# MinerU2.5
## 论文
`
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
`
- https://arxiv.org/abs/2509.22186
## 模型结构
MinerU 2.5 版本重点是介绍自 2.0 版本以来 vlm 端的进展,之前的集成处理方案(Pipeline)并没有大变化。
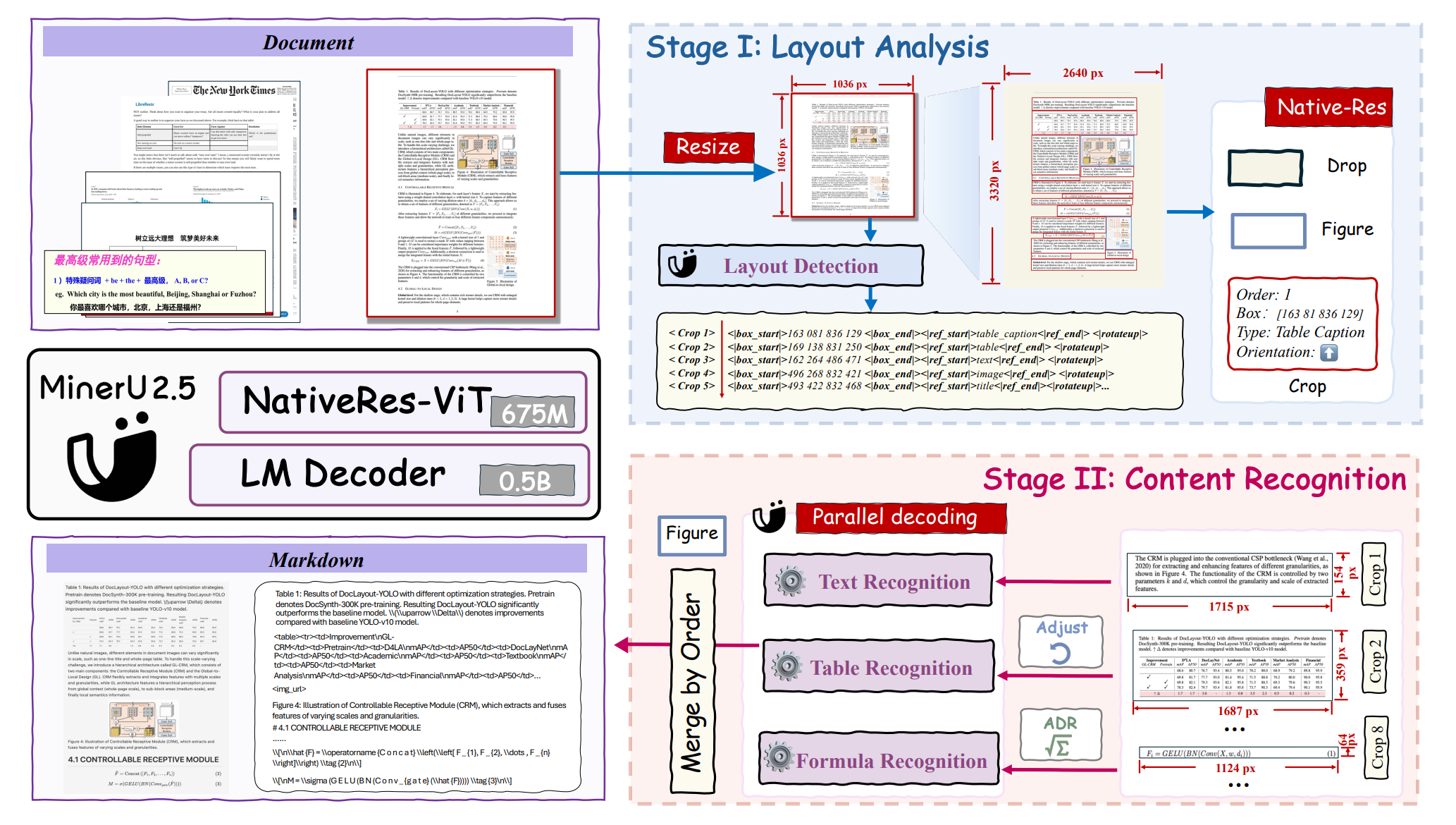
VLM 的核心创新是采用解耦架构,通过从粗到细两阶段推理机制,将全局布局分析与局部内容识别分离开。
在第一阶段,模型对下采样后的文档图像进行快速且整体的布局分析。
在第二阶段,在检测到的布局指导下,从原始高分辨率输入中裁剪关键区域,并在局部窗口中进行精细识别。
## 算法原理
MinerU 2.5 的模型由三个部分组成:
- 语言模型:因为文档解析任务通常对大规模语言模型的依赖性较低,为了更好地适应裁剪图像解析中不同的分辨率和宽高比, 将 0.5B 参数的 Qwen2-Instruct 模型原有的 1D-RoPE 替换为 M-RoPE ,从而增强了模型在不同分辨率下的泛化能力。
- 视觉编码器:受 Qwen2-VL 的启发,MinerU2.5 集成了一种原生分辨率编码机制。 虽然 Qwen2.5-VL 系列采用窗口注意力机制来提高效率,但这种设计会导致文档解析任务的性能下降。因此,采用基于 Qwen2-VL 初始化的 675M 参数 NaViT。
该视觉编码器支持动态图像分辨率,并采用 2D-RoPE 进行位置编码,使其能够灵活地处理各种分辨率和宽高比的输入。
- 图像块合并器:为了平衡效率和性能,该架构对相邻的 2×2 视觉标记使用像素解混,在将聚合的视觉标记传递给大型语言模型之前对其进行预处理。这种设计有效地实现了计算效率和任务性能之间的权衡。
## 环境配置
### 硬件需求
DCU型号:K100_AI,节点数量:1台,卡数:1张。
`-v 路径`、`docker_name`和`imageID`根据实际情况修改
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.5.1-ubuntu22.04-dtk25.04.2-py3.10
# 为以上拉取的docker的镜像ID替换
docker run -it --name mineru2.5 --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v $PWD/MinerU_pytorch:/home/MinerU2.5_vllm /bin/bash
cd /home/MinerU2.5_vllm
pip install -e .[core] -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install numpy==1.25.0
pip install -e .[all] --no-deps
```
### Dockerfile(方法二)
```
cd /home/MinerU2.5_vllm
docker build --no-cache -t MinerU2.5:latest .
# 为以上拉取的docker的镜像ID替换
docker run -it --name mineru2.5 --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v $PWD/MinerU_pytorch:/home/MinerU2.5_vllm /bin/bash
cd /home/MinerU2.5_vllm
pip install -e .[core] -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install numpy==1.25.0
pip install -e .[all] --no-deps
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk25.04.2
python:python3.10
torch:2.5.1
torchvision:0.20.1
triton:3.1
flash-attn:2.6.1
vllm:0.9.2
lmslim:0.3.1
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库安装,如果特殊深度学习库被替换,请重新安装上述适配版本
```
cd /home/MinerU2.5_vllm
pip install -e .[core] -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install numpy==1.25.0
pip install -e .[all] --no-deps
```
## 数据集
`无`
## 训练
`无`
## 推理
模型源配置
```
#下载模型设置环境变量:
export MINERU_MODEL_SOURCE=modelscope
#如需使用本地模型,可使用交互式命令行工具选择模型下载:
mineru-models-download --help
#下载完成后,模型路径会在当前终端窗口输出,并自动写入用户目录下的 mineru.json
```
### 单机单卡
```
cd /home/MinerU2.5_vllm
# Default parsing using pipeline backend
#:本地 PDF/图像文件或目录
#:输出目录
HIP_VISIBLE_DEVICES=0 mineru -p -o
# Or specify vlm backend for parsing
mineru -p -o -b vlm-transformers
#The vlm backend additionally supports vllm acceleration
mineru -p -o -b vlm-vllm-engine
#FastAPI calls
#Access http://127.0.0.1:8000/docs in your browser to view the API documentation.
mineru-api --host 0.0.0.0 --port 8000
#Start Gradio WebUI visual frontend
#Access http://127.0.0.1:7860 in your browser to use the Gradio WebUI.
# Using pipeline/vlm-transformers/vlm-http-client backends
mineru-gradio --server-name 0.0.0.0 --server-port 7860
# Or using vlm-vllm-engine/pipeline backends (requires vllm environment)
mineru-gradio --server-name 0.0.0.0 --server-port 7860 --enable-vllm-engine true
#Using http-client/server method:
# Start vllm server (requires vllm environment)
mineru-vllm-server --port 30000
#In another terminal, connect to vllm server via http client (only requires CPU and network, no vllm environment needed)
mineru -p -o -b vlm-http-client -u http://127.0.0.1:30000
```
更多资料可参考源项目中的[`README_ori`](./README_orgin.md)。
## result
解析示例:
layout:
解析结果:
### 精度
DCU与GPU精度一致,推理框架:pytorch、vllm。
## 应用场景
### 算法类别
`OCR`
### 热点应用行业
`科研,教育,政府,广媒`
## 预训练权重
魔搭社区下载地址为:[OpenDataLab/PDF-Extract-Kit-1.0](https://www.modelscope.cn/models/OpenDataLab/PDF-Extract-Kit-1.0)
transformers/vllm后端模型地址:[OpenDataLab/MinerU2.5-2509-1.2B](https://www.modelscope.cn/models/OpenDataLab/MinerU2.5-2509-1.2B)
注意:`自动下载模型建议加镜像源下载:export HF_ENDPOINT=https://hf-mirror.com`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/mineru2.5_vllm
## 参考资料
- https://github.com/opendatalab/MinerU