## LLaMA & LLaMA2
## 论文
`LLaMA: Open and Efficient Foundation Language Models`
- [https://arxiv.org/abs/2302.13971](https://arxiv.org/abs/2302.13971)
`Llama 2: Open Foundation and Fine-Tuned Chat Models`
- [https://arxiv.org/abs/2307.09288](https://arxiv.org/abs/2307.09288)
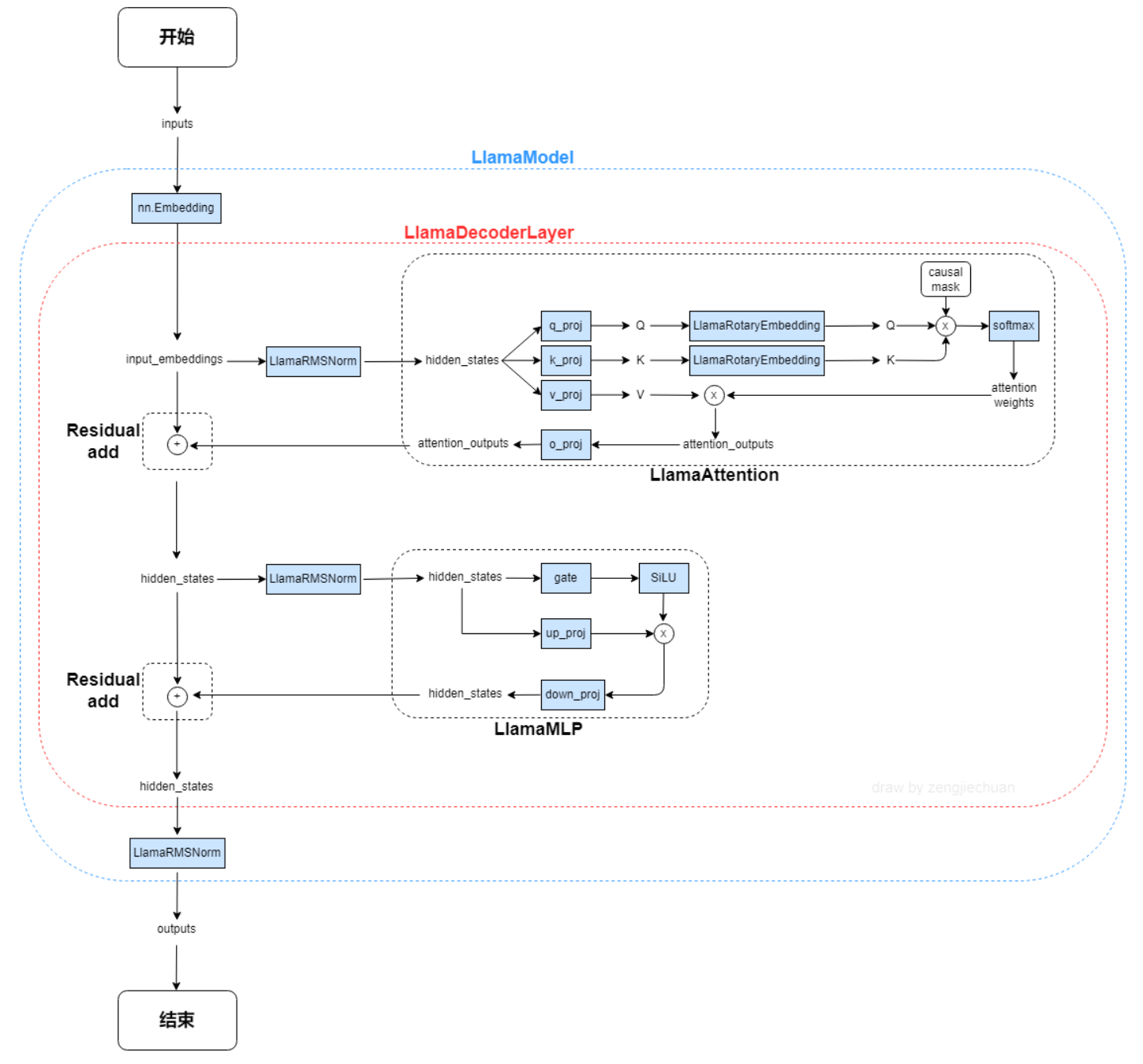
## 模型结构
**注意**:本仓库在llama2部分仅支持7b和13b模型。
LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在数万亿的tokens上训练出的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。特别是,llama 13B在大多数基准测试中优于GPT-3 (175B), LLaMA 65B与最好的模型Chinchilla-70B和PaLM-540B具有竞争力。LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。
LLaMA模型具体参数:
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 训练数据(tokens) | 位置编码 | 最大长 |
| -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
| LLaMA-7B | 4,096 | 32 | 32 | 32,000 |1T | RoPE | 2048 |
| LLaMA-13B | 5,120 | 40 | 40 | 32,000 |1T | RoPE | 2048 |
LLaMA 2是LLaMA的新一代版本,具有商业友好的许可证。 LLaMA 2 有 3 种不同的尺寸:7B、13B 和 70B。Llama 2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。Llama 2采用了 Llama 1 的大部分预训练设置和模型架构,使用标准Transformer 架构,使用 RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
## 算法原理
以下是与原始架构的主要区别:
**预归一化**。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。
**SwiGLU 激活函数**。使用 SwiGLU 激活函数替换 ReLU 非线性以提高性能。使用 2 /3 4d 的维度而不是 PaLM 中的 4d。
**旋转嵌入**。移除了绝对位置嵌入,而是添加了旋转位置嵌入 (RoPE),在网络的每一层。
## 环境配置
### Docker(方式一)
推荐使用docker方式运行,提供拉取的docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
```
进入docker,安装docker中没有的依赖:
```
docker run -dit --network=host --name=llama-tencentpretrain --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
docker exec -it llama-tencentpretrain /bin/bash
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Dockerfile(方式二)
```
docker build -t llama:latest .
docker run -dit --network=host --name=llama-tencentpretrain --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 llama:latest
docker exec -it llama-tencentpretrain /bin/bash
```
### Conda(方式三)
1. 创建conda虚拟环境:
```
conda create -n chatglm python=3.7
```
2. 关于本项目DCU显卡所需的工具包、深度学习库等均可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
- [DTK 23.04](https://cancon.hpccube.com:65024/1/main/DTK-23.04.1)
- [Pytorch 1.13.1](https://cancon.hpccube.com:65024/4/main/pytorch/dtk23.04)
- [Deepspeed 0.9.2](https://cancon.hpccube.com:65024/4/main/deepspeed/dtk23.04)
Tips:以上dtk驱动、python、deepspeed等工具版本需要严格一一对应。
3. 其它依赖库参照requirements.txt安装:
```
pip install -r requirements.txt
```
## 数据集
我们在[data](./data)目录下集成了中文公开指令数据集[alpaca_gpt4_data_zh.json](https://huggingface.co/datasets/shibing624/alpaca-zh),供用户快速验证:
```
$ tree ./data/
── alpaca_gpt4_data_zh.json
── dataset.pt
```
### 模型权重下载
1. 方式一:下载huggingface格式模型。以 7B 模型为例,首先下载预训练[LLaMA权重](https://huggingface.co/decapoda-research/llama-7b-hf),转换到TencentPretrain格式:
```commandline
python3 scripts/convert_llama_from_huggingface_to_tencentpretrain.py --input_model_path $LLaMA_HF_PATH \
--output_model_path models/llama-7b.bin --type 7B
```
2. 方式二:也可以直接下载[TencentPretrain对应格式模型](https://huggingface.co/Linly-AI/)进行微调训练,不需要转换格式。
## 训练
### 全参数增量预训练
#### 数据预处理
1. 构建预训练数据集
txt预训练语料:多个txt需要合并到一个 .txt 文件并按行随机打乱,语料格式如下:
```commandline
doc1
doc2
doc3
```
jsonl 预训练语料:为了支持代码等包含换行符的数据,预训练数据也可以整理成jsonl格式,格式如下:
```commandline
{"text": "doc1"}
{"text": "doc2"}
{"text": "doc3"}
```
2. 按如下方式进行预处理
```commandline
python3 preprocess.py --corpus_path $CORPUS_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
--dataset_path $OUTPUT_DATASET_PATH --data_processor lm --seq_length 1024
```
可选参数: --json_format_corpus:使用jsonl格式数据;
--full_sentences:对长度不足的样本使用其他样本进行填充(没有 pad token);
#### 训练
1. 单机
```commandline
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
--pretrained_model_path models/llama-7b.bin \
--dataset_path $OUTPUT_DATASET_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
--config_path models/llama/7b_config.json \
--output_model_path models/llama_zh_7b \
--world_size 8 --data_processor lm --deepspeed_checkpoint_activations \
--total_steps 300000 --save_checkpoint_steps 5000 --batch_size 24
```
2. 多机
```commandline
cd multi_node
```
进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改run-13b-pretrain.sh中--mca btl_tcp_if_include enp97s0f1,enp97s0f1改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定,微调命令:
```commandline
bash run-13b-pretrain.sh
```
### 全参数指令微调
#### 数据预处理
1. 构建指令数据集:指令数据为 json 格式,包含instruction、input、output三个字段(可以为空),每行一条样本。
示例:
```commandline
{"instruction": "在以下文本中提取所有的日期。", "input": "6月21日是夏至,这是一年中白天最长的一天。", "output": "6月21日"}
{"instruction": "", "input": "请生成一个新闻标题,描述一场正在发生的大型自然灾害。\\n\n", "output": "\"强烈飓风肆虐,数百万人疏散!\""}
```
2. 按如下方式进行预处理
```commandline
python3 preprocess.py --corpus_path $INSTRUCTION_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
--dataset_path $OUTPUT_DATASET_PATH --data_processor alpaca --seq_length 1024
```
#### 训练
1. 单机
```commandline
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
--pretrained_model_path models/llama_zh_7b.bin \
--dataset_path $OUTPUT_DATASET_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
--config_path models/llama/7b_config.json \
--output_model_path models/chatflow_7b \
--world_size 8 --data_processor alpaca --prefix_lm_loss --deepspeed_checkpoint_activations \
--total_steps 20000 --save_checkpoint_steps 2000 --batch_size 24
```
2. 多机
```commandline
cd multi_node
```
进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改run-13b.sh中--mca btl_tcp_if_include enp97s0f1,enp97s0f1改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定,微调命令:
```commandline
bash run-13b.sh
```
### 模型分块
训练初始化时,每张卡会加载一个模型的拷贝,因此内存需求为模型大小*GPU数量。内存不足时可以通过以下方式将模型分块,然后使用分块加载。
```commandline
python3 scripts/convert_model_into_blocks.py \
--input_model_path path/to/chinese_llama_13b.bin \
--output_model_path path/to/chinese_llama_13b \
--block_size 10
```
其中,--input_model_path 输入模型路径; --output_model_path 输出模型目录; --block_size 分块大小;在训练加载模型时,将 pretrained_model_path 改为以上输出的目录即可。
## 推理
TencentPretrain格式模型推理请参考[llama_inference_pytorch](https://developer.hpccube.com/codes/modelzoo/llama_inference_pytorch)
## Result
-input
```
请问“手臂”的英文是什么
```
-output
```
手臂的英文是“arm”。
```
## 精度
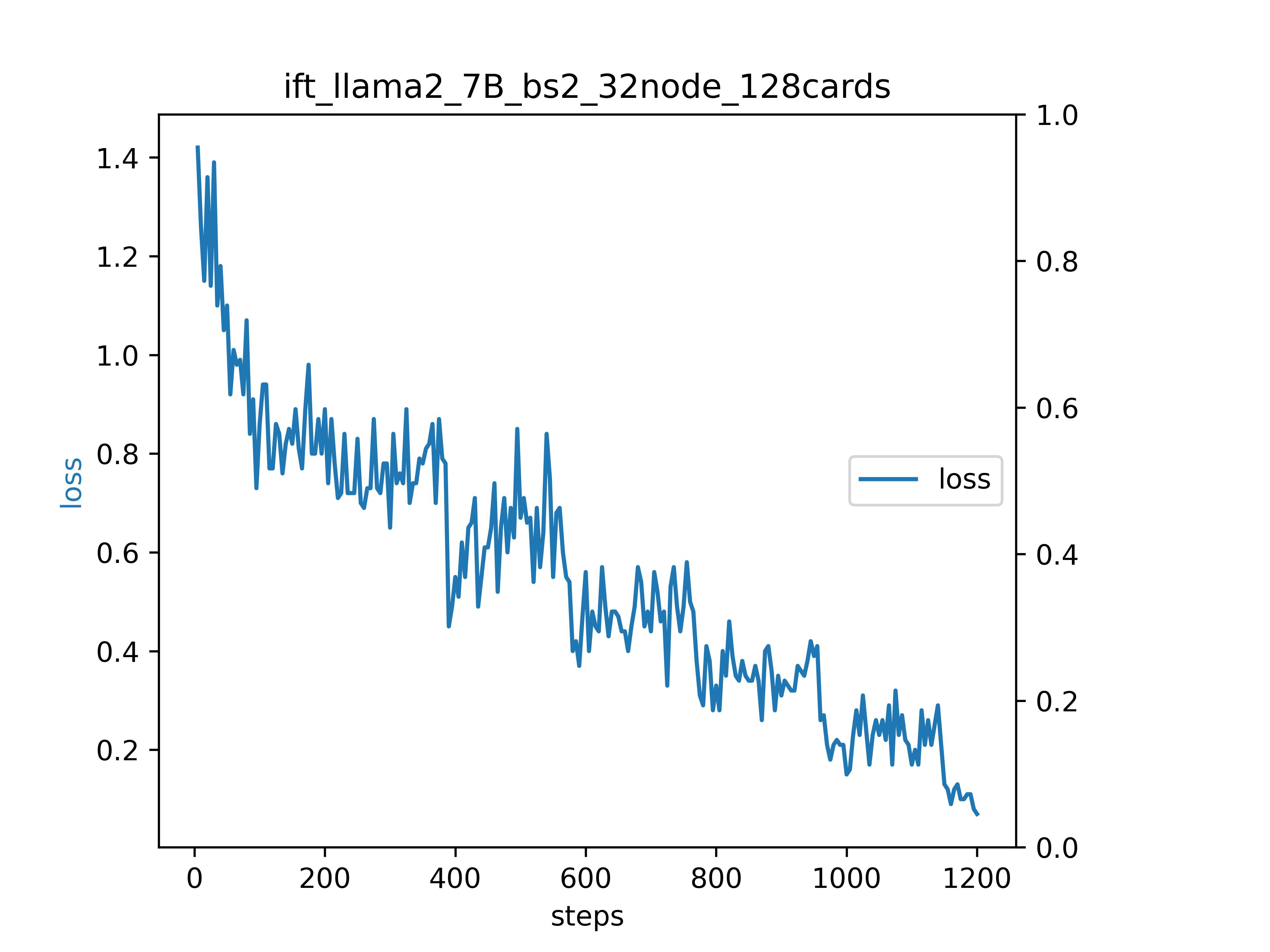
- 利用公开指令数据集[alpaca_gpt4_data_zh.json](https://huggingface.co/datasets/shibing624/alpaca-zh),基于汉化ChineseLLaMA的7B、13B基础模型,我们进行指令微调训练实验,以下为训练Loss:
- 利用公开指令数据集[alpaca_gpt4_data_zh.json](https://huggingface.co/datasets/shibing624/alpaca-zh),基于meta开源的[meta-llama/Llama-2-7b-chat-hf](https://pan.xunlei.com/s/VN_kQa1_HBvV-X9QVI6jV2kOA1?pwd=xmra) ,我们进行中文指令微调训练实验,以下为训练Loss:
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`医疗,教育,科研,金融`
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/llama_tencentpretrain_pytorch
## 参考资料
* https://github.com/CVI-SZU/Linly
* https://github.com/Tencent/TencentPretrain/
* https://github.com/ProjectD-AI/llama_inference