# MiMo-V2-Flash
## 论文
[MiMo-V2-Flash Technical Report](doc/paper.pdf)
## 模型简介
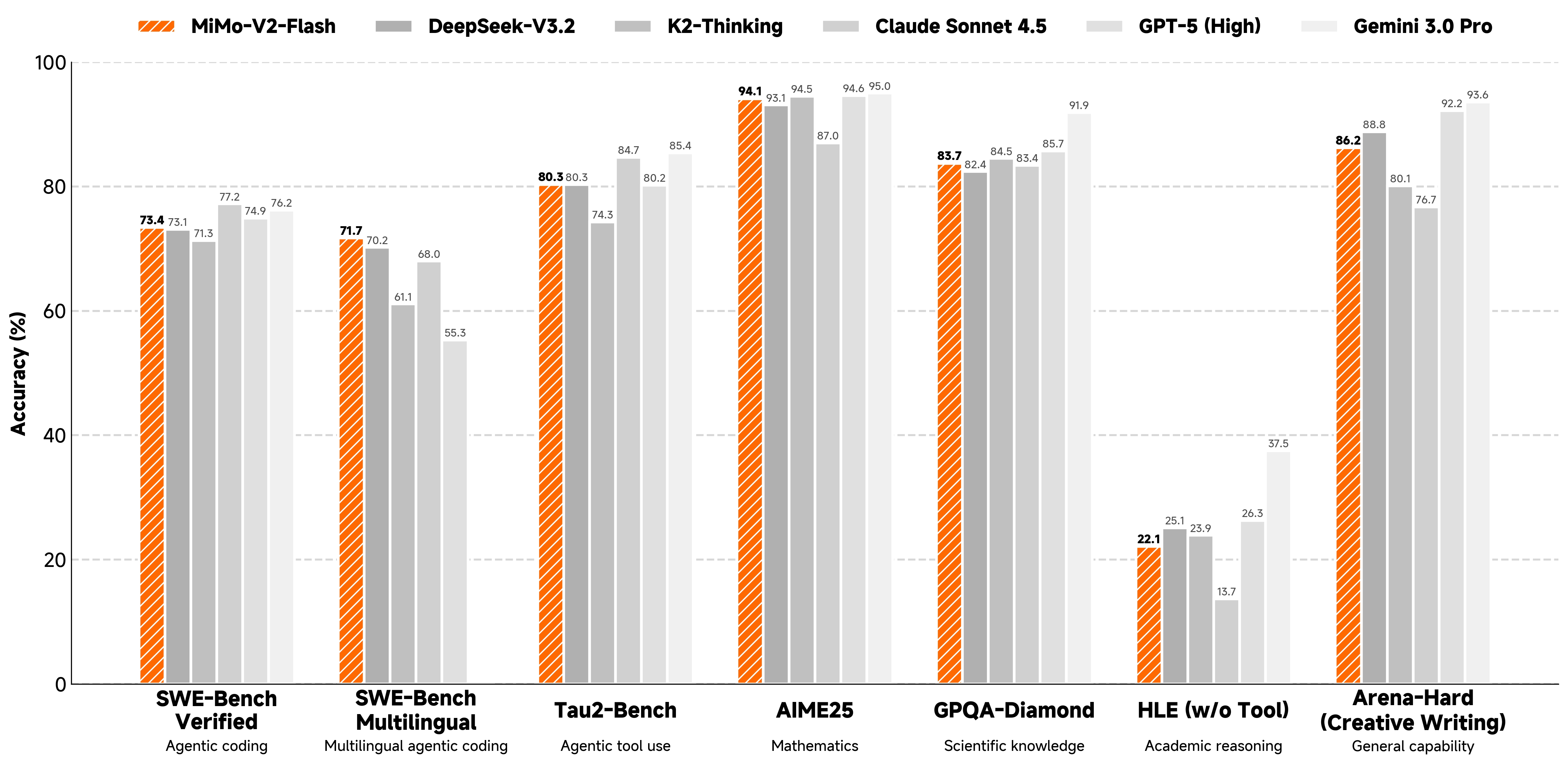
MiMo-V2-Flash 是一个混合专家(Mixture-of-Experts, MoE)语言模型,总参数量为 3090 亿,激活参数量为 150 亿。该模型专为高速推理和智能体工作流设计,采用了一种新颖的混合注意力架构和多词元预测(Multi-Token Prediction, MTP),在显著降低推理成本的同时实现了业界领先的性能。
MiMo-V2-Flash 在长上下文建模能力和推理效率之间实现了新的平衡。其主要特性包括:
- **混合注意力架构:**以 5:1 的比例交错使用滑动窗口注意力(Sliding Window Attention, SWA)和全局注意力(Global Attention, GA),并采用激进的 128 词元窗口。这使 KV 缓存存储需求减少了近 6 倍,同时通过可学习的 注意力汇聚偏置(attention sink bias) 保持了长上下文性能。
- **多词元预测(MTP):**配备轻量级 MTP 模块(每层 0.33B 参数),使用密集前馈网络(FFN)。这使推理时的输出速度提升三倍,并有助于加速强化学习(RL)训练中的 rollout 过程。
- **高效预训练:**使用 FP8 混合精度和原生 32k 序列长度,在 27T 词元上完成训练。上下文窗口最大支持 256k 长度。
- **智能体能力:**后训练阶段采用多教师在线策略蒸馏(Multi-Teacher On-Policy Distillation, MOPD)和大规模智能体强化学习,在 SWE-Bench 和复杂推理任务上表现卓越。
## 环境依赖
| 软件 | 版本 |
| :------: | :------: |
| DTK | 26.04 |
| Python | 3.10.12 |
| torch | 2.9.0+das.opt1.dtk2604.2604151933.g4ed9ab |
| triton | 3.3.0+das.opt2.dtk2604.torch290.20260331.g31542e |
| Transformers | 5.3.0 |
| SGLang | 2.9.0+das.opt1.dtk2604.2604151933.g4ed9ab |
推荐使用镜像: harbor.sourcefind.cn:5443/dcu/admin/base/custom:sglang-0.5.10-glm5-0416
- 挂载地址`-v`根据实际模型情况修改
```bash
docker run -it \
--shm-size 256g \
--network=host \
--name mimo-v2-flash \
--privileged \
--device=/dev/kfd \
--device=/dev/dri \
--device=/dev/mkfd \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
-u root \
-v /opt/hyhal/:/opt/hyhal/:ro \
-v /path/your_code_data/:/path/your_code_data/ \
harbor.sourcefind.cn:5443/dcu/admin/base/custom:sglang-0.5.10-glm5-0416 bash
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
## 数据集
`暂无`
## 训练
`暂无`
## 推理
### SGLang
#### 单机推理
1. 启动服务
```bash
export SGLANG_USE_LIGHTOP=1
export SGLANG_KV_LAYOUT_DCU_FA=0
export SGLANG_ENABLE_SPEC_V2=1
export SGLANG_USE_AITER_FP8_ASM_MOE=1
export SGLANG_USE_TRITON_EXTEND_FROM_AITER=1
sglang serve --model-path XiaomiMiMo/MiMo-V2-Flash \
--tp-size 4 \
--page-size 64 \
--host 0.0.0.0 \
--port 8001 \
--trust-remote-code \
--mem-fraction-static 0.85 \
--max-running-requests 64 \
--tool-call-parser mimo \
--context-length 262144 \
--attention-backend triton \
--chunked-prefill-size -1 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--disable-radix-cache
```
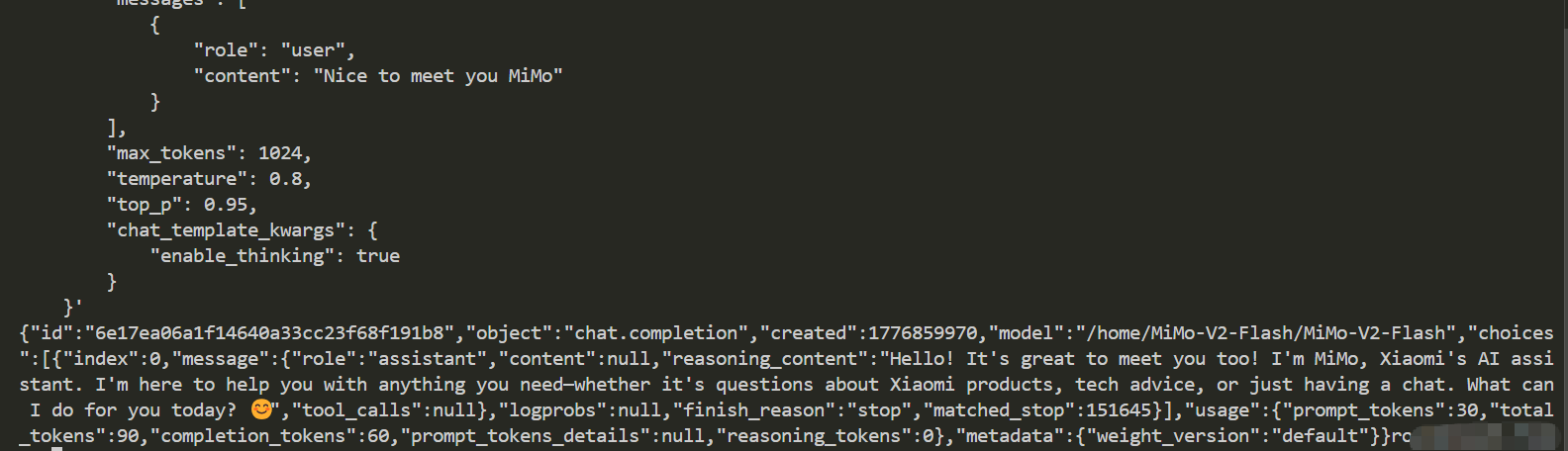
2. 访问推理服务
```bash
curl http://localhost:8001/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "XiaomiMiMo/MiMo-V2-Flash",
"messages": [
{
"role": "user",
"content": "Nice to meet you MiMo"
}
],
"max_tokens": 1024,
"temperature": 0.8,
"top_p": 0.95,
"chat_template_kwargs": {
"enable_thinking": true
}
}'
```
## 效果展示
### 精度
`DCU与GPU精度一致,推理框架:SGLang。`
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 |下载地址|
|:-----:|:----------:|:----------:|:---------------------:|:----------:|
| MiMo-V2-Flash | 309B | BW1100 | 4 | [ModelScope](https://modelscope.cn/models/XiaomiMiMo/MiMo-V2-Flash) |
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/mimo-v2-flash
## 参考资料
- https://github.com/XiaomiMiMo/MiMo-V2-Flash