
Initial commit
Showing
Dockerfile
0 → 100644
Pic/arch.png
0 → 100644
{kind=link}
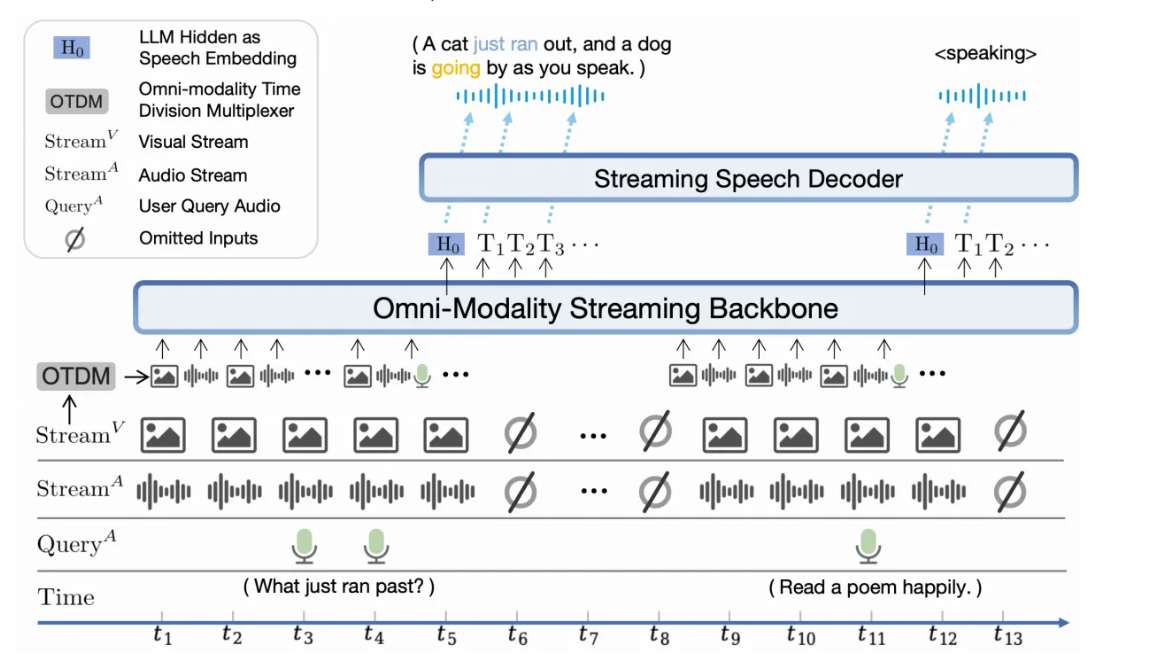
309 KB
Pic/result1.png
0 → 100644
{kind=link}

34.7 KB
Pic/result2.png
0 → 100644
{kind=link}

64.1 KB
Pic/theory.png
0 → 100644
{kind=link}
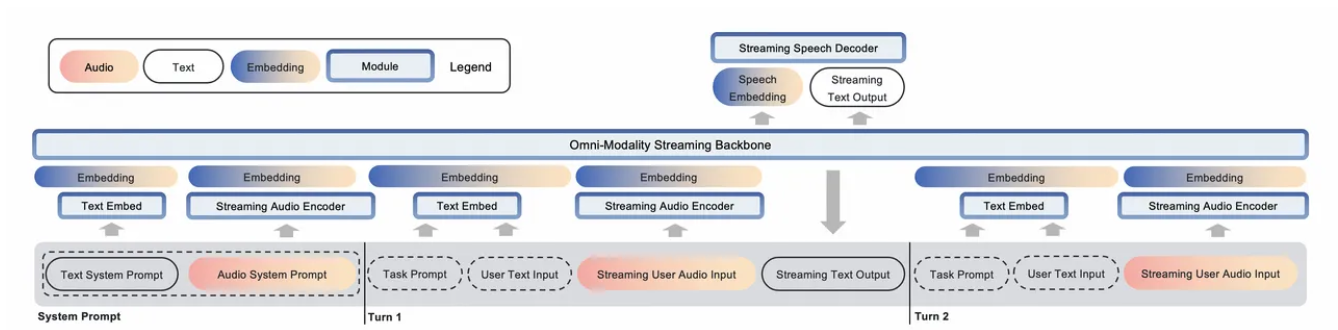
310 KB
README.md
0 → 100644
finetune.sh
0 → 100644
icon.png
0 → 100644
{kind=link}
53.8 KB
minicpm-o_audio.py
0 → 100644
minicpm-o_version.py
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| Pillow==10.1.0 | ||
| torch | ||
| torchaudio | ||
| torchvision | ||
| transformers==4.48.3 | ||
| librosa==0.9.0 | ||
| soundfile==0.12.1 | ||
| vector-quantize-pytorch==1.18.5 | ||
| vocos==0.1.0 | ||
| decord | ||
| moviepy==1.0.3 | ||
| modelscope | ||
| numpy==1.26.0 |