
llava-next
Showing
predict.py
0 → 100644
pyproject.toml
0 → 100644
readme_imgs/alg.png
0 → 100644
{kind=link}
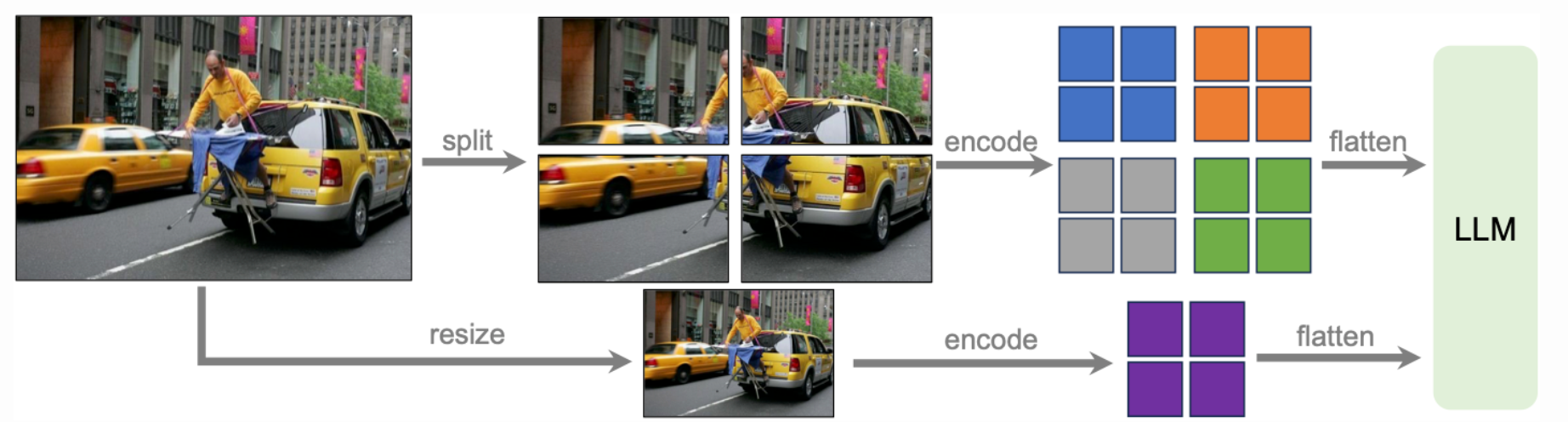
646 KB
readme_imgs/arch.png
0 → 100644
{kind=link}
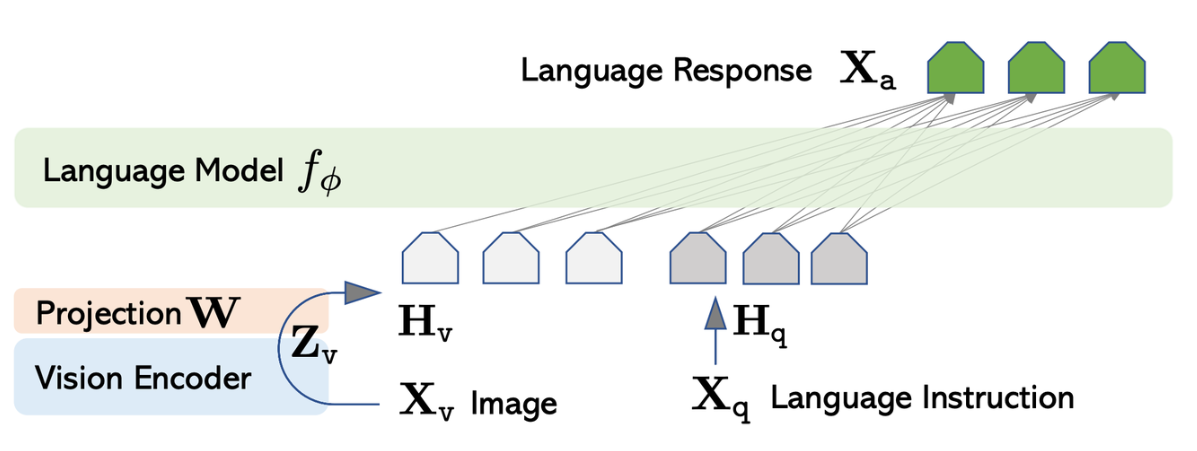
151 KB
readme_imgs/result.png
0 → 100644
{kind=link}

15.2 KB
requirements.txt
0 → 100644
| Babel==2.14.0 | ||
| DataProperty==1.0.1 | ||
| Deprecated==1.2.14 | ||
| GitPython==3.1.43 | ||
| Jinja2==3.1.3 | ||
| Levenshtein==0.25.1 | ||
| MarkupSafe==2.1.5 | ||
| PyJWT==2.8.0 | ||
| PyYAML==6.0.1 | ||
| Pygments==2.17.2 | ||
| QtPy==2.4.1 | ||
| Send2Trash==1.8.3 | ||
| absl-py==2.1.0 | ||
| accelerate==0.29.3 | ||
| aiofiles==22.1.0 | ||
| aiohttp==3.9.5 | ||
| aiosignal==1.3.1 | ||
| aiosqlite==0.20.0 | ||
| altair==5.3.0 | ||
| anyio==4.3.0 | ||
| appdirs==1.4.4 | ||
| argon2-cffi-bindings==21.2.0 | ||
| argon2-cffi==23.1.0 | ||
| arrow==1.3.0 | ||
| asttokens==2.4.1 | ||
| async-timeout==4.0.3 | ||
| attrs==23.1.0 | ||
| beautifulsoup4==4.12.3 | ||
| bidict==0.23.1 | ||
| # bitsandbytes==0.41.0 | ||
| black==24.1.0 | ||
| bleach==6.1.0 | ||
| byted-remote-ikernel==0.4.8 | ||
| byted-torch-monitor==0.0.1 | ||
| byted-wandb==0.13.72 | ||
| bytedance-context==0.7.1 | ||
| bytedance-metrics==0.5.1 | ||
| bytedance.modelhub==0.0.64 | ||
| bytedance.servicediscovery==0.1.2 | ||
| bytedbackgrounds==0.0.6 | ||
| byteddatabus==1.0.6 | ||
| byteddps==0.1.2 | ||
| bytedenv==0.6.2 | ||
| bytedlogger==0.15.1 | ||
| bytedmemfd==0.2 | ||
| bytedmetrics==0.10.2 | ||
| bytedpymongo==2.0.5 | ||
| bytedrh2==1.18.7a2 | ||
| bytedservicediscovery==0.17.4 | ||
| bytedtcc==1.4.2 | ||
| bytedtos==1.1.16 | ||
| bytedtrace==0.3.0 | ||
| bytedztijwthelper==0.0.22 | ||
| bytedztispiffe==0.0.11 | ||
| certifi==2024.2.2 | ||
| cffi==1.16.0 | ||
| cfgv==3.4.0 | ||
| chardet==5.2.0 | ||
| charset-normalizer==3.3.2 | ||
| click==8.1.7 | ||
| colorama==0.4.6 | ||
| comm==0.2.2 | ||
| contourpy==1.2.1 | ||
| crcmod==1.7 | ||
| cryptography==38.0.4 | ||
| cycler==0.12.1 | ||
| datasets==2.16.1 | ||
| debugpy==1.8.1 | ||
| decorator==5.1.1 | ||
| decord==0.6.0 | ||
| deepspeed==0.12.2 | ||
| defusedxml==0.7.1 | ||
| dill==0.3.7 | ||
| distlib==0.3.8 | ||
| distro==1.9.0 | ||
| dnspython==2.6.1 | ||
| docker-pycreds==0.4.0 | ||
| docstring_parser==0.16 | ||
| einops-exts==0.0.4 | ||
| einops==0.6.1 | ||
| entrypoints==0.4 | ||
| et-xmlfile==1.1.0 | ||
| eval_type_backport==0.2.0 | ||
| evaluate==0.4.1 | ||
| exceptiongroup==1.2.1 | ||
| executing==2.0.1 | ||
| fastapi==0.110.2 | ||
| fastjsonschema==2.19.1 | ||
| ffmpy==0.3.2 | ||
| filelock==3.13.4 | ||
| # flash-attn==2.5.7 | ||
| fonttools==4.51.0 | ||
| fqdn==1.5.1 | ||
| frozenlist==1.4.1 | ||
| fsspec==2023.10.0 | ||
| ftfy==6.2.0 | ||
| gitdb==4.0.11 | ||
| gradio==3.35.2 | ||
| gradio_client==0.2.9 | ||
| grpcio==1.62.2 | ||
| h11==0.14.0 | ||
| hf_transfer==0.1.6 | ||
| hjson==3.1.0 | ||
| httpcore==0.17.3 | ||
| httpx==0.24.0 | ||
| huggingface-hub==0.22.2 | ||
| identify==2.5.36 | ||
| idna==3.7 | ||
| importlib_metadata==7.1.0 | ||
| importlib_resources==6.4.0 | ||
| iniconfig==2.0.0 | ||
| ipaddress==1.0.23 | ||
| ipykernel==6.29.4 | ||
| ipython-genutils==0.2.0 | ||
| ipython==8.18.1 | ||
| ipywidgets==8.1.2 | ||
| isoduration==20.11.0 | ||
| jedi==0.19.1 | ||
| joblib==1.4.0 | ||
| json5==0.9.25 | ||
| jsonlines==4.0.0 | ||
| jsonpointer==2.4 | ||
| jsonschema-specifications==2023.12.1 | ||
| jsonschema==4.21.1 | ||
| jupyter-client==7.0.0 | ||
| jupyter-console==6.6.3 | ||
| jupyter-events==0.10.0 | ||
| jupyter-ydoc==0.2.5 | ||
| jupyter==1.0.0 | ||
| jupyter_core==5.7.2 | ||
| jupyter_server==2.14.0 | ||
| jupyter_server_fileid==0.9.2 | ||
| jupyter_server_terminals==0.5.3 | ||
| jupyter_server_ydoc==0.8.0 | ||
| jupyterlab==3.6.4 | ||
| jupyterlab_pygments==0.3.0 | ||
| jupyterlab_server==2.27.1 | ||
| jupyterlab_widgets==3.0.10 | ||
| kiwisolver==1.4.5 | ||
| linkify-it-py==2.0.3 | ||
| llava==1.7.0.dev0 | ||
| llava==1.7.0.dev0 | ||
| lmms_eval==0.1.1 | ||
| lxml==5.2.1 | ||
| markdown-it-py==2.2.0 | ||
| markdown2==2.4.13 | ||
| matplotlib-inline==0.1.7 | ||
| matplotlib==3.8.4 | ||
| mbstrdecoder==1.1.3 | ||
| mdit-py-plugins==0.3.3 | ||
| mdurl==0.1.2 | ||
| mistune==3.0.2 | ||
| mpmath==1.3.0 | ||
| msgpack==1.0.8 | ||
| multidict==6.0.5 | ||
| multiprocess==0.70.15 | ||
| mypy-extensions==1.0.0 | ||
| nbclassic==1.0.0 | ||
| nbclient==0.10.0 | ||
| nbconvert==7.16.3 | ||
| nbformat==5.10.4 | ||
| nest-asyncio==1.6.0 | ||
| networkx==3.2.1 | ||
| ninja==1.11.1.1 | ||
| nltk==3.8.1 | ||
| nodeenv==1.8.0 | ||
| notebook==6.5.6 | ||
| notebook_shim==0.2.4 | ||
| numexpr==2.10.0 | ||
| numpy==1.26.4 | ||
| # nvidia-cublas-cu12==12.1.3.1 | ||
| # nvidia-cuda-cupti-cu12==12.1.105 | ||
| # nvidia-cuda-nvrtc-cu12==12.1.105 | ||
| # nvidia-cuda-runtime-cu12==12.1.105 | ||
| # nvidia-cudnn-cu12==8.9.2.26 | ||
| # nvidia-cufft-cu12==11.0.2.54 | ||
| # nvidia-curand-cu12==10.3.2.106 | ||
| # nvidia-cusolver-cu12==11.4.5.107 | ||
| # nvidia-cusparse-cu12==12.1.0.106 | ||
| # nvidia-nccl-cu12==2.18.1 | ||
| # nvidia-nvjitlink-cu12==12.4.127 | ||
| # nvidia-nvtx-cu12==12.1.105 | ||
| open-clip-torch==2.24.0 | ||
| openai==1.23.6 | ||
| opencv-python-headless==4.9.0.80 | ||
| openpyxl==3.1.2 | ||
| orjson==3.10.1 | ||
| overrides==7.7.0 | ||
| packaging==24.0 | ||
| pandas==2.2.2 | ||
| pandocfilters==1.5.1 | ||
| parso==0.8.4 | ||
| pathlib2==2.3.7.post1 | ||
| pathspec==0.12.1 | ||
| pathtools==0.1.2 | ||
| pathvalidate==3.2.0 | ||
| peft==0.4.0 | ||
| pexpect==4.8.0 | ||
| pillow==10.3.0 | ||
| pip==23.3.1 | ||
| pip==24.0 | ||
| platformdirs==4.2.1 | ||
| pluggy==1.5.0 | ||
| ply==3.11 | ||
| portalocker==2.8.2 | ||
| pre-commit==3.7.0 | ||
| prometheus_client==0.20.0 | ||
| promise==2.3 | ||
| prompt-toolkit==3.0.43 | ||
| protobuf==3.20.3 | ||
| psutil==5.9.8 | ||
| ptyprocess==0.7.0 | ||
| pure-eval==0.2.2 | ||
| py-cpuinfo==9.0.0 | ||
| py-spy==0.3.14 | ||
| py==1.11.0 | ||
| pyOpenSSL==22.1.0 | ||
| pyarrow-hotfix==0.6 | ||
| pyarrow==16.0.0 | ||
| pybind11==2.12.0 | ||
| pycocoevalcap==1.2 | ||
| pycocotools==2.0.7 | ||
| pycparser==2.22 | ||
| pycryptodomex==3.20.0 | ||
| pydantic==1.10.8 | ||
| pydub==0.25.1 | ||
| pynvml==11.5.0 | ||
| pyparsing==3.1.2 | ||
| pytablewriter==1.2.0 | ||
| pytest==6.2.5 | ||
| python-consul==1.1.0 | ||
| python-dateutil==2.9.0.post0 | ||
| python-engineio==4.9.0 | ||
| python-etcd==0.4.5 | ||
| python-json-logger==2.0.7 | ||
| python-multipart==0.0.9 | ||
| python-socketio==5.11.2 | ||
| pytz==2024.1 | ||
| pyzmq==24.0.1 | ||
| qtconsole==5.5.1 | ||
| rapidfuzz==3.8.1 | ||
| referencing==0.35.0 | ||
| regex==2024.4.16 | ||
| requests==2.31.0 | ||
| responses==0.18.0 | ||
| rfc3339-validator==0.1.4 | ||
| rfc3986-validator==0.1.1 | ||
| rich==13.7.1 | ||
| rouge-score==0.1.2 | ||
| rpds-py==0.18.0 | ||
| sacrebleu==2.4.2 | ||
| safetensors==0.4.3 | ||
| schedule==1.2.1 | ||
| scikit-learn==1.2.2 | ||
| scipy==1.13.0 | ||
| semantic-version==2.10.0 | ||
| sentencepiece==0.1.99 | ||
| sentry-sdk==2.0.0 | ||
| setproctitle==1.3.3 | ||
| setuptools==68.2.2 | ||
| shortuuid==1.0.13 | ||
| shtab==1.7.1 | ||
| simple-websocket==1.0.0 | ||
| six==1.16.0 | ||
| smmap==5.0.1 | ||
| sniffio==1.3.1 | ||
| soupsieve==2.5 | ||
| sqlitedict==2.1.0 | ||
| stack-data==0.6.3 | ||
| starlette==0.37.2 | ||
| svgwrite==1.4.3 | ||
| sympy==1.12 | ||
| tabledata==1.3.3 | ||
| tabulate==0.9.0 | ||
| tcolorpy==0.1.4 | ||
| tenacity==8.2.3 | ||
| terminado==0.18.1 | ||
| threadpoolctl==3.4.0 | ||
| thriftpy2==0.4.20 | ||
| tiktoken==0.6.0 | ||
| timm==0.9.16 | ||
| tinycss2==1.3.0 | ||
| tokenizers==0.15.2 | ||
| toml==0.10.2 | ||
| tomli==2.0.1 | ||
| toolz==0.12.1 | ||
| torch==2.1.2 | ||
| torchvision==0.16.2 | ||
| tornado==6.4 | ||
| tox==3.28.0 | ||
| tqdm-multiprocess==0.0.11 | ||
| tqdm==4.66.2 | ||
| traitlets==5.14.3 | ||
| transformers-stream-generator==0.0.5 | ||
| transformers==4.40.0.dev0 | ||
| triton==2.1.0 | ||
| typepy==1.3.2 | ||
| types-python-dateutil==2.9.0.20240316 | ||
| typing_extensions==4.11.0 | ||
| tyro==0.8.3 | ||
| tzdata==2024.1 | ||
| uc-micro-py==1.0.3 | ||
| uri-template==1.3.0 | ||
| urllib3==2.2.1 | ||
| uvicorn==0.29.0 | ||
| virtualenv==20.26.0 | ||
| wandb==0.16.5 | ||
| watchdog==4.0.0 | ||
| wavedrom==2.0.3.post3 | ||
| wcwidth==0.2.13 | ||
| webcolors==1.13 | ||
| webencodings==0.5.1 | ||
| websocket-client==1.8.0 | ||
| websockets==12.0 | ||
| wheel==0.41.2 | ||
| widgetsnbextension==4.0.10 | ||
| wrapt==1.16.0 | ||
| wsproto==1.2.0 | ||
| xxhash==3.4.1 | ||
| y-py==0.6.2 | ||
| yarl==1.9.4 | ||
| ypy-websocket==0.8.4 | ||
| zipp==3.18.1 | ||
| zstandard==0.22.0 |
scripts/archived/finetune.sh
0 → 100644