# LongCat-Next_pytorch
## 论文
[LongCat-Next Technical Report](https://github.com/meituan-longcat/LongCat-Next/blob/main/tech_report.pdf)
## 模型简介
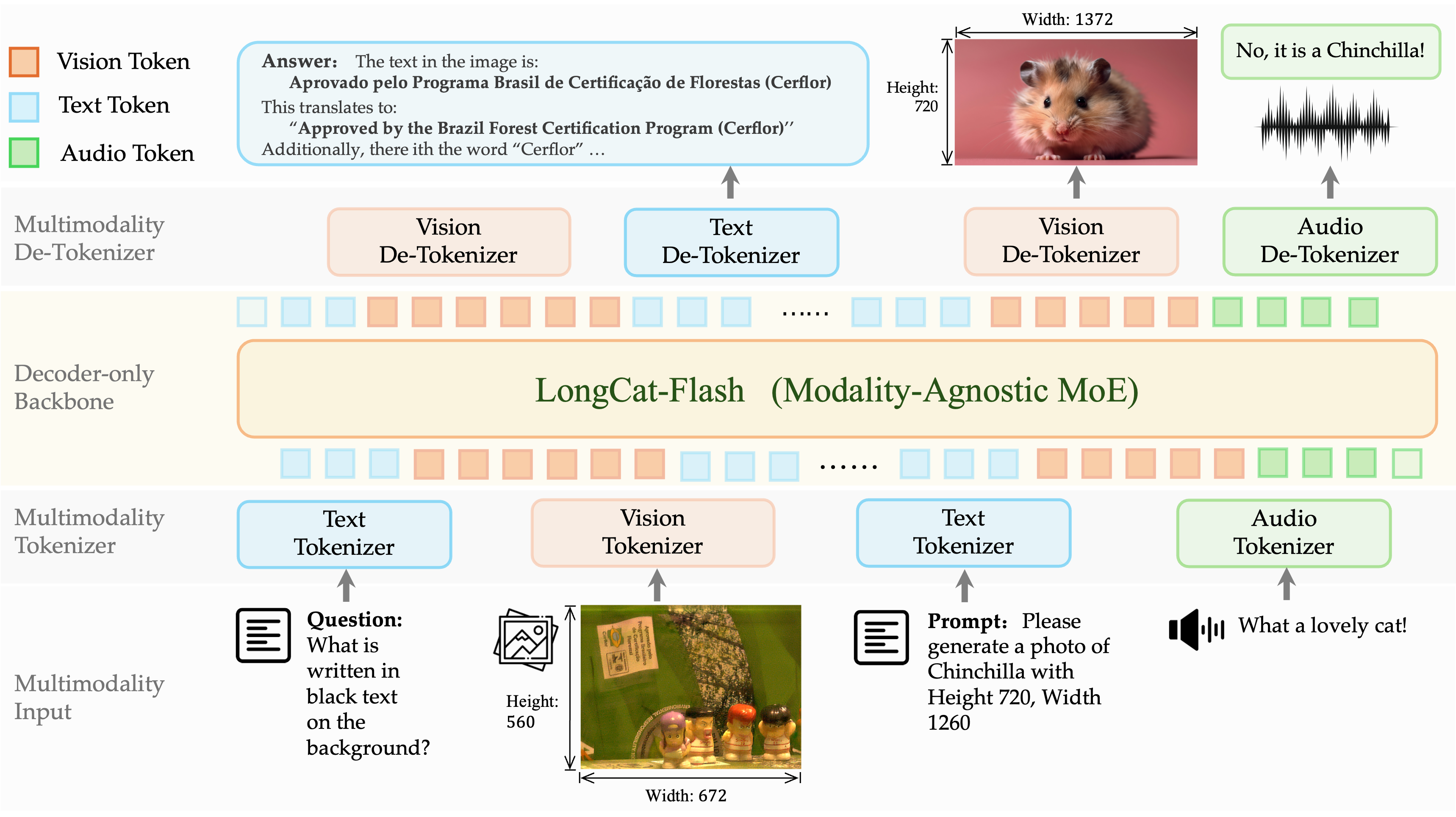
G本工作主要通过一种强调简洁性的设计理念来解决原生多模态的根本障碍,即将视觉和音频视为语言的内在延伸。作为实现这一目标的重要一步,我们提出了 LongCat-Next——一个离散原生多模态模型,它在离散框架内实现了工业级性能,同时在众多专业领域保持高度竞争力。该模型基于 LongCat-Flash-Lite MoE 主干网络(A3B)作为_多任务_学习器,将语言、视觉和音频统一于单一的离散框架之中。本文的主要贡献如下:
- 🌟 离散原生自回归范式(DiNA)。
我们提出了 DiNA,这是一种统一的范式,将语言中的下一个 token 预测扩展至原生多模态领域,将多种模态内化到共享的 token 空间中。该范式通过构建模态感知的分词器-反分词器对,并利用大语言模型成熟的训练基础设施,简化了多模态建模过程。
- 🌟 离散视觉表示的语义完整性。
我们通过将语义对齐编码器(Semantic-and-Aligned Encoders, SAE)与残差向量量化(Residual Vector Quantization, RVQ)相结合,改进了离散视觉建模。这种集成创建了分层的离散 token,既保留了语义抽象,又保留了细粒度的视觉细节,超越了传统表示方法的局限性。
- 🌟 离散原生分辨率视觉 Transformer(dNaViT)。
类比于语言 tokenizer,我们提出了 dNaViT,作为一种高度灵活、统一的视觉离散接口,它将语义特征提取为“视觉词”,构建了一个支持动态分词与反分词的分层表示空间。dNaViT 能无缝集成到大语言模型中,在不造成性能下降的前提下确保高性能。
- 🌟 在统一模型中实现卓越的看、创、说能力。
在 DiNA 框架内,视觉理解与生成被优雅地重新表述为同一预测过程的两种表现形式,且不牺牲性能。该表述弥合了长期以来的架构鸿沟,同时在传统上相互竞争的目标之间引入极小的干扰,并保留了核心的语言能力。值得注意的是,LongCat-Next 在理解任务上达到了与专用理解模型相当的性能,即使在 28 倍压缩率下仍保持强大的生成质量(尤其在文本渲染方面),同时在高级语音理解、低延迟语音对话和可定制语音克隆方面也表现出色。
## 环境依赖
| 软件 | 版本 |
| :------: | :------: |
| DTK | dtk25.04 |
| python |3.10 |
| transformers | 4.57.6 |
| torch | 2.5.1+das.opt1.dtk25042 |
| torchaudio | 2.5.1+das.opt1.dtk25042 |
推荐使用镜像: image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.2-py3.10
挂载地址-v 根据实际模型情况修改
```bash
docker run -it \
--shm-size 200g \
--network=host \
--name LongCat-Next \
--privileged \
--device=/dev/kfd \
--device=/dev/dri \
--device=/dev/mkfd \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
-u root \
-v /opt/hyhal/:/opt/hyhal/:ro \
-v /path/your_code_data/:/path/your_code_data/ \
image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.2-py3.10 bash
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装
需要单独安装:
```
pip install -r requirements.txt
# 激活torchaudio
source fastpt -E
```
## 数据集
暂无
## 训练
暂无
## 推理
### pytorch
#### 单机推理
推理脚本参考
```
HIP_VISIBLE_DEVICES=0,1,2,3 python longcat-next_inference.py
```
## 效果展示
输入
|
输出
|

|

|
### 精度
DCU与GPU精度一致,推理框架:vllm。
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 | 下载地址 |
|:------:|:----:|:----------:|:------:|:---------------------:|
| LongCat-Next | 68.5B | BW1000 | 4 | [Model Scope](https://www.modelscope.cn/models/meituan-longcat/LongCat-Next) |
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/longcat-next_pytorch
## 参考资料
- https://www.modelscope.cn/models/meituan-longcat/LongCat-Next
- https://github.com/meituan-longcat/LongCat-Next