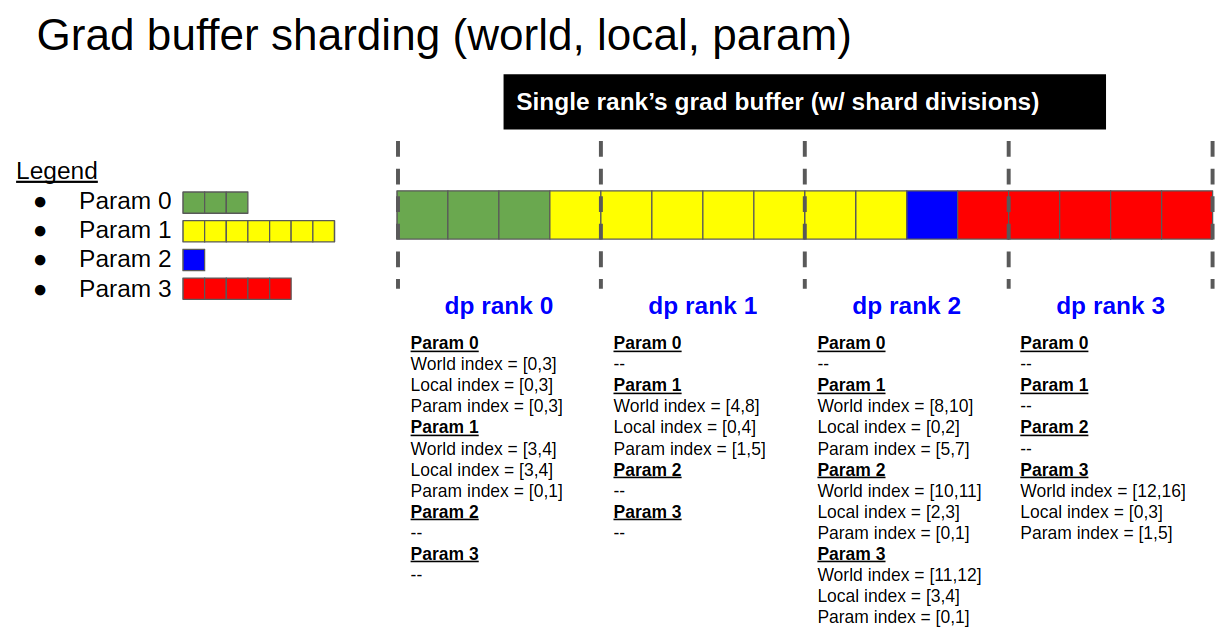
The motivation for the distributed optimizer is to save memory by distributing the optimizer state evenly across data parallel ranks, versus the current method of replicating the optimizer state across data parallel ranks. As described in https://arxiv.org/abs/1910.02054, this branch specifically implements the following:
- [yes] distribute all 'non-overlapping' optimizer state (i.e., model params already in fp32 are NOT distributed)
- [no] distribute model gradients
- [no] distribute model parameters
Theoretical memory savings vary depending on the combination of the model's param dtype and grad dtype. In the current implementation, the theoretical number of bytes per parameter is (where 'd' is the data parallel size):
| | Non-distributed optim | Distributed optim |
| ------ | ------ | ------ |
| float16 param, float16 grads | 20 | 4 + 16/d |
| float16 param, fp32 grads | 18 | 6 + 12/d |
| fp32 param, fp32 grads | 16 | 8 + 8/d |
The implementation of the distributed optimizer is centered on using the contiguous grad buffer for communicating grads & params between the model state and the optimizer state. The grad buffer at any given moment either holds:
1. all model grads
2. a 1/d size _copy_ of the main grads (before copying to the optimizer state)
3. a 1/d size _copy_ of the main params (after copying from the optimizer state)
4. all model params
5. zeros (or None), between iterations
The grad buffer is used for performing reduce-scatter and all-gather operations, for passing grads & params between the model state and optimizer state. With this implementation, no dynamic buffers are allocated.
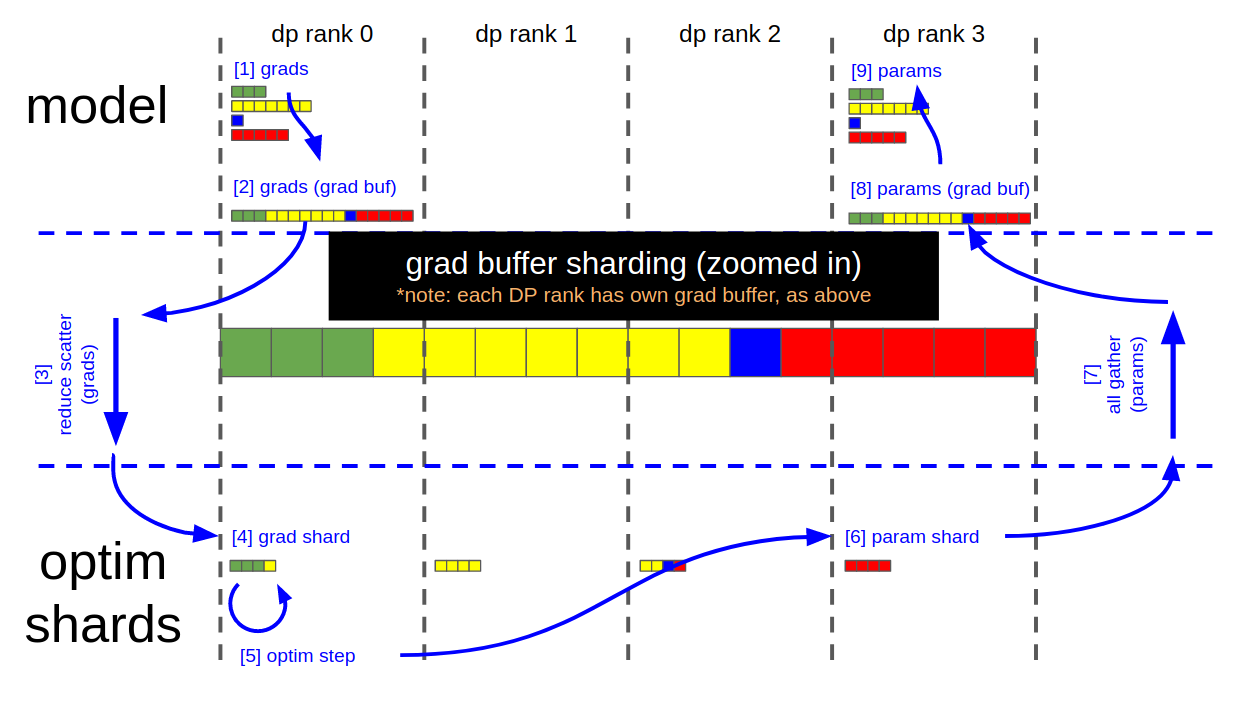
The figures below illustrate the grad buffer's sharding scheme, and the key steps of the distributed optimizer's param update:
- Each DP rank now has 4 elements within the grad buffer that are fully reduced (remaining 12 elements are garbage)
- Each DP rank copies its relevant 4 fp16 grad elements from the grad buffer into 4 fp32 main grad elements (separate buffer, owned by the optimizer); i.e.
- DP rank 0 copies elements [0:4]
- DP rank 1 copies elements [4:8]
- DP rank 2 copies elements [8:12]
- DP rank 3 copies elements [12:16]
- Optimizer.step()
- Each DP rank copies its 4 fp32 main (/optimizer) param elements into the corresponding 4 fp16 elements in the grad buffer
- Call all-gather on each DP rank
- Grad buffer now contains all 16, fully updated, fp16 model param elements
- Copy updated model params from grad buffer into their respective param tensors
- (At this point, grad buffer is ready to be zero'd for the next iteration)
This folder includes examples from the original NVIDIA/Megatron-LM repo. All of them do NOT have DeepSpeed technologies integrations, and some of them may not work due to changes in this Megatron-DeepSpeed repo. Thus we recommend you to go to ```../examples_deepspeed/``` folder which includes examples that have DeepSpeed technologies integrated and are tested by DeepSpeed team.
This is the official code base for our NeurIPS 2022 paper:
[Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models](https://arxiv.org/abs/2202.04173)
Boxin Wang, Wei Ping, Chaowei Xiao, Peng Xu, Mostofa Patwary, Mohammad Shoeybi, Bo Li, Anima Anandkumar, Bryan Catanzaro
## Citation
```
@article{WangExp2022,
title={Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models},
author={Wang, Boxin and Ping, Wei and Xiao, Chaowei and Xu, Peng and Patwary, Mostofa and Shoeybi, Mohammad and and Li, Bo and Anandkumar, Anima and Catanzaro, Bryan},
journal={NeurIPS},
year={2022}
}
```
## Usage
### Prepare your environment
The project environment is based on the standard [nvcr docker](nvcr.io/nvidia/pytorch:21.12-py3) of version `nvcr.io/nvidia/pytorch:21.12-py3`.
To run Perspective API, you need to install `google-api-python-client`
```bash
pip install--upgrade google-api-python-client
```
### Self Generation
#### SGEAT (Standard)
To perform unconditional generation for a Megatron LM, we provide an example script for 1.3B LM.
```bash
# [num of samples] [model checkpoint] [random seed]
This will generate a jsonl file of 1000 generated text (as a toy example) at `selfgeneration/unconditional_generation_gpt3-1.3b/2333.out`.
Note that you may want to set your own gpt2 vocab and merge file dir, as well as your output data dir in `selfgenerate-1.3b-unconditional.sh`.
### Annotation
We then use Perspective API to annotate the self generated corpus. Note that you need to fill in your own Perspective API key in the `examples/detoxify_lm/perspective_api_annotate.py`.
This will generate a jsonl file of 500 text of the lowest toxicity (as a toy example) at `selfgeneration/unconditional_generation_gpt3-1.3b/2333.annotated.nontoxic.out`.
### Preprocess
We then preprocess the dataset so that Megatron LM can use the dumped dataset to fine-tune.
For example, this will generate the continuations in the file `augmented_prompts.jsonl_output_gpt3-1.3b-toy-example-lr-2e-5-bs-512_seed_31846.jsonl` (seed is a random generated number).
Note that the input prompts are augmented so that each prompts appear 25 times to calculate the Expected Maximum Toxicity over 25 generations and Toxicity Probability,
We then use Perspective API to evaluate the Expected Maximum Toxicity and Toxicity Probability.

{kind=link}
{kind=link}