# magic-animate
## 论文
**MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model**
* https://arxiv.org/pdf/2311.16498.pdf
## 模型结构
如图所示,该模型的输入为`reference image`(该图像为参考图片),`DensePose sequence`(目标动作),`noisy latents`(随机初始化的噪声,长度与DensePose一致)。`Appearance Encoder`的作用是提取`reference image`的特征,`ControlNet`的作用是提取动作特征,`Temporal Attention`插入`2D-Unet`使其变为`3D-Unet`。
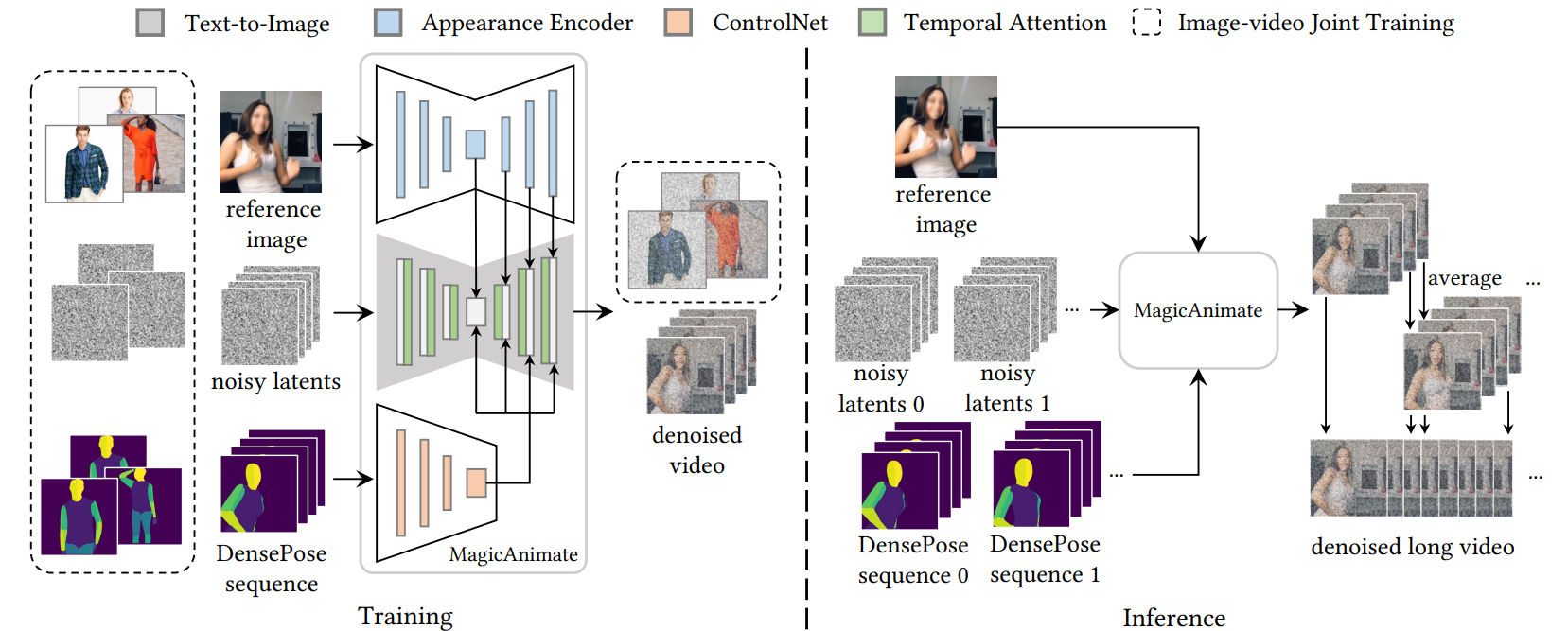
## 算法原理
该算法基于stable diffusion,在Unet中插入时序注意力层,将图像领域扩展至视频领域,可以使图像中人物按照给定动作"动起来",具体如下,
1.时序一致性:在原先的2D-Unet中插入时序注意力层使其变为3D-Unet,将图像领域的扩散模型扩展至视频领域。
2.参考图片特征提取:具有改进的身份和背景保留功能,以增强单帧保真度和时间连贯性。
3.图片-视频联合训练:与图像数据集相比,视频数据集在身份、背景和姿势方面的规模要小得多,且变化更少,限制了动画框架有效学习参考条件的能力,使用联合训练,可以缓解该问题。
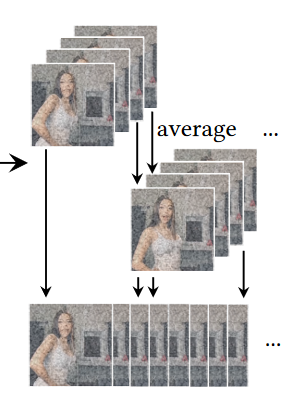
4.视频融合:将视频重叠的部分求平均
 ## 环境配置
### Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04.1-py39-latest
docker run --shm-size 10g --network=host --name=magic_animate --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -it bash
pip install -r requirements.txt
### Docker(方法二)
# 需要在对应的目录下
docker build -t : .
# 用以上拉取的docker的镜像ID替换
docker run -it --shm-size 10g --network=host --name=magic_animate --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined bash
pip install -r requirements.txt
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
https://developer.hpccube.com/tool/
DTK驱动:dtk23.04.1
python:python3.9
torch:1.13.1
torchvision:0.14.1
torchaudio:0.13.1
deepspeed:0.9.2
apex:0.1
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install -r requirements.txt
## 数据集
无
## 推理
模型下载地址:
MagicAnimate - https://huggingface.co/zcxu-eric/MagicAnimate/tree/main
sd-vae-ft-mse - https://huggingface.co/stabilityai/sd-vae-ft-mse
stabe-diffusion-v1-5 - https://huggingface.co/runwayml/stable-diffusion-v1-5
注意:如果无法访问,可以使用镜像 https://hf-mirror.com/
pretrained_models/
├── MagicAnimate
│ ├── appearance_encoder
│ │ ├── config.json
│ │ └── diffusion_pytorch_model.safetensors
│ ├── densepose_controlnet
│ │ ├── config.json
│ │ └── diffusion_pytorch_model.safetensors
│ └── temporal_attention
│ └── temporal_attention.ckpt
├── sd-vae-ft-mse
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── stable-diffusion-v1-5
├── text_encoder
│ ├── config.json
│ └── pytorch_model.bin
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── config.json
│ └── diffusion_pytorch_model.bin
├── v1-5-pruned.ckpt
└── vae
├── config.json
└── diffusion_pytorch_model.bin
### 命令行
单卡运行
bash scripts/animate.sh
多卡运行
bash scripts/animate_dist.sh
## result

### 精度
无
## 应用场景
### 算法类别
`AIGC`
### 热点应用行业
`媒体,科研,教育`
## 源码仓库及问题反馈
* https://developer.hpccube.com/codes/modelzoo/magic-animate_pytorch
## 参考资料
* https://github.com/magic-research/magic-animate
## 环境配置
### Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04.1-py39-latest
docker run --shm-size 10g --network=host --name=magic_animate --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -it bash
pip install -r requirements.txt
### Docker(方法二)
# 需要在对应的目录下
docker build -t : .
# 用以上拉取的docker的镜像ID替换
docker run -it --shm-size 10g --network=host --name=magic_animate --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined bash
pip install -r requirements.txt
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
https://developer.hpccube.com/tool/
DTK驱动:dtk23.04.1
python:python3.9
torch:1.13.1
torchvision:0.14.1
torchaudio:0.13.1
deepspeed:0.9.2
apex:0.1
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install -r requirements.txt
## 数据集
无
## 推理
模型下载地址:
MagicAnimate - https://huggingface.co/zcxu-eric/MagicAnimate/tree/main
sd-vae-ft-mse - https://huggingface.co/stabilityai/sd-vae-ft-mse
stabe-diffusion-v1-5 - https://huggingface.co/runwayml/stable-diffusion-v1-5
注意:如果无法访问,可以使用镜像 https://hf-mirror.com/
pretrained_models/
├── MagicAnimate
│ ├── appearance_encoder
│ │ ├── config.json
│ │ └── diffusion_pytorch_model.safetensors
│ ├── densepose_controlnet
│ │ ├── config.json
│ │ └── diffusion_pytorch_model.safetensors
│ └── temporal_attention
│ └── temporal_attention.ckpt
├── sd-vae-ft-mse
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── stable-diffusion-v1-5
├── text_encoder
│ ├── config.json
│ └── pytorch_model.bin
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── config.json
│ └── diffusion_pytorch_model.bin
├── v1-5-pruned.ckpt
└── vae
├── config.json
└── diffusion_pytorch_model.bin
### 命令行
单卡运行
bash scripts/animate.sh
多卡运行
bash scripts/animate_dist.sh
## result

### 精度
无
## 应用场景
### 算法类别
`AIGC`
### 热点应用行业
`媒体,科研,教育`
## 源码仓库及问题反馈
* https://developer.hpccube.com/codes/modelzoo/magic-animate_pytorch
## 参考资料
* https://github.com/magic-research/magic-animate