Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in
Toggle navigation
Menu
Open sidebar
ModelZoo
LLama_fastertransformer
Commits
0211193c
Commit
0211193c
authored
Aug 17, 2023
by
zhuwenwen
Browse files
initial llama
parents
Pipeline
#509
failed with stages
in 0 seconds
Changes
1000
Pipelines
1
Expand all
Show whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
1308 additions
and
0 deletions
+1308
-0
3rdparty/Megatron-LM/examples/sc21/SBATCH.sh
3rdparty/Megatron-LM/examples/sc21/SBATCH.sh
+13
-0
3rdparty/Megatron-LM/examples/sc21/SRUN.sh
3rdparty/Megatron-LM/examples/sc21/SRUN.sh
+18
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_11.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_11.sh
+46
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_12.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_12.sh
+54
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_13.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_13.sh
+46
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_14.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_14.sh
+47
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_15.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_15.sh
+47
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_16.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_16.sh
+43
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_17.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_17.sh
+54
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_18.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_18.sh
+54
-0
3rdparty/Megatron-LM/examples/sc21/run_table_1.sh
3rdparty/Megatron-LM/examples/sc21/run_table_1.sh
+145
-0
3rdparty/Megatron-LM/images/cases_april2021.png
3rdparty/Megatron-LM/images/cases_april2021.png
+0
-0
3rdparty/Megatron-LM/megatron/__init__.py
3rdparty/Megatron-LM/megatron/__init__.py
+46
-0
3rdparty/Megatron-LM/megatron/arguments.py
3rdparty/Megatron-LM/megatron/arguments.py
+0
-0
3rdparty/Megatron-LM/megatron/checkpointing.py
3rdparty/Megatron-LM/megatron/checkpointing.py
+490
-0
3rdparty/Megatron-LM/megatron/data/Makefile
3rdparty/Megatron-LM/megatron/data/Makefile
+9
-0
3rdparty/Megatron-LM/megatron/data/__init__.py
3rdparty/Megatron-LM/megatron/data/__init__.py
+1
-0
3rdparty/Megatron-LM/megatron/data/autoaugment.py
3rdparty/Megatron-LM/megatron/data/autoaugment.py
+0
-0
3rdparty/Megatron-LM/megatron/data/bert_dataset.py
3rdparty/Megatron-LM/megatron/data/bert_dataset.py
+195
-0
3rdparty/Megatron-LM/megatron/data/biencoder_dataset_utils.py
...arty/Megatron-LM/megatron/data/biencoder_dataset_utils.py
+0
-0
No files found.
Too many changes to show.
To preserve performance only
1000 of 1000+
files are displayed.
Plain diff
Email patch
3rdparty/Megatron-LM/examples/sc21/SBATCH.sh
0 → 100644
View file @
0211193c
#!/bin/bash
sbatch
-p
${
SLURM_PARTITION
}
\
-A
${
SLURM_ACCOUNT
}
\
--job-name
=
${
JOB_NAME
}
\
--nodes
=
${
NNODES
}
\
--export
=
MEGATRON_CODE_DIR,MEGATRON_PARAMS,DOCKER_MOUNT_DIR SRUN.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/SRUN.sh
0 → 100644
View file @
0211193c
#!/bin/bash
#SBATCH -t 0:30:00 --exclusive --mem=0 --overcommit --ntasks-per-node=8
THIS_DIR
=
`
pwd
`
DATETIME
=
`
date
+
'date_%y-%m-%d_time_%H-%M-%S'
`
mkdir
-p
${
THIS_DIR
}
/logs
CMD
=
"python -u
${
MEGATRON_CODE_DIR
}
/pretrain_gpt.py
${
MEGATRON_PARAMS
}
"
srun
-l
\
--container-image
"nvcr.io#nvidia/pytorch:20.12-py3"
\
--container-mounts
"
${
THIS_DIR
}
:
${
THIS_DIR
}
,
${
MEGATRON_CODE_DIR
}
:
${
MEGATRON_CODE_DIR
}
,
${
DOCKER_MOUNT_DIR
}
:
${
DOCKER_MOUNT_DIR
}
"
\
--output
=
${
THIS_DIR
}
/logs/%x_%j_
$DATETIME
.log sh
-c
"
${
CMD
}
"
3rdparty/Megatron-LM/examples/sc21/run_figure_11.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Pipeline-parallel size options = [1, 2, 4, 8].
PP
=
1
# Batch size (global batch size) options = [8, 128].
GBS
=
8
# Set pipeline-parallel size options.
NLS
=
$((
3
*
PP
))
NNODES
=
${
PP
}
# Other params.
TP
=
8
MBS
=
1
HS
=
20480
NAH
=
128
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
# Name of the job.
export
JOB_NAME
=
results_figure_11_pipeline_parallel_size_
${
PP
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_12.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Interleaved schedule options = [YES, NO].
INTERLEAVED
=
YES
# Batch size (global batch size) options = [12, 24, 36, ..., 60].
GBS
=
12
# Set interleaved schedule options.
if
[
${
INTERLEAVED
}
==
"YES"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 2 "
elif
[
${
INTERLEAVED
}
==
"NO"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
else
echo
"Invalid configuration"
exit
1
fi
# Other params.
TP
=
8
PP
=
12
MBS
=
1
NLS
=
96
HS
=
12288
NAH
=
96
DDP
=
local
NNODES
=
12
# Name of the job.
export
JOB_NAME
=
results_figure_12_interleaved_
${
INTERLEAVED
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_13.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Pipeline-parallel size options = [2, 4, 8, 16, 32].
PP
=
2
# Batch size (global batch size) options = [32, 128].
GBS
=
32
# Set pipeline-parallel and tensor-parallel size options.
TP
=
$((
64
/
PP
))
# Other params.
MBS
=
1
NLS
=
32
HS
=
20480
NAH
=
128
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
NNODES
=
8
# Name of the job.
export
JOB_NAME
=
results_figure_13_pipeline_parallel_size_
${
PP
}
_tensor_parallel_size_
${
TP
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_14.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Pipeline-parallel size options = [2, 4, 8, 16, 32].
PP
=
2
# Batch size (global batch size) options = [32, 512].
GBS
=
32
# Set pipeline-parallel and data-parallel size options.
DP
=
$((
64
/
PP
))
# Other params.
TP
=
1
MBS
=
1
NLS
=
32
HS
=
3840
NAH
=
32
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
NNODES
=
8
# Name of the job.
export
JOB_NAME
=
results_figure_14_pipeline_parallel_size_
${
PP
}
_data_parallel_size_
${
DP
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_15.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Tensor-parallel size options = [2, 4, 8, 16, 32].
TP
=
2
# Batch size (global batch size) options = [32, 128, 512].
GBS
=
32
# Set tensor-parallel and data-parallel size options.
DP
=
$((
64
/
TP
))
# Other params.
PP
=
1
MBS
=
1
NLS
=
32
HS
=
3840
NAH
=
32
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
NNODES
=
8
# Name of the job.
export
JOB_NAME
=
results_figure_15_tensor_parallel_size_
${
TP
}
_data_parallel_size_
${
DP
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_16.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Microbatch size options = [1, 2, 4, 8].
MBS
=
1
# Batch size (global batch size) options = [128, 512].
GBS
=
128
# Other params.
TP
=
8
PP
=
8
NLS
=
32
HS
=
15360
NAH
=
128
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
NNODES
=
8
# Name of the job.
export
JOB_NAME
=
results_figure_16_microbatch_size_
${
MBS
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_17.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Activation recomputation options = [YES, NO].
ACTIVATION_RECOMPUTATION
=
YES
# Batch size (global batch size) options = [1, 2, 4, ..., 256].
GBS
=
1
# Set activation recomputation.
if
[
${
ACTIVATION_RECOMPUTATION
}
==
"YES"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
ACTIVATION_RECOMPUTATION
}
==
"NO"
]
;
then
MEGATRON_EXTRA_PARAMS
=
""
else
echo
"Invalid configuration"
exit
1
fi
# Other params.
TP
=
8
PP
=
16
MBS
=
1
NLS
=
80
HS
=
12288
NAH
=
96
DDP
=
local
NNODES
=
16
# Name of the job.
export
JOB_NAME
=
results_figure_17_activation_recomputation_
${
ACTIVATION_RECOMPUTATION
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_18.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Scatter-gather communication optimization options = [YES, NO].
SCATTER_GATHER
=
YES
# Batch size (global batch size) options = [12, 24, 36, ..., 60].
GBS
=
12
# Set scatter-gather communication optimization options.
if
[
${
SCATTER_GATHER
}
==
"YES"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 2 "
elif
[
${
SCATTER_GATHER
}
==
"NO"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 2 --no-scatter-gather-tensors-in-pipeline "
else
echo
"Invalid configuration"
exit
1
fi
# Other params.
TP
=
8
PP
=
12
MBS
=
1
NLS
=
96
HS
=
12288
NAH
=
96
DDP
=
local
NNODES
=
12
# Name of the job.
export
JOB_NAME
=
results_figure_18_scatter_gather_
${
SCATTER_GATHER
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
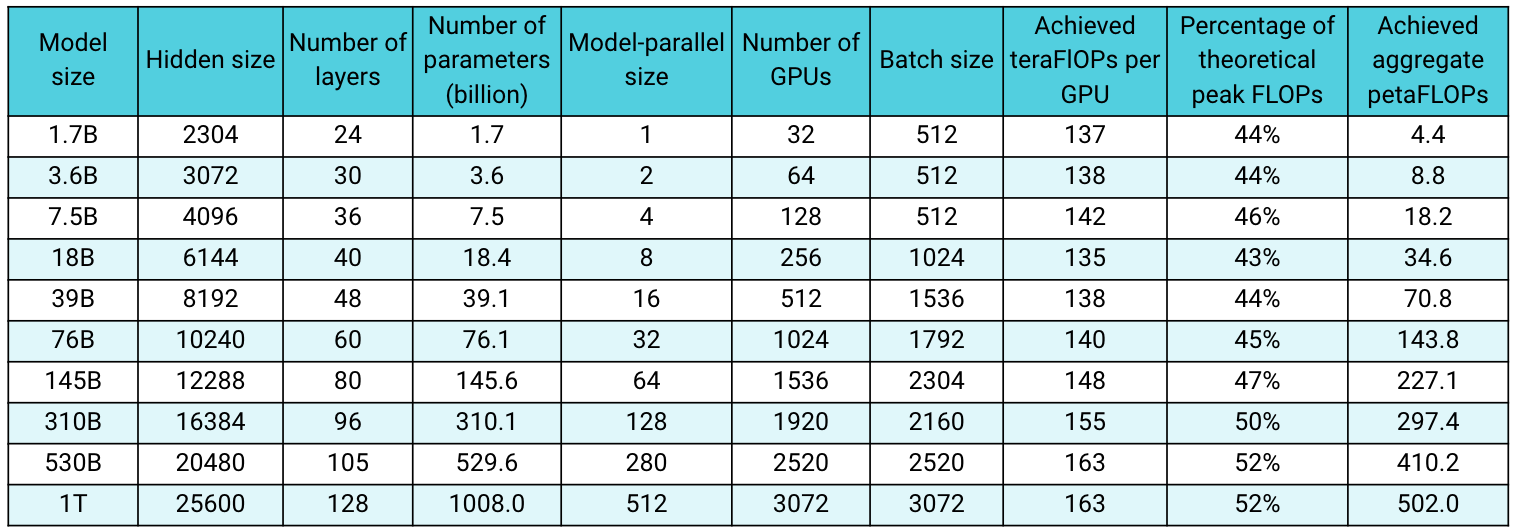
3rdparty/Megatron-LM/examples/sc21/run_table_1.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# model size options = [1.7B, 3.6B, 7.5B, 18B, 39B, 76B, 145B, 310B, 530B, 1T]
MODEL_SIZE
=
1.7B
if
[
${
MODEL_SIZE
}
==
"1.7B"
]
;
then
TP
=
1
PP
=
1
MBS
=
16
GBS
=
512
NLS
=
24
HS
=
2304
NAH
=
24
DDP
=
torch
NNODES
=
4
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"3.6B"
]
;
then
TP
=
2
PP
=
1
MBS
=
16
GBS
=
512
NLS
=
30
HS
=
3072
NAH
=
32
DDP
=
torch
NNODES
=
8
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"7.5B"
]
;
then
TP
=
4
PP
=
1
MBS
=
16
GBS
=
512
NLS
=
36
HS
=
4096
NAH
=
32
DDP
=
torch
NNODES
=
16
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"18B"
]
;
then
TP
=
8
PP
=
1
MBS
=
8
GBS
=
1024
NLS
=
40
HS
=
6144
NAH
=
48
DDP
=
torch
NNODES
=
32
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"39B"
]
;
then
TP
=
8
PP
=
2
MBS
=
4
GBS
=
1536
NLS
=
48
HS
=
8192
NAH
=
64
DDP
=
local
NNODES
=
64
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"76B"
]
;
then
TP
=
8
PP
=
4
MBS
=
2
GBS
=
1792
NLS
=
60
HS
=
10240
NAH
=
80
DDP
=
local
NNODES
=
128
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 5"
elif
[
${
MODEL_SIZE
}
==
"145B"
]
;
then
TP
=
8
PP
=
8
MBS
=
2
GBS
=
2304
NLS
=
80
HS
=
12288
NAH
=
96
DDP
=
local
NNODES
=
192
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 5 "
elif
[
${
MODEL_SIZE
}
==
"310B"
]
;
then
TP
=
8
PP
=
16
MBS
=
1
GBS
=
2160
NLS
=
96
HS
=
16384
NAH
=
128
DDP
=
local
NNODES
=
240
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 3 "
elif
[
${
MODEL_SIZE
}
==
"530B"
]
;
then
TP
=
8
PP
=
35
MBS
=
1
GBS
=
2520
NLS
=
105
HS
=
20480
NAH
=
128
DDP
=
local
NNODES
=
315
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 1 "
elif
[
${
MODEL_SIZE
}
==
"1T"
]
;
then
TP
=
8
PP
=
64
MBS
=
1
GBS
=
3072
NLS
=
128
HS
=
25600
NAH
=
160
DDP
=
local
NNODES
=
384
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
else
echo
"Invalid configuration"
exit
1
fi
# Name of the job
export
JOB_NAME
=
results_table_1_model_size_
${
MODEL_SIZE
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/images/cases_april2021.png
0 → 100644
View file @
0211193c
159 KB
3rdparty/Megatron-LM/megatron/__init__.py
0 → 100644
View file @
0211193c
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
torch
from
.global_vars
import
get_args
from
.global_vars
import
get_current_global_batch_size
from
.global_vars
import
get_num_microbatches
from
.global_vars
import
get_signal_handler
from
.global_vars
import
update_num_microbatches
from
.global_vars
import
get_tokenizer
from
.global_vars
import
get_tensorboard_writer
from
.global_vars
import
get_adlr_autoresume
from
.global_vars
import
get_timers
from
.initialize
import
initialize_megatron
def
print_rank_0
(
message
):
"""If distributed is initialized, print only on rank 0."""
if
torch
.
distributed
.
is_initialized
():
if
torch
.
distributed
.
get_rank
()
==
0
:
print
(
message
,
flush
=
True
)
else
:
print
(
message
,
flush
=
True
)
def
is_last_rank
():
return
torch
.
distributed
.
get_rank
()
==
(
torch
.
distributed
.
get_world_size
()
-
1
)
def
print_rank_last
(
message
):
"""If distributed is initialized, print only on last rank."""
if
torch
.
distributed
.
is_initialized
():
if
is_last_rank
():
print
(
message
,
flush
=
True
)
else
:
print
(
message
,
flush
=
True
)
3rdparty/Megatron-LM/megatron/arguments.py
0 → 100644
View file @
0211193c
This diff is collapsed.
Click to expand it.
3rdparty/Megatron-LM/megatron/checkpointing.py
0 → 100644
View file @
0211193c
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Input/output checkpointing."""
import
os
import
random
import
sys
import
numpy
as
np
import
torch
from
megatron
import
(
get_args
,
mpu
,
print_rank_0
,
update_num_microbatches
,
utils
)
_CHECKPOINT_VERSION
=
None
def
set_checkpoint_version
(
value
):
global
_CHECKPOINT_VERSION
if
_CHECKPOINT_VERSION
is
not
None
:
assert
_CHECKPOINT_VERSION
==
value
,
\
"checkpoint versions do not match"
_CHECKPOINT_VERSION
=
value
def
get_checkpoint_version
():
global
_CHECKPOINT_VERSION
return
_CHECKPOINT_VERSION
def
check_checkpoint_args
(
checkpoint_args
):
"""Ensure fixed arguments for a model are the same for the input
arguments and the one retrieved from checkpoint."""
args
=
get_args
()
def
_compare
(
arg_name
,
old_arg_name
=
None
):
if
old_arg_name
is
not
None
:
checkpoint_value
=
getattr
(
checkpoint_args
,
old_arg_name
)
else
:
checkpoint_value
=
getattr
(
checkpoint_args
,
arg_name
)
args_value
=
getattr
(
args
,
arg_name
)
error_message
=
'{} value from checkpoint ({}) is not equal to the '
\
'input argument value ({}).'
.
format
(
arg_name
,
checkpoint_value
,
args_value
)
assert
checkpoint_value
==
args_value
,
error_message
_compare
(
'num_layers'
)
_compare
(
'hidden_size'
)
_compare
(
'num_attention_heads'
)
if
args
.
vocab_file
:
_compare
(
'max_position_embeddings'
)
_compare
(
'make_vocab_size_divisible_by'
)
_compare
(
'padded_vocab_size'
)
_compare
(
'tokenizer_type'
)
if
args
.
data_parallel_random_init
:
_compare
(
'data_parallel_random_init'
)
if
get_checkpoint_version
()
<
3.0
:
_compare
(
'tensor_model_parallel_size'
,
old_arg_name
=
'model_parallel_size'
)
if
get_checkpoint_version
()
>=
3.0
:
_compare
(
'tensor_model_parallel_size'
)
_compare
(
'pipeline_model_parallel_size'
)
def
ensure_directory_exists
(
filename
):
"""Build filename's path if it does not already exists."""
dirname
=
os
.
path
.
dirname
(
filename
)
if
not
os
.
path
.
exists
(
dirname
):
os
.
makedirs
(
dirname
)
def
get_checkpoint_name
(
checkpoints_path
,
iteration
,
release
=
False
):
"""A unified checkpoint name."""
if
release
:
directory
=
'release'
else
:
directory
=
'iter_{:07d}'
.
format
(
iteration
)
# Use both the tensor and pipeline MP rank.
if
mpu
.
get_pipeline_model_parallel_world_size
()
==
1
:
return
os
.
path
.
join
(
checkpoints_path
,
directory
,
'mp_rank_{:02d}'
.
format
(
mpu
.
get_tensor_model_parallel_rank
()),
'model_optim_rng.pt'
)
return
os
.
path
.
join
(
checkpoints_path
,
directory
,
'mp_rank_{:02d}_{:03d}'
.
format
(
mpu
.
get_tensor_model_parallel_rank
(),
mpu
.
get_pipeline_model_parallel_rank
()),
'model_optim_rng.pt'
)
def
get_checkpoint_tracker_filename
(
checkpoints_path
):
"""Tracker file rescords the latest chckpoint during
training to restart from."""
return
os
.
path
.
join
(
checkpoints_path
,
'latest_checkpointed_iteration.txt'
)
def
read_metadata
(
tracker_filename
):
# Read the tracker file and either set the iteration or
# mark it as a release checkpoint.
iteration
=
0
release
=
False
with
open
(
tracker_filename
,
'r'
)
as
f
:
metastring
=
f
.
read
().
strip
()
try
:
iteration
=
int
(
metastring
)
except
ValueError
:
release
=
metastring
==
'release'
if
not
release
:
print_rank_0
(
'ERROR: Invalid metadata file {}. Exiting'
.
format
(
tracker_filename
))
sys
.
exit
()
assert
iteration
>
0
or
release
,
'error parsing metadata file {}'
.
format
(
tracker_filename
)
# Get the max iteration retrieved across the ranks.
iters_cuda
=
torch
.
cuda
.
LongTensor
([
iteration
])
torch
.
distributed
.
all_reduce
(
iters_cuda
,
op
=
torch
.
distributed
.
ReduceOp
.
MAX
)
max_iter
=
iters_cuda
[
0
].
item
()
# We should now have all the same iteration.
# If not, print a warning and chose the maximum
# iteration across all ranks.
if
iteration
!=
max_iter
:
print
(
'WARNING: on rank {} found iteration {} in the '
'metadata while max iteration across the ranks '
'is {}, replacing it with max iteration.'
.
format
(
rank
,
iteration
,
max_iter
),
flush
=
True
)
return
max_iter
,
release
def
get_rng_state
():
""" collect rng state across data parallel ranks """
args
=
get_args
()
rng_state
=
{
'random_rng_state'
:
random
.
getstate
(),
'np_rng_state'
:
np
.
random
.
get_state
(),
'torch_rng_state'
:
torch
.
get_rng_state
(),
'cuda_rng_state'
:
torch
.
cuda
.
get_rng_state
(),
'rng_tracker_states'
:
mpu
.
get_cuda_rng_tracker
().
get_states
()}
rng_state_list
=
None
if
torch
.
distributed
.
is_initialized
()
and
\
mpu
.
get_data_parallel_world_size
()
>
1
and
\
args
.
data_parallel_random_init
:
rng_state_list
=
\
[
None
for
i
in
range
(
mpu
.
get_data_parallel_world_size
())]
torch
.
distributed
.
all_gather_object
(
rng_state_list
,
rng_state
,
group
=
mpu
.
get_data_parallel_group
())
else
:
rng_state_list
=
[
rng_state
]
return
rng_state_list
def
save_checkpoint
(
iteration
,
model
,
optimizer
,
lr_scheduler
):
"""Save a model checkpoint."""
args
=
get_args
()
# Only rank zero of the data parallel writes to the disk.
model
=
utils
.
unwrap_model
(
model
)
print_rank_0
(
'saving checkpoint at iteration {:7d} to {}'
.
format
(
iteration
,
args
.
save
))
# collect rng state across data parallel ranks
rng_state
=
get_rng_state
()
if
not
torch
.
distributed
.
is_initialized
()
or
mpu
.
get_data_parallel_rank
()
==
0
:
# Arguments, iteration, and model.
state_dict
=
{}
state_dict
[
'args'
]
=
args
state_dict
[
'checkpoint_version'
]
=
3.0
state_dict
[
'iteration'
]
=
iteration
if
len
(
model
)
==
1
:
state_dict
[
'model'
]
=
model
[
0
].
state_dict_for_save_checkpoint
()
else
:
for
i
in
range
(
len
(
model
)):
mpu
.
set_virtual_pipeline_model_parallel_rank
(
i
)
state_dict
[
'model%d'
%
i
]
=
model
[
i
].
state_dict_for_save_checkpoint
()
# Optimizer stuff.
if
not
args
.
no_save_optim
:
if
optimizer
is
not
None
:
state_dict
[
'optimizer'
]
=
optimizer
.
state_dict
()
if
lr_scheduler
is
not
None
:
state_dict
[
'lr_scheduler'
]
=
lr_scheduler
.
state_dict
()
# RNG states.
if
not
args
.
no_save_rng
:
state_dict
[
"rng_state"
]
=
rng_state
# Save.
checkpoint_name
=
get_checkpoint_name
(
args
.
save
,
iteration
)
ensure_directory_exists
(
checkpoint_name
)
torch
.
save
(
state_dict
,
checkpoint_name
)
# Wait so everyone is done (necessary)
if
torch
.
distributed
.
is_initialized
():
torch
.
distributed
.
barrier
()
print_rank_0
(
' successfully saved checkpoint at iteration {:7d} to {}'
.
format
(
iteration
,
args
.
save
))
# And update the latest iteration
if
not
torch
.
distributed
.
is_initialized
()
or
torch
.
distributed
.
get_rank
()
==
0
:
tracker_filename
=
get_checkpoint_tracker_filename
(
args
.
save
)
with
open
(
tracker_filename
,
'w'
)
as
f
:
f
.
write
(
str
(
iteration
))
# Wait so everyone is done (not necessary)
if
torch
.
distributed
.
is_initialized
():
torch
.
distributed
.
barrier
()
def
_transpose_first_dim
(
t
,
num_splits
,
num_splits_first
,
model
):
input_shape
=
t
.
size
()
# We use a self_attention module but the values extracted aren't
# specific to self attention so should work for cross attention as well
while
hasattr
(
model
,
'module'
):
model
=
model
.
module
attention_module
=
model
.
language_model
.
encoder
.
layers
[
0
].
self_attention
hidden_size_per_attention_head
=
attention_module
.
hidden_size_per_attention_head
num_attention_heads_per_partition
=
attention_module
.
num_attention_heads_per_partition
if
num_splits_first
:
"""[num_splits * np * hn, h]
-->(view) [num_splits, np, hn, h]
-->(tranpose) [np, num_splits, hn, h]
-->(view) [np * num_splits * hn, h] """
intermediate_shape
=
\
(
num_splits
,
num_attention_heads_per_partition
,
hidden_size_per_attention_head
)
+
input_shape
[
1
:]
t
=
t
.
view
(
*
intermediate_shape
)
t
=
t
.
transpose
(
0
,
1
).
contiguous
()
else
:
"""[np * hn * num_splits, h]
-->(view) [np, hn, num_splits, h]
-->(tranpose) [np, num_splits, hn, h]
-->(view) [np * num_splits * hn, h] """
intermediate_shape
=
\
(
num_attention_heads_per_partition
,
hidden_size_per_attention_head
,
num_splits
)
+
\
input_shape
[
1
:]
t
=
t
.
view
(
*
intermediate_shape
)
t
=
t
.
transpose
(
1
,
2
).
contiguous
()
t
=
t
.
view
(
*
input_shape
)
return
t
def
fix_query_key_value_ordering
(
model
,
checkpoint_version
):
"""Fix up query/key/value matrix ordering if checkpoint
version is smaller than 2.0
"""
if
checkpoint_version
<
2.0
:
if
isinstance
(
model
,
list
):
assert
len
(
model
)
==
1
model
=
model
[
0
]
for
name
,
param
in
model
.
named_parameters
():
if
name
.
endswith
((
'.query_key_value.weight'
,
'.query_key_value.bias'
)):
if
checkpoint_version
==
0
:
fixed_param
=
_transpose_first_dim
(
param
.
data
,
3
,
True
,
model
)
elif
checkpoint_version
==
1.0
:
fixed_param
=
_transpose_first_dim
(
param
.
data
,
3
,
False
,
model
)
else
:
print_rank_0
(
f
"Invalid checkpoint version
{
checkpoint_version
}
."
)
sys
.
exit
()
param
.
data
.
copy_
(
fixed_param
)
if
name
.
endswith
((
'.key_value.weight'
,
'.key_value.bias'
)):
if
checkpoint_version
==
0
:
fixed_param
=
_transpose_first_dim
(
param
.
data
,
2
,
True
,
model
)
elif
checkpoint_version
==
1.0
:
fixed_param
=
_transpose_first_dim
(
param
.
data
,
2
,
False
,
model
)
else
:
print_rank_0
(
f
"Invalid checkpoint version
{
checkpoint_version
}
."
)
sys
.
exit
()
param
.
data
.
copy_
(
fixed_param
)
print_rank_0
(
" succesfully fixed query-key-values ordering for"
" checkpoint version {}"
.
format
(
checkpoint_version
))
def
load_checkpoint
(
model
,
optimizer
,
lr_scheduler
,
load_arg
=
'load'
,
strict
=
True
):
"""Load a model checkpoint and return the iteration.
strict (bool): whether to strictly enforce that the keys in
:attr:`state_dict` of the checkpoint match the names of
parameters and buffers in model.
"""
args
=
get_args
()
load_dir
=
getattr
(
args
,
load_arg
)
model
=
utils
.
unwrap_model
(
model
)
# Read the tracker file and set the iteration.
tracker_filename
=
get_checkpoint_tracker_filename
(
load_dir
)
# If no tracker file, return iretation zero.
if
not
os
.
path
.
isfile
(
tracker_filename
):
print_rank_0
(
'WARNING: could not find the metadata file {} '
.
format
(
tracker_filename
))
print_rank_0
(
' will not load any checkpoints and will start from '
'random'
)
return
0
# Otherwise, read the tracker file and either set the iteration or
# mark it as a release checkpoint.
iteration
,
release
=
read_metadata
(
tracker_filename
)
# Checkpoint.
checkpoint_name
=
get_checkpoint_name
(
load_dir
,
iteration
,
release
)
print_rank_0
(
f
' loading checkpoint from
{
args
.
load
}
at iteration
{
iteration
}
'
)
# Load the checkpoint.
try
:
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
except
ModuleNotFoundError
:
from
megatron.fp16_deprecated
import
loss_scaler
# For backward compatibility.
print_rank_0
(
' > deserializing using the old code structure ...'
)
sys
.
modules
[
'fp16.loss_scaler'
]
=
sys
.
modules
[
'megatron.fp16_deprecated.loss_scaler'
]
sys
.
modules
[
'megatron.fp16.loss_scaler'
]
=
sys
.
modules
[
'megatron.fp16_deprecated.loss_scaler'
]
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
sys
.
modules
.
pop
(
'fp16.loss_scaler'
,
None
)
sys
.
modules
.
pop
(
'megatron.fp16.loss_scaler'
,
None
)
except
BaseException
as
e
:
print_rank_0
(
'could not load the checkpoint'
)
print_rank_0
(
e
)
sys
.
exit
()
# set checkpoint version
set_checkpoint_version
(
state_dict
.
get
(
'checkpoint_version'
,
0
))
# Set iteration.
if
args
.
finetune
or
release
:
iteration
=
0
else
:
try
:
iteration
=
state_dict
[
'iteration'
]
except
KeyError
:
try
:
# Backward compatible with older checkpoints
iteration
=
state_dict
[
'total_iters'
]
except
KeyError
:
print_rank_0
(
'A metadata file exists but unable to load '
'iteration from checkpoint {}, exiting'
.
format
(
checkpoint_name
))
sys
.
exit
()
# Check arguments.
assert
args
.
consumed_train_samples
==
0
assert
args
.
consumed_valid_samples
==
0
if
'args'
in
state_dict
:
checkpoint_args
=
state_dict
[
'args'
]
check_checkpoint_args
(
checkpoint_args
)
args
.
consumed_train_samples
=
getattr
(
checkpoint_args
,
'consumed_train_samples'
,
0
)
update_num_microbatches
(
consumed_samples
=
args
.
consumed_train_samples
)
args
.
consumed_valid_samples
=
getattr
(
checkpoint_args
,
'consumed_valid_samples'
,
0
)
else
:
print_rank_0
(
'could not find arguments in the checkpoint ...'
)
# Model.
if
len
(
model
)
==
1
:
model
[
0
].
load_state_dict
(
state_dict
[
'model'
],
strict
=
strict
)
else
:
for
i
in
range
(
len
(
model
)):
mpu
.
set_virtual_pipeline_model_parallel_rank
(
i
)
model
[
i
].
load_state_dict
(
state_dict
[
'model%d'
%
i
],
strict
=
strict
)
# Fix up query/key/value matrix ordering if needed
checkpoint_version
=
get_checkpoint_version
()
print_rank_0
(
f
' checkpoint version
{
checkpoint_version
}
'
)
fix_query_key_value_ordering
(
model
,
checkpoint_version
)
# Optimizer.
if
not
release
and
not
args
.
finetune
and
not
args
.
no_load_optim
:
try
:
if
optimizer
is
not
None
:
optimizer
.
load_state_dict
(
state_dict
[
'optimizer'
])
if
lr_scheduler
is
not
None
:
lr_scheduler
.
load_state_dict
(
state_dict
[
'lr_scheduler'
])
except
KeyError
:
print_rank_0
(
'Unable to load optimizer from checkpoint {}. '
'Specify --no-load-optim or --finetune to prevent '
'attempting to load the optimizer state, '
'exiting ...'
.
format
(
checkpoint_name
))
sys
.
exit
()
# rng states.
if
not
release
and
not
args
.
finetune
and
not
args
.
no_load_rng
:
try
:
if
'rng_state'
in
state_dict
:
# access rng_state for data parallel rank
if
args
.
data_parallel_random_init
:
rng_state
=
state_dict
[
'rng_state'
][
mpu
.
get_data_parallel_rank
()]
else
:
rng_state
=
state_dict
[
'rng_state'
][
0
]
random
.
setstate
(
rng_state
[
'random_rng_state'
])
np
.
random
.
set_state
(
rng_state
[
'np_rng_state'
])
torch
.
set_rng_state
(
rng_state
[
'torch_rng_state'
])
torch
.
cuda
.
set_rng_state
(
rng_state
[
'cuda_rng_state'
])
# Check for empty states array
if
not
rng_state
[
'rng_tracker_states'
]:
raise
KeyError
mpu
.
get_cuda_rng_tracker
().
set_states
(
rng_state
[
'rng_tracker_states'
])
else
:
# backward compatability
random
.
setstate
(
state_dict
[
'random_rng_state'
])
np
.
random
.
set_state
(
state_dict
[
'np_rng_state'
])
torch
.
set_rng_state
(
state_dict
[
'torch_rng_state'
])
torch
.
cuda
.
set_rng_state
(
state_dict
[
'cuda_rng_state'
])
# Check for empty states array
if
not
state_dict
[
'rng_tracker_states'
]:
raise
KeyError
mpu
.
get_cuda_rng_tracker
().
set_states
(
state_dict
[
'rng_tracker_states'
])
except
KeyError
:
print_rank_0
(
'Unable to load rng state from checkpoint {}. '
'Specify --no-load-rng or --finetune to prevent '
'attempting to load the rng state, '
'exiting ...'
.
format
(
checkpoint_name
))
sys
.
exit
()
# Some utilities want to load a checkpoint without distributed being initialized
if
torch
.
distributed
.
is_initialized
():
torch
.
distributed
.
barrier
()
print_rank_0
(
f
' successfully loaded checkpoint from
{
args
.
load
}
'
f
'at iteration
{
iteration
}
'
)
return
iteration
def
load_biencoder_checkpoint
(
model
,
only_query_model
=
False
,
only_context_model
=
False
,
custom_load_path
=
None
):
"""
selectively load retrieval models for indexing/retrieving
from saved checkpoints
"""
args
=
get_args
()
model
=
utils
.
unwrap_model
(
model
)
load_path
=
custom_load_path
if
custom_load_path
is
not
None
else
args
.
load
tracker_filename
=
get_checkpoint_tracker_filename
(
load_path
)
with
open
(
tracker_filename
,
'r'
)
as
f
:
iteration
=
int
(
f
.
read
().
strip
())
checkpoint_name
=
get_checkpoint_name
(
load_path
,
iteration
,
False
)
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
'global rank {} is loading checkpoint {}'
.
format
(
torch
.
distributed
.
get_rank
(),
checkpoint_name
))
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
ret_state_dict
=
state_dict
[
'model'
]
if
only_query_model
:
ret_state_dict
.
pop
(
'context_model'
)
if
only_context_model
:
ret_state_dict
.
pop
(
'query_model'
)
assert
len
(
model
)
==
1
model
[
0
].
load_state_dict
(
ret_state_dict
)
torch
.
distributed
.
barrier
()
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
' successfully loaded {}'
.
format
(
checkpoint_name
))
return
model
3rdparty/Megatron-LM/megatron/data/Makefile
0 → 100644
View file @
0211193c
CXXFLAGS
+=
-O3
-Wall
-shared
-std
=
c++11
-fPIC
-fdiagnostics-color
CPPFLAGS
+=
$(
shell
python3
-m
pybind11
--includes
)
LIBNAME
=
helpers
LIBEXT
=
$(
shell
python3-config
--extension-suffix
)
default
:
$(LIBNAME)$(LIBEXT)
%$(LIBEXT)
:
%.cpp
$(CXX)
$(CXXFLAGS)
$(CPPFLAGS)
$<
-o
$@
3rdparty/Megatron-LM/megatron/data/__init__.py
0 → 100644
View file @
0211193c
from
.
import
indexed_dataset
3rdparty/Megatron-LM/megatron/data/autoaugment.py
0 → 100644
View file @
0211193c
This diff is collapsed.
Click to expand it.
3rdparty/Megatron-LM/megatron/data/bert_dataset.py
0 → 100644
View file @
0211193c
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""BERT Style dataset."""
import
numpy
as
np
import
torch
from
megatron
import
(
get_args
,
get_tokenizer
,
mpu
,
print_rank_0
)
from
megatron.data.dataset_utils
import
(
get_samples_mapping
,
get_a_and_b_segments
,
truncate_segments
,
create_tokens_and_tokentypes
,
create_masked_lm_predictions
)
class
BertDataset
(
torch
.
utils
.
data
.
Dataset
):
def
__init__
(
self
,
name
,
indexed_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
masked_lm_prob
,
max_seq_length
,
short_seq_prob
,
seed
,
binary_head
):
# Params to store.
self
.
name
=
name
self
.
seed
=
seed
self
.
masked_lm_prob
=
masked_lm_prob
self
.
max_seq_length
=
max_seq_length
self
.
binary_head
=
binary_head
# Dataset.
self
.
indexed_dataset
=
indexed_dataset
# Build the samples mapping.
self
.
samples_mapping
=
get_samples_mapping
(
self
.
indexed_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
self
.
max_seq_length
-
3
,
# account for added tokens
short_seq_prob
,
self
.
seed
,
self
.
name
,
self
.
binary_head
)
# Vocab stuff.
tokenizer
=
get_tokenizer
()
self
.
vocab_id_list
=
list
(
tokenizer
.
inv_vocab
.
keys
())
self
.
vocab_id_to_token_dict
=
tokenizer
.
inv_vocab
self
.
cls_id
=
tokenizer
.
cls
self
.
sep_id
=
tokenizer
.
sep
self
.
mask_id
=
tokenizer
.
mask
self
.
pad_id
=
tokenizer
.
pad
def
__len__
(
self
):
return
self
.
samples_mapping
.
shape
[
0
]
def
__getitem__
(
self
,
idx
):
start_idx
,
end_idx
,
seq_length
=
self
.
samples_mapping
[
idx
]
sample
=
[
self
.
indexed_dataset
[
i
]
for
i
in
range
(
start_idx
,
end_idx
)]
# Note that this rng state should be numpy and not python since
# python randint is inclusive whereas the numpy one is exclusive.
# We % 2**32 since numpy requres the seed to be between 0 and 2**32 - 1
np_rng
=
np
.
random
.
RandomState
(
seed
=
((
self
.
seed
+
idx
)
%
2
**
32
))
return
build_training_sample
(
sample
,
seq_length
,
self
.
max_seq_length
,
# needed for padding
self
.
vocab_id_list
,
self
.
vocab_id_to_token_dict
,
self
.
cls_id
,
self
.
sep_id
,
self
.
mask_id
,
self
.
pad_id
,
self
.
masked_lm_prob
,
np_rng
,
self
.
binary_head
)
def
build_training_sample
(
sample
,
target_seq_length
,
max_seq_length
,
vocab_id_list
,
vocab_id_to_token_dict
,
cls_id
,
sep_id
,
mask_id
,
pad_id
,
masked_lm_prob
,
np_rng
,
binary_head
):
"""Biuld training sample.
Arguments:
sample: A list of sentences in which each sentence is a list token ids.
target_seq_length: Desired sequence length.
max_seq_length: Maximum length of the sequence. All values are padded to
this length.
vocab_id_list: List of vocabulary ids. Used to pick a random id.
vocab_id_to_token_dict: A dictionary from vocab ids to text tokens.
cls_id: Start of example id.
sep_id: Separator id.
mask_id: Mask token id.
pad_id: Padding token id.
masked_lm_prob: Probability to mask tokens.
np_rng: Random number genenrator. Note that this rng state should be
numpy and not python since python randint is inclusive for
the opper bound whereas the numpy one is exclusive.
"""
if
binary_head
:
# We assume that we have at least two sentences in the sample
assert
len
(
sample
)
>
1
assert
target_seq_length
<=
max_seq_length
# Divide sample into two segments (A and B).
if
binary_head
:
tokens_a
,
tokens_b
,
is_next_random
=
get_a_and_b_segments
(
sample
,
np_rng
)
else
:
tokens_a
=
[]
for
j
in
range
(
len
(
sample
)):
tokens_a
.
extend
(
sample
[
j
])
tokens_b
=
[]
is_next_random
=
False
# Truncate to `target_sequence_length`.
max_num_tokens
=
target_seq_length
truncated
=
truncate_segments
(
tokens_a
,
tokens_b
,
len
(
tokens_a
),
len
(
tokens_b
),
max_num_tokens
,
np_rng
)
# Build tokens and toketypes.
tokens
,
tokentypes
=
create_tokens_and_tokentypes
(
tokens_a
,
tokens_b
,
cls_id
,
sep_id
)
# Masking.
max_predictions_per_seq
=
masked_lm_prob
*
max_num_tokens
(
tokens
,
masked_positions
,
masked_labels
,
_
,
_
)
=
create_masked_lm_predictions
(
tokens
,
vocab_id_list
,
vocab_id_to_token_dict
,
masked_lm_prob
,
cls_id
,
sep_id
,
mask_id
,
max_predictions_per_seq
,
np_rng
)
# Padding.
tokens_np
,
tokentypes_np
,
labels_np
,
padding_mask_np
,
loss_mask_np
\
=
pad_and_convert_to_numpy
(
tokens
,
tokentypes
,
masked_positions
,
masked_labels
,
pad_id
,
max_seq_length
)
train_sample
=
{
'text'
:
tokens_np
,
'types'
:
tokentypes_np
,
'labels'
:
labels_np
,
'is_random'
:
int
(
is_next_random
),
'loss_mask'
:
loss_mask_np
,
'padding_mask'
:
padding_mask_np
,
'truncated'
:
int
(
truncated
)}
return
train_sample
def
pad_and_convert_to_numpy
(
tokens
,
tokentypes
,
masked_positions
,
masked_labels
,
pad_id
,
max_seq_length
):
"""Pad sequences and convert them to numpy."""
# Some checks.
num_tokens
=
len
(
tokens
)
padding_length
=
max_seq_length
-
num_tokens
assert
padding_length
>=
0
assert
len
(
tokentypes
)
==
num_tokens
assert
len
(
masked_positions
)
==
len
(
masked_labels
)
# Tokens and token types.
filler
=
[
pad_id
]
*
padding_length
tokens_np
=
np
.
array
(
tokens
+
filler
,
dtype
=
np
.
int64
)
tokentypes_np
=
np
.
array
(
tokentypes
+
filler
,
dtype
=
np
.
int64
)
# Padding mask.
padding_mask_np
=
np
.
array
([
1
]
*
num_tokens
+
[
0
]
*
padding_length
,
dtype
=
np
.
int64
)
# Lables and loss mask.
labels
=
[
-
1
]
*
max_seq_length
loss_mask
=
[
0
]
*
max_seq_length
for
i
in
range
(
len
(
masked_positions
)):
assert
masked_positions
[
i
]
<
num_tokens
labels
[
masked_positions
[
i
]]
=
masked_labels
[
i
]
loss_mask
[
masked_positions
[
i
]]
=
1
labels_np
=
np
.
array
(
labels
,
dtype
=
np
.
int64
)
loss_mask_np
=
np
.
array
(
loss_mask
,
dtype
=
np
.
int64
)
return
tokens_np
,
tokentypes_np
,
labels_np
,
padding_mask_np
,
loss_mask_np
3rdparty/Megatron-LM/megatron/data/biencoder_dataset_utils.py
0 → 100644
View file @
0211193c
This diff is collapsed.
Click to expand it.
Prev
1
2
3
4
5
6
7
…
50
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}