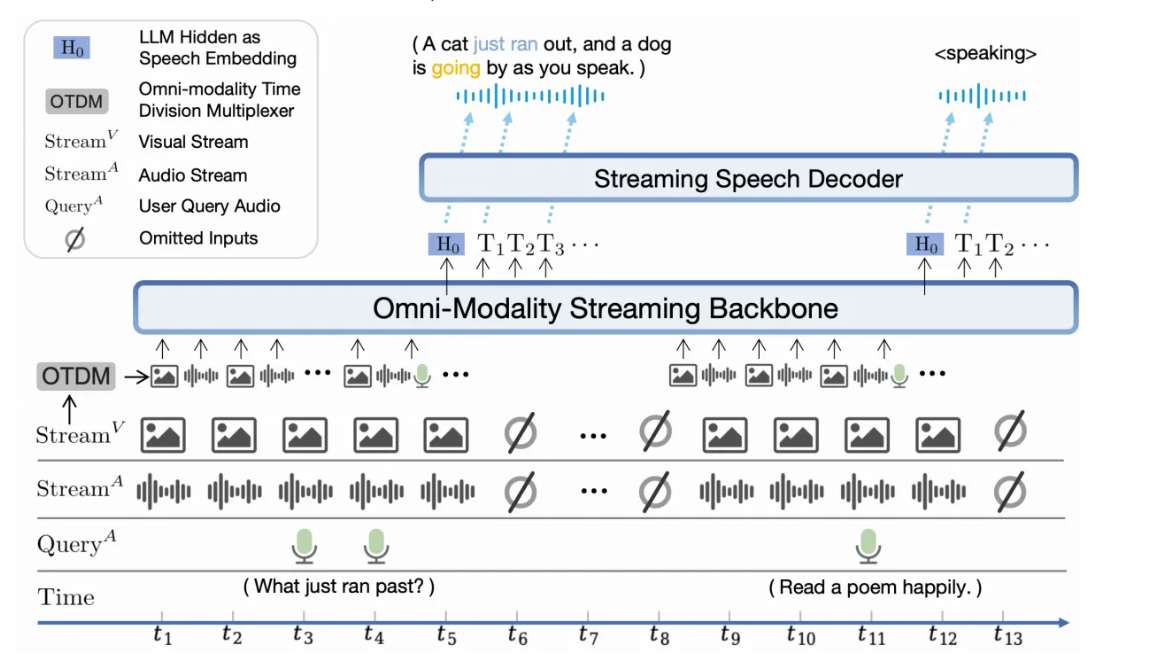
全模态直播流机制,包括(1)将语音编码器和解码器改为在线流,以及(2)使LLM主干网能够处理并行的多模态流信息。MiniCPM-o 2.6将输入音频分成块,其中块是对应于一秒钟音频的固定数量的音频令牌。在音频编码期间,每个块在关注自身和先前块的因果注意力范例中被编码,以(1)服务于在线流编码需求,同时(2)与离线整体编码相比保持最小的信息损失。为了实现流式语音生成,每次预填充固定数量的文本令牌(大小为n的块),并且解码器立即解码固定数量的音频令牌(大小为m的块)。然后对下一个文本令牌和音频令牌重复该过程,依此类推。值得注意的是,文本块和它们对应的音频块之间的对齐并不精确,因此在实践中为文本令牌块大小保留了更大的预算。
## 环境配置
### Docker(方法一)
推荐使用docker方式运行, 此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-py3.10-dtk24.04.3-ubuntu20.04
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --network=host --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name minicpm_o bash # 为以上拉取的docker的镜像ID替换
git clone http://developer.sourcefind.cn/codes/modelzoo/minicpm-o-2.6_pytorch.git
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
docker build -t internvl:latest .
docker run --shm-size 500g --network=host --name=minicpm_o --privileged --device=/dev/kfd --network=host --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
git clone http://developer.sourcefind.cn/codes/modelzoo/minicpm-o-2.6_pytorch.gitit
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.3
python:3.10
torch:2.3.0
transformers==4.48.3
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirement.txt安装:
```
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
## 数据集
ms-swift 自带数据集 AI-ModelScope/LaTeX_OCR:human_handwrite#20000
## 训练
使用ms-swift框架微调
```
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simpl
```
### 单机多卡
sh finetune.sh
## 推理
### 单机多卡
音频推理:
```
CUDA_VISIBLE_DEVICES=0,1,2,3python minicpm-o_audio.py
```
视觉推理:
```
CUDA_VISIBLE_DEVICES=0,1,2,3python minicpm-o_version.py
```
## result
- 音频推理
- 视觉推理
### 精度
无
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`科研,教育,政府,金融`
## 预训练权重
预训练权重快速下载中心:[SCNet AIModels](https://www.scnet.cn/ui/aihub/models)
项目中的预训练权重可从快速下载通道下载:[openbmb/MiniCPM-o-2_6](https://gitlab.scnet.cn:9002/model/sugon_scnet/InfiniteYou.git)
HF/github下载地址为:[openbmb/MiniCPM-o-2_6](https://huggingface.co/openbmb/MiniCPM-o-2_6)
魔搭下载路径
- [openbmb/MiniCPM-o-2_6 魔搭下载](https://www.modelscope.cn/models/OpenBMB/MiniCPM-o-2_6/files)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/minicpm-o-2.6_pytorch.git
## 参考资料
- https://github.com/OpenBMB/MiniCPM-o

