# LLM-Compiler
LLM Compiler: Specializing Code Llama for compiler optimization
## 论文
[Meta Large Language Model Compiler: Foundation Models of Compiler Optimization](https://ai.meta.com/research/publications/meta-large-language-model-compiler-foundation-models-of-compiler-optimization/)
## 模型结构
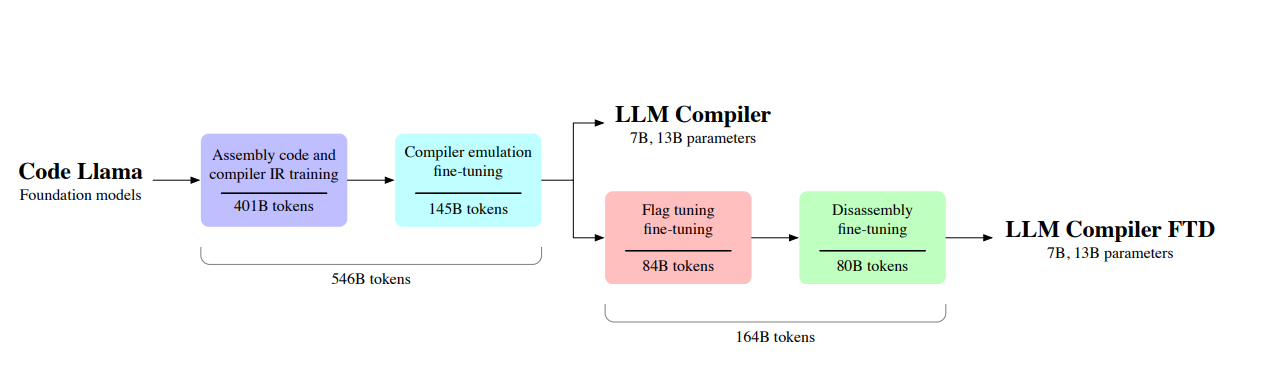
LLM编译器模型是通过在两个阶段对5460亿个编译器中心数据token进行训练,从Code Llama专业化的。在第一阶段,模型主要对未标记的编译器IR和汇编代码进行训练。在下一阶段,模型经过指令微调,以预测优化的输出和效果。然后,LLM编译器FTD模型在下游标志调整和反汇编任务数据集的1640亿个token上进一步微调,总共进行了7100亿个训练token。
## 算法原理
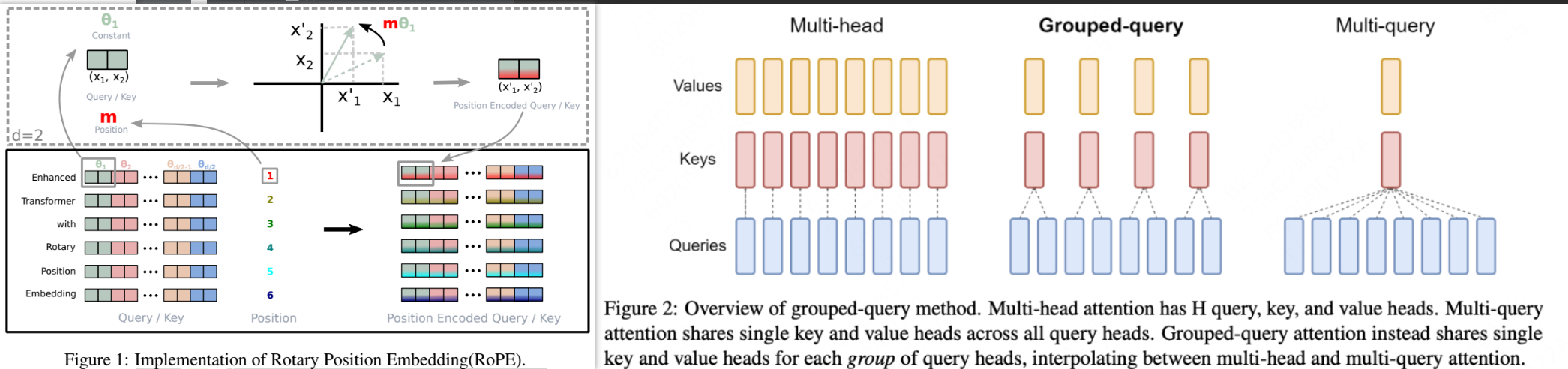
使用GQA模块能够带来更好的速度,使用GQA的head数量不同则会带来速度和性能平衡转换。
使用了RoPE位置旋转编码来替代Embedding编码,使得模型获得更好的外推性。
## 环境配置
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/llm-compiler_pytorch
pip install -r requirements.txt
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com
```
### Dockerfile(方法二)
```bash
cd docker
docker build --no-cache -t llm-compiler:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/llm-compiler_pytorch
pip install -r requirements.txt
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动: dtk24.04
python: python3.10
torch: 2.1.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库安装方式如下:
```bash
pip install -r requirements.txt
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com
```
## 数据集
暂无
## 训练
暂无
## 推理
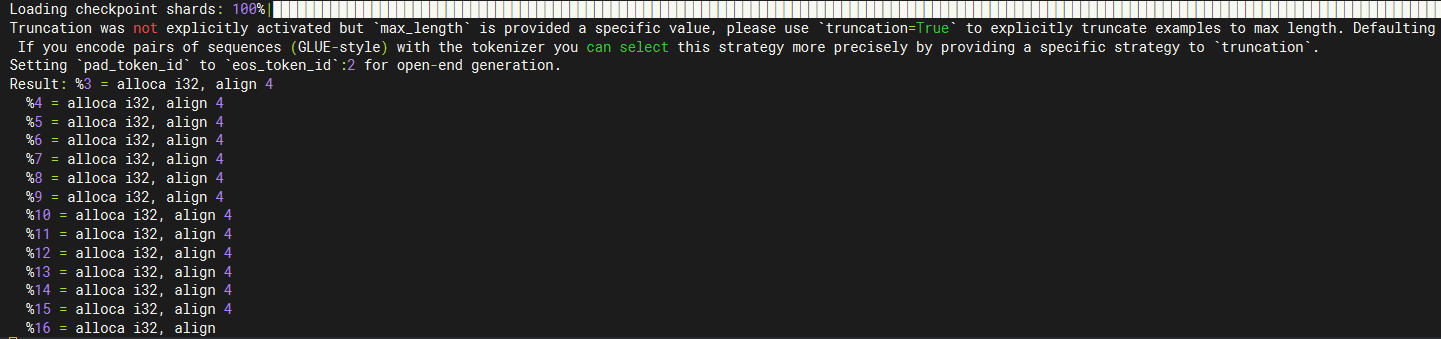
基于Huggingface's Transformers进行推理.
模型下载后 默认需存放至weights文件夹中
也可自行更改 inference.py文件中的 model_name 参数
```python
HIP_VISIBLE_DEVICES=0 python inference.py
```
## Result
prompt:%3 = alloca i32, align 4.
### 精度
暂无
## 应用场景
### 算法类别
代码生成
### 热点应用行业
制造,能源,教育
## 预训练权重
[llm-compiler-7b](https://huggingface.co/facebook/llm-compiler-7b)
模型目录结构如下:
```bash
└── llm-compiler-7b
├── config.json
├── generation_config.json
├── LICENSE.pdf
├── llm_compiler_demo.py
├── pytorch_model-00001-of-00003.bin
├── pytorch_model-00002-of-00003.bin
├── pytorch_model-00003-of-00003.bin
├── pytorch_model.bin.index.json
├── readme
│ ├── autotune.png
│ ├── disassemble.png
│ ├── emulate.png
│ └── training.png
├── README.md
├── special_tokens_map.json
├── tokenizer_config.json
├── tokenizer.json
└── tokenizer.model
```
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/llm-compiler_pytorch
## 参考资料
- https://huggingface.co/facebook/llm-compiler-7b/blob/main/llm_compiler_demo.py
- https://huggingface.co/facebook/llm-compiler-7b