
v1.0
Showing
CLIP/setup.py
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
__init__.py
0 → 100644
data/figures/framework.jpeg
0 → 100644
{kind=link}
396 KB
data/figures/inputids.png
0 → 100644
{kind=link}
327 KB
data/figures/samples.png
0 → 100644
{kind=link}

2.45 MB
data/figures/title_new.png
0 → 100644
{kind=link}

347 KB
data/figures/training.jpeg
0 → 100644
{kind=link}
344 KB
data/omni2-demo.mp4
0 → 100644
File added
doc/omni2.png
0 → 100644
{kind=link}
214 KB
doc/train.png
0 → 100644
{kind=link}
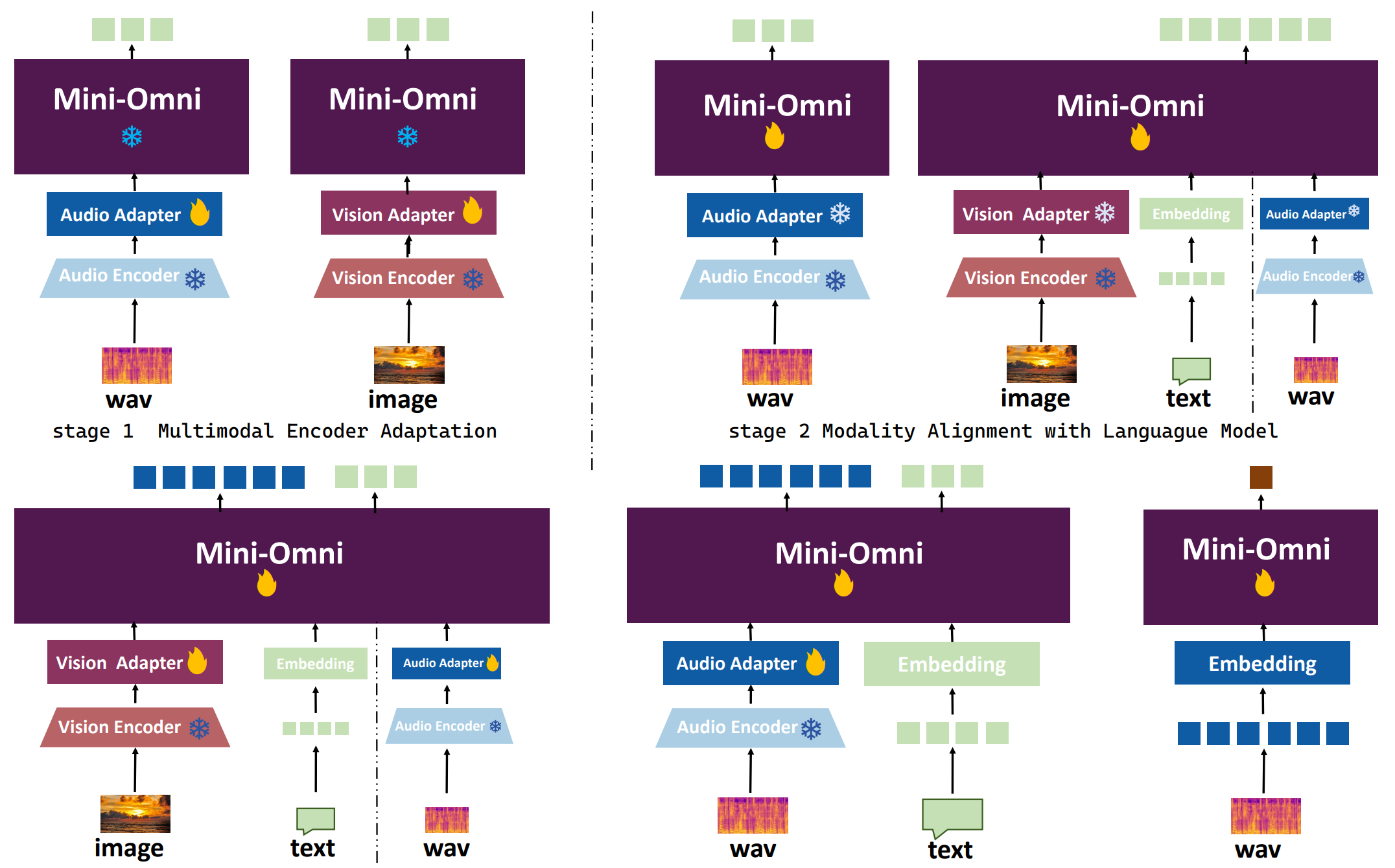
294 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
docker_start.sh
0 → 100644
icon.png
0 → 100644
{kind=link}
53.8 KB
inference.py
0 → 100644