# Mamba2
## 论文
Mamba
`Mamba: Linear-Time Sequence Modeling with Selective State Spaces`
- https://arxiv.org/abs/2312.00752
Mamba2
`Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality`
- https://arxiv.org/abs/2405.21060
## 模型结构
许多二次时间架构,如线性注意力、门控卷积和循环模型,以及结构化状态空间模型(SSMs)已经被开发出来,以解决Transformer在长序列上的计算效率低下问题,
但它们在语言等重要模态上的表现不如注意力。作者发现这些模型的一个关键弱点是它们无法执行基于内容的推理,并进行了一些改进。
首先,仅仅让SSM参数作为输入的函数就能解决它们在离散模态上的弱点,使模型能够根据当前标记在序列长度维度上有选择性地传播或遗忘信息。其次,尽管这种变化阻碍了高效卷积的使用,
本文在循环模式下设计了一个硬件感知的并行算法,将这些选择性的SSM整合到一个简化的端到端神经网络架构中,
去掉了注意力机制甚至MLP模块(Mamba)。Mamba具有快速推理(吞吐量比Transformer高5倍)和序列长度的线性扩展能力,其在处理百万级别长度序列的真实数据时表现有所提升。
虽然Transformers一直是深度学习在语言建模成功的主要架构,但诸如Mamba等状态空间模型(SSM)最近被证明在小到中等规模上可以媲美甚至超越Transformers。
作者展示了这些模型家族实际上关系紧密,并开发了一个理论联系的丰富框架,将SSM与注意力机制的变体通过一种研究充分的结构化半分离矩阵类的各种分解联系在一起。
状态空间对偶(SSD)框架使作者能够设计出一种新架构(Mamba-2),其核心层是对Mamba选择性SSM的改进,速度提升了2-8倍,同时在语言建模方面仍能与Transformers竞争。
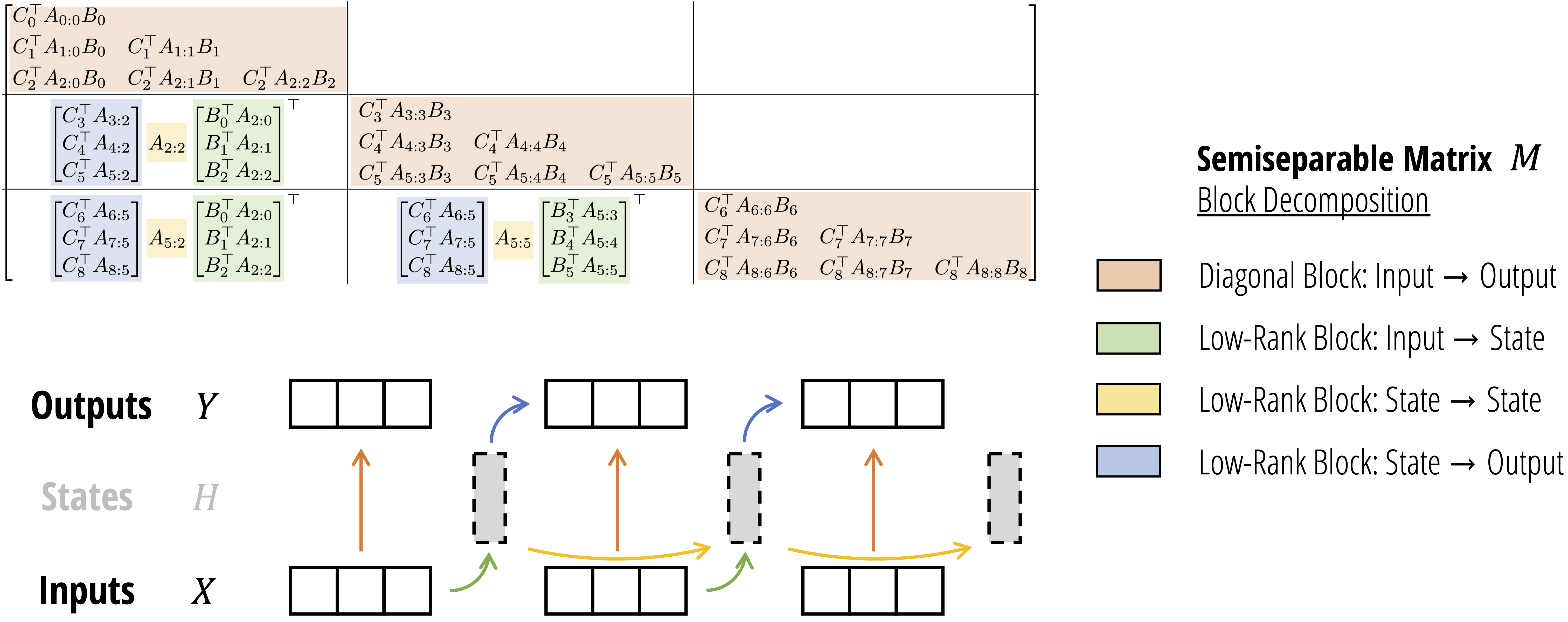
## 算法原理
SSM 是用于描述这些状态表示并根据某些输入预测其下一个状态可能是什么的模型,其架构如下图。 一般SSMs包括以下组成,映射输入序列x(t),到潜在状态表示h(t), 并导出预测输出序列y(t)。

将大多数SSM架构比如H3的基础块,与现代神经网络比如transformer中普遍存在的门控MLP相结合,组成新的Mamba块,重复这个块,与归一化和残差连接结合,便构成了Mamba架构。
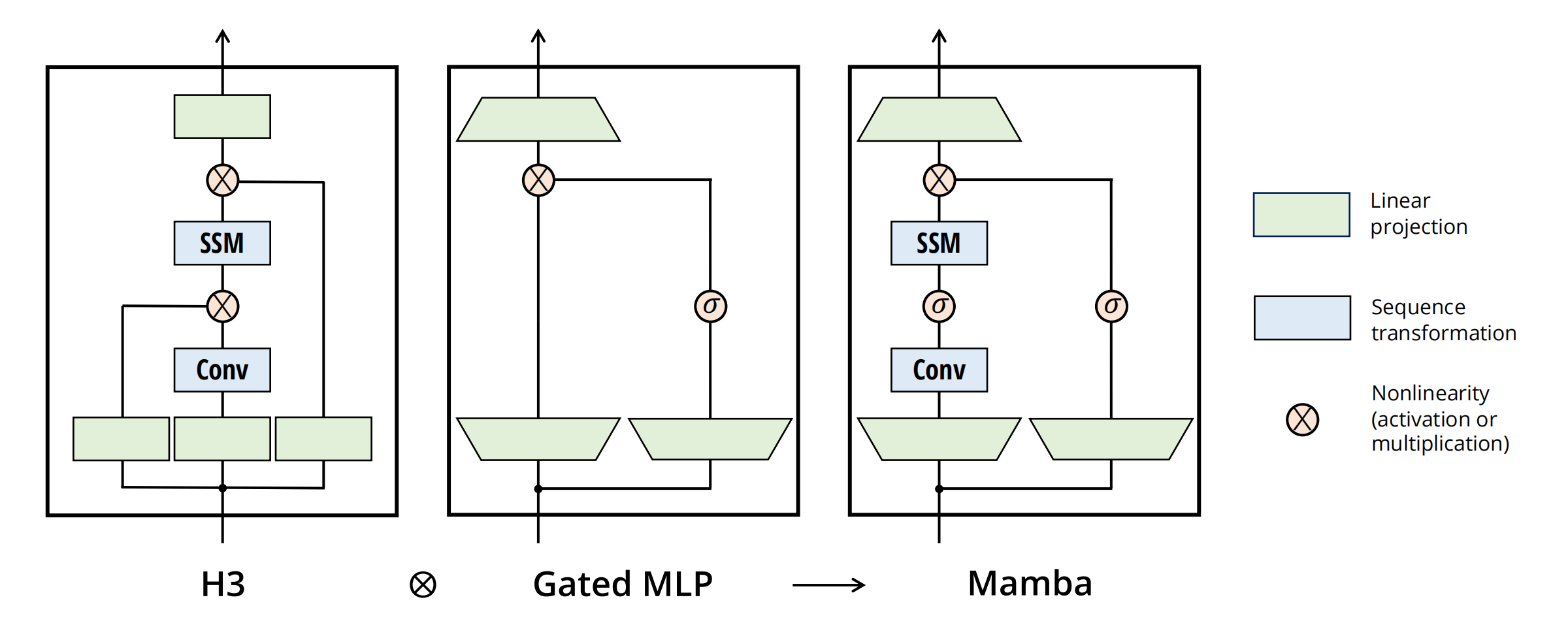
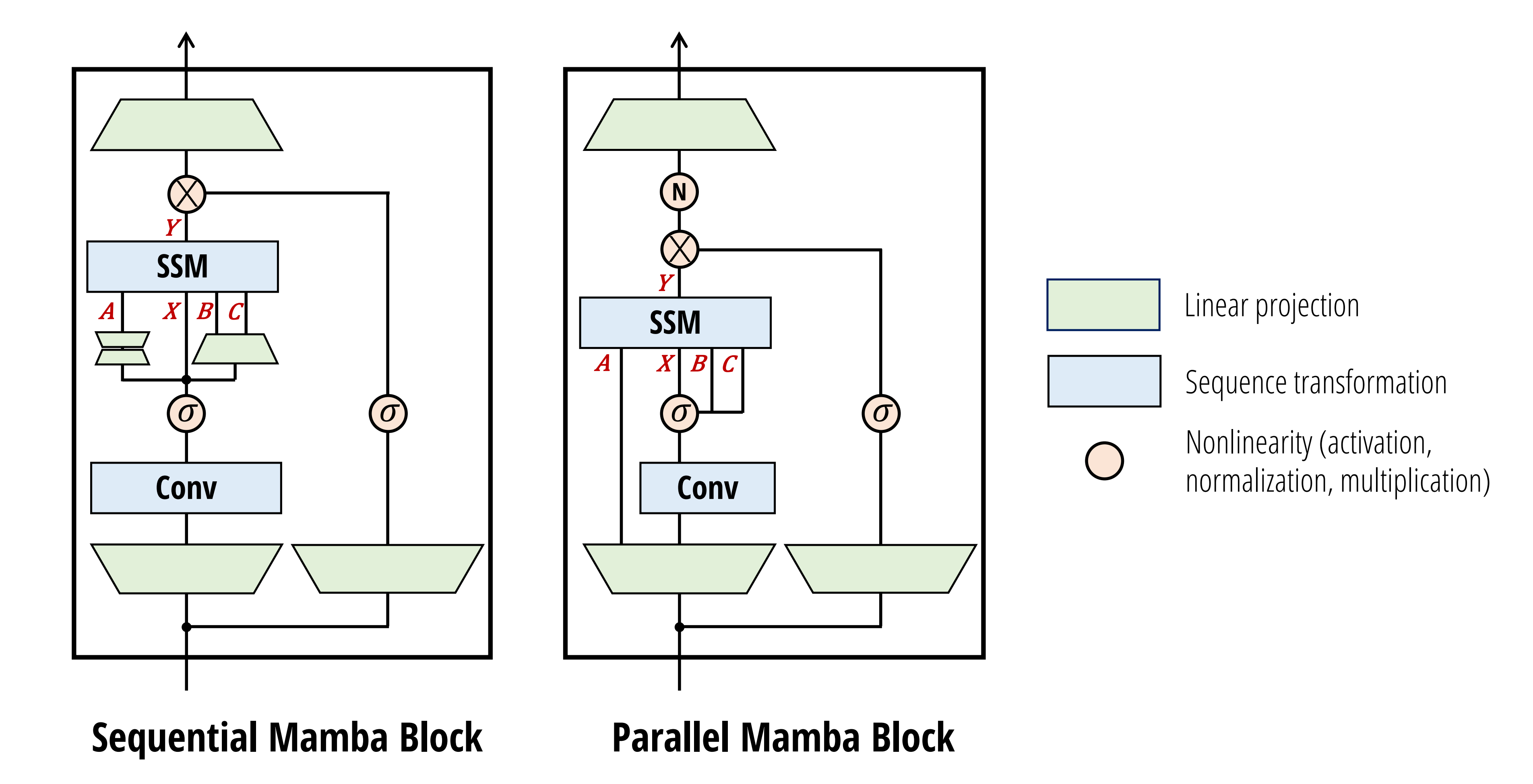
在Mamba-2中,SSD层被视为从𝐴, 𝑋, 𝐵, 𝐶 → 𝑌的映射。 因此,有必要在块的开头通过单个投影并行生成𝐴, 𝑋,𝐵, 𝐶。
## 环境配置
### Docker(方法一)
此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤,以及[光合](https://developer.hpccube.com/tool/)开发者社区深度学习库下载地址
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --shm-size=128G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name mamba2 bash # 为以上拉取的docker的镜像ID替换,本镜像为:a4dd5be0ca23
pip install wheel -i https://mirrors.aliyun.com/pypi/simple/
cd /path/your_code_data/mamba2_pytorch
pip install . --no-build-isolation --no-deps
pip install lm-eval==0.4.2 -i https://mirrors.aliyun.com/pypi/simple/
#mamba2需要安装causal-conv1d
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
pip install e .
```
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
docker build --no-cache -t mamba2:latest .
docker run -it --shm-size=128G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name mamba2 mamba2 bash
cd /path/your_code_data/mamba2_pytorch
pip install . --no-build-isolation --no-deps
pip install lm-eval==0.4.2 -i https://mirrors.aliyun.com/pypi/simple/
#mamba2需要安装causal-conv1d
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
pip install e .
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
#DTK驱动:dtk24.04
# python:python3.10
# torch: 2.1.0
# torchvision: 0.16.0
# triton
conda create -n mamba python=3.10
conda activate mamba
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它依赖环境安装如下:
```
cd /path/your_code_data/mamba2_pytorch
pip install . --no-build-isolation --no-deps
pip install lm-eval==0.4.2 -i https://mirrors.aliyun.com/pypi/simple/
#mamba2需要安装causal-conv1d
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
pip install e .
```
## 数据集
运行推理时会自动连接huggingface下载最新数据集于缓存目录
```
#数据集格式
piqa/
└── plain_text
└── 1.1.0
├── 6c611c1a9bf220943c4174e117d3b660859665baf1d43156230116185312d011
│ ├── dataset_info.json
│ ├── piqa-test.arrow
│ ├── piqa-train.arrow
│ └── piqa-validation.arrow
├── 6c611c1a9bf220943c4174e117d3b660859665baf1d43156230116185312d011_builder.lock
└── 6c611c1a9bf220943c4174e117d3b660859665baf1d43156230116185312d011.incomplete_info.lock
...
```
也可下载离线数据,放于缓存目录~/.cache/huggingface/hub/datasets/,根据自己的缓存地址存放:
数据集SCNet快速下载链接[datasets](http://113.200.138.88:18080/aidatasets/mamba2_data_test)
或者使用modelscope下载相关数据集
```
#数据集下载示例
#需要pip install modelscope安装modelscope
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('opencompass/piqa')
```
## 训练
无
## 推理
运行推理时会自动连接huggingface下载模型文件,也可使用modelscope提前下载相关模型文件到缓存目录, 使用本地修改pretrained=/path_to_model/model_name
模型权重SCNet下载链接[models](http://113.200.138.88:18080/aimodels/mamba2)
### 单机单卡
Evaluate:
#To run evaluations on Mamba-1 models
```
lm_eval --model mamba_ssm --model_args pretrained=state-spaces/mamba-130m --tasks lambada_openai,hellaswag,piqa,arc_easy,arc_challenge,winogrande,openbookqa --device cuda --batch_size 256
```
#To run evaluations on Mamba-2 models:
```
lm_eval --model mamba_ssm --model_args pretrained=state-spaces/mamba2-2.7b --tasks lambada_openai,hellaswag,piqa,arc_easy,arc_challenge,winogrande,openbookqa --device cuda --batch_size 256
lm_eval --model mamba_ssm --model_args pretrained=state-spaces/transformerpp-2.7b --tasks lambada_openai,hellaswag,piqa,arc_easy,arc_challenge,winogrande,openbookqa --device cuda --batch_size 256
lm_eval --model mamba_ssm --model_args pretrained=state-spaces/mamba2attn-2.7b --tasks lambada_openai,hellaswag,piqa,arc_easy,arc_challenge,winogrande,openbookqa --device cuda --batch_size 256
```
Inference :
To test generation latency (e.g. batch size = 1) with mamba:
```
python benchmarks/benchmark_generation_mamba_simple.py --model-name "state-spaces/mamba-2.8b" --prompt "My cat wrote all this CUDA code for a new language model and" --topp 0.9 --temperature 0.7 --repetition-penalty 1.2
```
With Mamba-2:
```
python benchmarks/benchmark_generation_mamba_simple.py --model-name "state-spaces/mamba2-2.7b" --prompt "My cat wrote all this CUDA code for a new language model and" --topp 0.9 --temperature 0.7 --repetition-penalty 1.2
```
### 多卡推理
多卡推理使用accelerate,样例如下:
```
HIP_VISIBLE_DEVICES=0,1 accelerate launch -m lm_eval --model mamba_ssm --model_args pretrained=state-spaces/mamba2-2.7b --tasks lambada_openai,hellaswag,piqa,arc_easy,arc_challenge,winogrande,openbookqa --device cuda --batch_size 256
```
## result
state-spaces/mamba-2.8b result:
state-spaces/mamba2-2.7b result:
### 精度
使用2张DCU-K100 AI卡推理
mamba_ssm (pretrained=state-spaces/mamba-130m), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: 256
| Tasks |Version|Filter|n-shot| Metric | Value | |Stderr|
|--------------|------:|------|-----:|----------|------:|---|-----:|
|winogrande | 1|none | 0|acc | 0.5217|± |0.0140|
|piqa | 1|none | 0|acc | 0.6458|± |0.0112|
| | |none | 0|acc_norm | 0.6306|± |0.0113|
|openbookqa | 1|none | 0|acc | 0.1700|± |0.0168|
| | |none | 0|acc_norm | 0.2880|± |0.0203|
|lambada_openai| 1|none | 0|perplexity|16.0456|± |0.5091|
| | |none | 0|acc | 0.4428|± |0.0069|
|hellaswag | 1|none | 0|acc | 0.3079|± |0.0046|
| | |none | 0|acc_norm | 0.3522|± |0.0048|
|arc_easy | 1|none | 0|acc | 0.4794|± |0.0103|
| | |none | 0|acc_norm | 0.4205|± |0.0101|
|arc_challenge | 1|none | 0|acc | 0.1988|± |0.0117|
| | |none | 0|acc_norm | 0.2457|± |0.0126|
mamba_ssm (pretrained=state-spaces/mamba2-2.7b)
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|--------------|------:|------|-----:|----------|-----:|---|-----:|
|winogrande | 1|none | 0|acc |0.6385|± |0.0135|
|piqa | 1|none | 0|acc |0.7628|± |0.0099|
| | |none | 0|acc_norm |0.7617|± |0.0099|
|openbookqa | 1|none | 0|acc |0.2940|± |0.0204|
| | |none | 0|acc_norm |0.3880|± |0.0218|
|lambada_openai| 1|none | 0|perplexity|4.0934|± |0.0888|
| | |none | 0|acc |0.6951|± |0.0064|
|hellaswag | 1|none | 0|acc |0.4961|± |0.0050|
| | |none | 0|acc_norm |0.6660|± |0.0047|
|arc_easy | 1|none | 0|acc |0.6957|± |0.0094|
| | |none | 0|acc_norm |0.6481|± |0.0098|
|arc_challenge | 1|none | 0|acc |0.3328|± |0.0138|
| | |none | 0|acc_norm |0.3626|± |0.0140|
mamba_ssm (pretrained=state-spaces/mamba2attn-2.7b), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: 256
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|--------------|------:|------|-----:|----------|-----:|---|-----:|
|winogrande | 1|none | 0|acc |0.6519|± |0.0134|
|piqa | 1|none | 0|acc |0.7573|± |0.0100|
| | |none | 0|acc_norm |0.7584|± |0.0100|
|openbookqa | 1|none | 0|acc |0.3040|± |0.0206|
| | |none | 0|acc_norm |0.3900|± |0.0218|
|lambada_openai| 1|none | 0|perplexity|3.8497|± |0.0810|
| | |none | 0|acc |0.7105|± |0.0063|
|hellaswag | 1|none | 0|acc |0.5029|± |0.0050|
| | |none | 0|acc_norm |0.6776|± |0.0047|
|arc_easy | 1|none | 0|acc |0.6987|± |0.0094|
| | |none | 0|acc_norm |0.6633|± |0.0097|
|arc_challenge | 1|none | 0|acc |0.3447|± |0.0139|
| | |none | 0|acc_norm |0.3797|± |0.0142|
## 应用场景
### 算法类别
`智能问答`
### 热点应用行业
`科研,制造,医疗,家居,教育`
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/mamba2_pytorch
## 参考资料
- https://github.com/state-spaces/mamba

