Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
LLama_fastertransformer
Commits
0211193c
Commit
0211193c
authored
Aug 17, 2023
by
zhuwenwen
Browse files
initial llama
parents
Pipeline
#509
failed with stages
in 0 seconds
Changes
260
Pipelines
1
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
2690 additions
and
0 deletions
+2690
-0
3rdparty/Megatron-LM/examples/sc21/SBATCH.sh
3rdparty/Megatron-LM/examples/sc21/SBATCH.sh
+13
-0
3rdparty/Megatron-LM/examples/sc21/SRUN.sh
3rdparty/Megatron-LM/examples/sc21/SRUN.sh
+18
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_11.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_11.sh
+46
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_12.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_12.sh
+54
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_13.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_13.sh
+46
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_14.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_14.sh
+47
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_15.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_15.sh
+47
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_16.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_16.sh
+43
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_17.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_17.sh
+54
-0
3rdparty/Megatron-LM/examples/sc21/run_figure_18.sh
3rdparty/Megatron-LM/examples/sc21/run_figure_18.sh
+54
-0
3rdparty/Megatron-LM/examples/sc21/run_table_1.sh
3rdparty/Megatron-LM/examples/sc21/run_table_1.sh
+145
-0
3rdparty/Megatron-LM/images/cases_april2021.png
3rdparty/Megatron-LM/images/cases_april2021.png
+0
-0
3rdparty/Megatron-LM/megatron/__init__.py
3rdparty/Megatron-LM/megatron/__init__.py
+46
-0
3rdparty/Megatron-LM/megatron/arguments.py
3rdparty/Megatron-LM/megatron/arguments.py
+854
-0
3rdparty/Megatron-LM/megatron/checkpointing.py
3rdparty/Megatron-LM/megatron/checkpointing.py
+490
-0
3rdparty/Megatron-LM/megatron/data/Makefile
3rdparty/Megatron-LM/megatron/data/Makefile
+9
-0
3rdparty/Megatron-LM/megatron/data/__init__.py
3rdparty/Megatron-LM/megatron/data/__init__.py
+1
-0
3rdparty/Megatron-LM/megatron/data/autoaugment.py
3rdparty/Megatron-LM/megatron/data/autoaugment.py
+320
-0
3rdparty/Megatron-LM/megatron/data/bert_dataset.py
3rdparty/Megatron-LM/megatron/data/bert_dataset.py
+195
-0
3rdparty/Megatron-LM/megatron/data/biencoder_dataset_utils.py
...arty/Megatron-LM/megatron/data/biencoder_dataset_utils.py
+208
-0
No files found.
Too many changes to show.
To preserve performance only
260 of 260+
files are displayed.
Plain diff
Email patch
3rdparty/Megatron-LM/examples/sc21/SBATCH.sh
0 → 100644
View file @
0211193c
#!/bin/bash
sbatch
-p
${
SLURM_PARTITION
}
\
-A
${
SLURM_ACCOUNT
}
\
--job-name
=
${
JOB_NAME
}
\
--nodes
=
${
NNODES
}
\
--export
=
MEGATRON_CODE_DIR,MEGATRON_PARAMS,DOCKER_MOUNT_DIR SRUN.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/SRUN.sh
0 → 100644
View file @
0211193c
#!/bin/bash
#SBATCH -t 0:30:00 --exclusive --mem=0 --overcommit --ntasks-per-node=8
THIS_DIR
=
`
pwd
`
DATETIME
=
`
date
+
'date_%y-%m-%d_time_%H-%M-%S'
`
mkdir
-p
${
THIS_DIR
}
/logs
CMD
=
"python -u
${
MEGATRON_CODE_DIR
}
/pretrain_gpt.py
${
MEGATRON_PARAMS
}
"
srun
-l
\
--container-image
"nvcr.io#nvidia/pytorch:20.12-py3"
\
--container-mounts
"
${
THIS_DIR
}
:
${
THIS_DIR
}
,
${
MEGATRON_CODE_DIR
}
:
${
MEGATRON_CODE_DIR
}
,
${
DOCKER_MOUNT_DIR
}
:
${
DOCKER_MOUNT_DIR
}
"
\
--output
=
${
THIS_DIR
}
/logs/%x_%j_
$DATETIME
.log sh
-c
"
${
CMD
}
"
3rdparty/Megatron-LM/examples/sc21/run_figure_11.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Pipeline-parallel size options = [1, 2, 4, 8].
PP
=
1
# Batch size (global batch size) options = [8, 128].
GBS
=
8
# Set pipeline-parallel size options.
NLS
=
$((
3
*
PP
))
NNODES
=
${
PP
}
# Other params.
TP
=
8
MBS
=
1
HS
=
20480
NAH
=
128
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
# Name of the job.
export
JOB_NAME
=
results_figure_11_pipeline_parallel_size_
${
PP
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_12.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Interleaved schedule options = [YES, NO].
INTERLEAVED
=
YES
# Batch size (global batch size) options = [12, 24, 36, ..., 60].
GBS
=
12
# Set interleaved schedule options.
if
[
${
INTERLEAVED
}
==
"YES"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 2 "
elif
[
${
INTERLEAVED
}
==
"NO"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
else
echo
"Invalid configuration"
exit
1
fi
# Other params.
TP
=
8
PP
=
12
MBS
=
1
NLS
=
96
HS
=
12288
NAH
=
96
DDP
=
local
NNODES
=
12
# Name of the job.
export
JOB_NAME
=
results_figure_12_interleaved_
${
INTERLEAVED
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_13.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Pipeline-parallel size options = [2, 4, 8, 16, 32].
PP
=
2
# Batch size (global batch size) options = [32, 128].
GBS
=
32
# Set pipeline-parallel and tensor-parallel size options.
TP
=
$((
64
/
PP
))
# Other params.
MBS
=
1
NLS
=
32
HS
=
20480
NAH
=
128
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
NNODES
=
8
# Name of the job.
export
JOB_NAME
=
results_figure_13_pipeline_parallel_size_
${
PP
}
_tensor_parallel_size_
${
TP
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_14.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Pipeline-parallel size options = [2, 4, 8, 16, 32].
PP
=
2
# Batch size (global batch size) options = [32, 512].
GBS
=
32
# Set pipeline-parallel and data-parallel size options.
DP
=
$((
64
/
PP
))
# Other params.
TP
=
1
MBS
=
1
NLS
=
32
HS
=
3840
NAH
=
32
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
NNODES
=
8
# Name of the job.
export
JOB_NAME
=
results_figure_14_pipeline_parallel_size_
${
PP
}
_data_parallel_size_
${
DP
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_15.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Tensor-parallel size options = [2, 4, 8, 16, 32].
TP
=
2
# Batch size (global batch size) options = [32, 128, 512].
GBS
=
32
# Set tensor-parallel and data-parallel size options.
DP
=
$((
64
/
TP
))
# Other params.
PP
=
1
MBS
=
1
NLS
=
32
HS
=
3840
NAH
=
32
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
NNODES
=
8
# Name of the job.
export
JOB_NAME
=
results_figure_15_tensor_parallel_size_
${
TP
}
_data_parallel_size_
${
DP
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_16.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Microbatch size options = [1, 2, 4, 8].
MBS
=
1
# Batch size (global batch size) options = [128, 512].
GBS
=
128
# Other params.
TP
=
8
PP
=
8
NLS
=
32
HS
=
15360
NAH
=
128
DDP
=
local
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
NNODES
=
8
# Name of the job.
export
JOB_NAME
=
results_figure_16_microbatch_size_
${
MBS
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_17.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Activation recomputation options = [YES, NO].
ACTIVATION_RECOMPUTATION
=
YES
# Batch size (global batch size) options = [1, 2, 4, ..., 256].
GBS
=
1
# Set activation recomputation.
if
[
${
ACTIVATION_RECOMPUTATION
}
==
"YES"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
ACTIVATION_RECOMPUTATION
}
==
"NO"
]
;
then
MEGATRON_EXTRA_PARAMS
=
""
else
echo
"Invalid configuration"
exit
1
fi
# Other params.
TP
=
8
PP
=
16
MBS
=
1
NLS
=
80
HS
=
12288
NAH
=
96
DDP
=
local
NNODES
=
16
# Name of the job.
export
JOB_NAME
=
results_figure_17_activation_recomputation_
${
ACTIVATION_RECOMPUTATION
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/examples/sc21/run_figure_18.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# Scatter-gather communication optimization options = [YES, NO].
SCATTER_GATHER
=
YES
# Batch size (global batch size) options = [12, 24, 36, ..., 60].
GBS
=
12
# Set scatter-gather communication optimization options.
if
[
${
SCATTER_GATHER
}
==
"YES"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 2 "
elif
[
${
SCATTER_GATHER
}
==
"NO"
]
;
then
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 2 --no-scatter-gather-tensors-in-pipeline "
else
echo
"Invalid configuration"
exit
1
fi
# Other params.
TP
=
8
PP
=
12
MBS
=
1
NLS
=
96
HS
=
12288
NAH
=
96
DDP
=
local
NNODES
=
12
# Name of the job.
export
JOB_NAME
=
results_figure_18_scatter_gather_
${
SCATTER_GATHER
}
_batch_size_
${
GBS
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
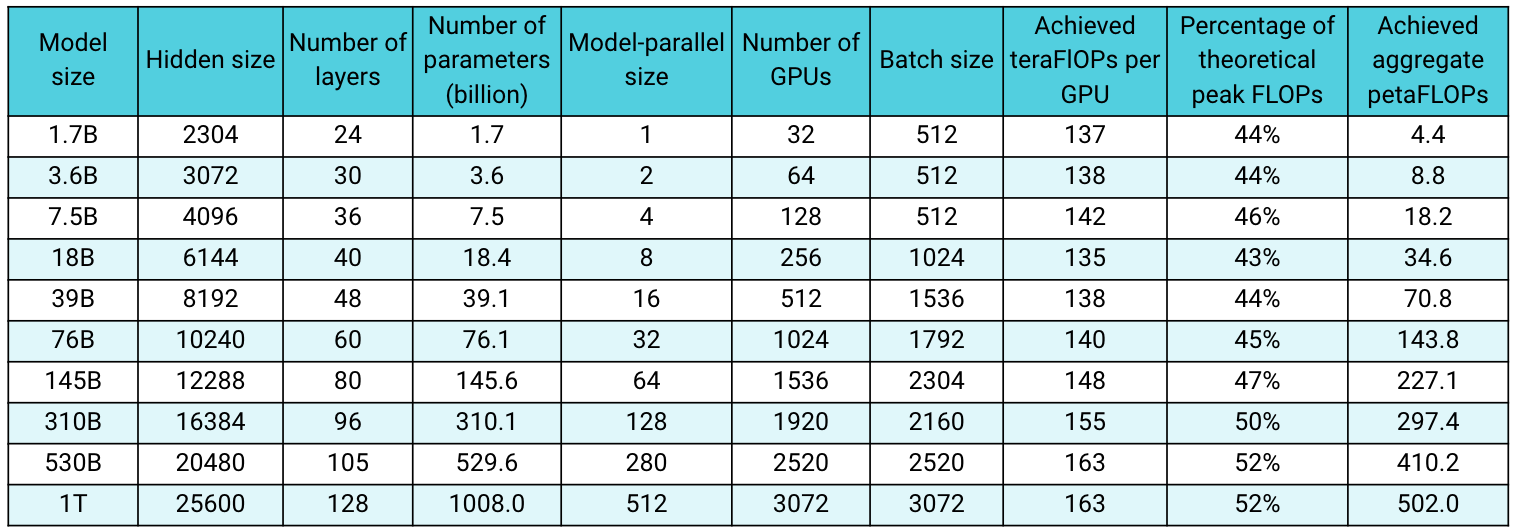
3rdparty/Megatron-LM/examples/sc21/run_table_1.sh
0 → 100644
View file @
0211193c
#!/bin/bash
# ================================
# Choose the case to run.
# ================================
# model size options = [1.7B, 3.6B, 7.5B, 18B, 39B, 76B, 145B, 310B, 530B, 1T]
MODEL_SIZE
=
1.7B
if
[
${
MODEL_SIZE
}
==
"1.7B"
]
;
then
TP
=
1
PP
=
1
MBS
=
16
GBS
=
512
NLS
=
24
HS
=
2304
NAH
=
24
DDP
=
torch
NNODES
=
4
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"3.6B"
]
;
then
TP
=
2
PP
=
1
MBS
=
16
GBS
=
512
NLS
=
30
HS
=
3072
NAH
=
32
DDP
=
torch
NNODES
=
8
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"7.5B"
]
;
then
TP
=
4
PP
=
1
MBS
=
16
GBS
=
512
NLS
=
36
HS
=
4096
NAH
=
32
DDP
=
torch
NNODES
=
16
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"18B"
]
;
then
TP
=
8
PP
=
1
MBS
=
8
GBS
=
1024
NLS
=
40
HS
=
6144
NAH
=
48
DDP
=
torch
NNODES
=
32
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"39B"
]
;
then
TP
=
8
PP
=
2
MBS
=
4
GBS
=
1536
NLS
=
48
HS
=
8192
NAH
=
64
DDP
=
local
NNODES
=
64
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
elif
[
${
MODEL_SIZE
}
==
"76B"
]
;
then
TP
=
8
PP
=
4
MBS
=
2
GBS
=
1792
NLS
=
60
HS
=
10240
NAH
=
80
DDP
=
local
NNODES
=
128
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 5"
elif
[
${
MODEL_SIZE
}
==
"145B"
]
;
then
TP
=
8
PP
=
8
MBS
=
2
GBS
=
2304
NLS
=
80
HS
=
12288
NAH
=
96
DDP
=
local
NNODES
=
192
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 5 "
elif
[
${
MODEL_SIZE
}
==
"310B"
]
;
then
TP
=
8
PP
=
16
MBS
=
1
GBS
=
2160
NLS
=
96
HS
=
16384
NAH
=
128
DDP
=
local
NNODES
=
240
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 3 "
elif
[
${
MODEL_SIZE
}
==
"530B"
]
;
then
TP
=
8
PP
=
35
MBS
=
1
GBS
=
2520
NLS
=
105
HS
=
20480
NAH
=
128
DDP
=
local
NNODES
=
315
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform --num-layers-per-virtual-pipeline-stage 1 "
elif
[
${
MODEL_SIZE
}
==
"1T"
]
;
then
TP
=
8
PP
=
64
MBS
=
1
GBS
=
3072
NLS
=
128
HS
=
25600
NAH
=
160
DDP
=
local
NNODES
=
384
MEGATRON_EXTRA_PARAMS
=
"--activations-checkpoint-method uniform "
else
echo
"Invalid configuration"
exit
1
fi
# Name of the job
export
JOB_NAME
=
results_table_1_model_size_
${
MODEL_SIZE
}
# Import the configs.
.
`
pwd
`
/CONFIG.sh
# Submit the job.
.
`
pwd
`
/SBATCH.sh
exit
0
3rdparty/Megatron-LM/images/cases_april2021.png
0 → 100644
View file @
0211193c
159 KB
3rdparty/Megatron-LM/megatron/__init__.py
0 → 100644
View file @
0211193c
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
torch
from
.global_vars
import
get_args
from
.global_vars
import
get_current_global_batch_size
from
.global_vars
import
get_num_microbatches
from
.global_vars
import
get_signal_handler
from
.global_vars
import
update_num_microbatches
from
.global_vars
import
get_tokenizer
from
.global_vars
import
get_tensorboard_writer
from
.global_vars
import
get_adlr_autoresume
from
.global_vars
import
get_timers
from
.initialize
import
initialize_megatron
def
print_rank_0
(
message
):
"""If distributed is initialized, print only on rank 0."""
if
torch
.
distributed
.
is_initialized
():
if
torch
.
distributed
.
get_rank
()
==
0
:
print
(
message
,
flush
=
True
)
else
:
print
(
message
,
flush
=
True
)
def
is_last_rank
():
return
torch
.
distributed
.
get_rank
()
==
(
torch
.
distributed
.
get_world_size
()
-
1
)
def
print_rank_last
(
message
):
"""If distributed is initialized, print only on last rank."""
if
torch
.
distributed
.
is_initialized
():
if
is_last_rank
():
print
(
message
,
flush
=
True
)
else
:
print
(
message
,
flush
=
True
)
3rdparty/Megatron-LM/megatron/arguments.py
0 → 100644
View file @
0211193c
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Megatron arguments."""
import
argparse
import
os
import
torch
def
parse_args
(
extra_args_provider
=
None
,
defaults
=
{},
ignore_unknown_args
=
False
):
"""Parse all arguments."""
parser
=
argparse
.
ArgumentParser
(
description
=
'Megatron-LM Arguments'
,
allow_abbrev
=
False
)
# Standard arguments.
parser
=
_add_network_size_args
(
parser
)
parser
=
_add_regularization_args
(
parser
)
parser
=
_add_training_args
(
parser
)
parser
=
_add_initialization_args
(
parser
)
parser
=
_add_learning_rate_args
(
parser
)
parser
=
_add_checkpointing_args
(
parser
)
parser
=
_add_mixed_precision_args
(
parser
)
parser
=
_add_distributed_args
(
parser
)
parser
=
_add_validation_args
(
parser
)
parser
=
_add_data_args
(
parser
)
parser
=
_add_autoresume_args
(
parser
)
parser
=
_add_biencoder_args
(
parser
)
parser
=
_add_vit_args
(
parser
)
parser
=
_add_logging_args
(
parser
)
parser
=
_add_inference_args
(
parser
)
# Custom arguments.
if
extra_args_provider
is
not
None
:
parser
=
extra_args_provider
(
parser
)
# Parse.
if
ignore_unknown_args
:
args
,
_
=
parser
.
parse_known_args
()
else
:
args
=
parser
.
parse_args
()
# Distributed args.
args
.
rank
=
int
(
os
.
getenv
(
'RANK'
,
'0'
))
args
.
world_size
=
int
(
os
.
getenv
(
"WORLD_SIZE"
,
'1'
))
# Tensor model parallel size.
args
.
tensor_model_parallel_size
=
min
(
args
.
tensor_model_parallel_size
,
args
.
world_size
)
assert
args
.
world_size
%
args
.
tensor_model_parallel_size
==
0
,
'world size'
\
' ({}) is not divisible by tensor model parallel size ({})'
.
format
(
args
.
world_size
,
args
.
tensor_model_parallel_size
)
# Pipeline model parallel size.
args
.
pipeline_model_parallel_size
=
min
(
args
.
pipeline_model_parallel_size
,
(
args
.
world_size
//
args
.
tensor_model_parallel_size
))
# Checks.
model_parallel_size
=
args
.
pipeline_model_parallel_size
*
\
args
.
tensor_model_parallel_size
assert
args
.
world_size
%
model_parallel_size
==
0
,
'world size is not'
\
' divisible by tensor parallel size ({}) times pipeline parallel '
\
'size ({})'
.
format
(
args
.
world_size
,
args
.
tensor_model_parallel_size
,
args
.
pipeline_model_parallel_size
)
args
.
data_parallel_size
=
args
.
world_size
//
model_parallel_size
if
args
.
rank
==
0
:
print
(
'using world size: {}, data-parallel-size: {}, '
'tensor-model-parallel size: {}, '
'pipeline-model-parallel size: {} '
.
format
(
args
.
world_size
,
args
.
data_parallel_size
,
args
.
tensor_model_parallel_size
,
args
.
pipeline_model_parallel_size
),
flush
=
True
)
if
args
.
pipeline_model_parallel_size
>
1
:
if
args
.
pipeline_model_parallel_split_rank
is
not
None
:
assert
args
.
pipeline_model_parallel_split_rank
<
\
args
.
pipeline_model_parallel_size
,
'split rank needs'
\
' to be less than pipeline model parallel size ({})'
.
format
(
args
.
pipeline_model_parallel_size
)
# Deprecated arguments
assert
args
.
batch_size
is
None
,
'--batch-size argument is no longer '
\
'valid, use --micro-batch-size instead'
del
args
.
batch_size
assert
args
.
warmup
is
None
,
'--warmup argument is no longer valid, use '
\
'--lr-warmup-fraction instead'
del
args
.
warmup
assert
args
.
model_parallel_size
is
None
,
'--model-parallel-size is no '
\
'longer valid, use --tensor-model-parallel-size instead'
del
args
.
model_parallel_size
if
args
.
checkpoint_activations
:
args
.
activations_checkpoint_method
=
'uniform'
if
args
.
rank
==
0
:
print
(
'--checkpoint-activations is no longer valid, '
'use --activation-checkpoint-method instead. '
'Defaulting to activation-checkpoint-method=uniform.'
)
del
args
.
checkpoint_activations
# Set input defaults.
for
key
in
defaults
:
# For default to be valid, it should not be provided in the
# arguments that are passed to the program. We check this by
# ensuring the arg is set to None.
if
getattr
(
args
,
key
)
is
not
None
:
if
args
.
rank
==
0
:
print
(
'WARNING: overriding default arguments for {key}:{v}
\
with {key}:{v2}'
.
format
(
key
=
key
,
v
=
defaults
[
key
],
v2
=
getattr
(
args
,
key
)),
flush
=
True
)
else
:
setattr
(
args
,
key
,
defaults
[
key
])
# Batch size.
assert
args
.
micro_batch_size
is
not
None
assert
args
.
micro_batch_size
>
0
if
args
.
global_batch_size
is
None
:
args
.
global_batch_size
=
args
.
micro_batch_size
*
args
.
data_parallel_size
if
args
.
rank
==
0
:
print
(
'setting global batch size to {}'
.
format
(
args
.
global_batch_size
),
flush
=
True
)
assert
args
.
global_batch_size
>
0
if
args
.
num_layers_per_virtual_pipeline_stage
is
not
None
:
assert
args
.
pipeline_model_parallel_size
>
2
,
\
'pipeline-model-parallel size should be greater than 2 with '
\
'interleaved schedule'
assert
args
.
num_layers
%
args
.
num_layers_per_virtual_pipeline_stage
==
0
,
\
'number of layers is not divisible by number of layers per virtual '
\
'pipeline stage'
args
.
virtual_pipeline_model_parallel_size
=
\
(
args
.
num_layers
//
args
.
pipeline_model_parallel_size
)
//
\
args
.
num_layers_per_virtual_pipeline_stage
else
:
args
.
virtual_pipeline_model_parallel_size
=
None
# Parameters dtype.
args
.
params_dtype
=
torch
.
float
if
args
.
fp16
:
assert
not
args
.
bf16
args
.
params_dtype
=
torch
.
half
if
args
.
bf16
:
assert
not
args
.
fp16
args
.
params_dtype
=
torch
.
bfloat16
# bfloat16 requires gradient accumulation and all-reduce to
# be done in fp32.
if
not
args
.
accumulate_allreduce_grads_in_fp32
:
args
.
accumulate_allreduce_grads_in_fp32
=
True
if
args
.
rank
==
0
:
print
(
'accumulate and all-reduce gradients in fp32 for '
'bfloat16 data type.'
,
flush
=
True
)
if
args
.
rank
==
0
:
print
(
'using {} for parameters ...'
.
format
(
args
.
params_dtype
),
flush
=
True
)
# If we do accumulation and all-reduces in fp32, we need to have local DDP
# and we should make sure use-contiguous-buffers-in-local-ddp is not off.
if
args
.
accumulate_allreduce_grads_in_fp32
:
assert
args
.
DDP_impl
==
'local'
assert
args
.
use_contiguous_buffers_in_local_ddp
# For torch DDP, we do not use contiguous buffer
if
args
.
DDP_impl
==
'torch'
:
args
.
use_contiguous_buffers_in_local_ddp
=
False
if
args
.
dataloader_type
is
None
:
args
.
dataloader_type
=
'single'
# Consumed tokens.
args
.
consumed_train_samples
=
0
args
.
consumed_valid_samples
=
0
# Iteration-based training.
if
args
.
train_iters
:
# If we use iteration-based training, make sure the
# sample-based options are off.
assert
args
.
train_samples
is
None
,
\
'expected iteration-based training'
assert
args
.
lr_decay_samples
is
None
,
\
'expected iteration-based learning rate decay'
assert
args
.
lr_warmup_samples
==
0
,
\
'expected iteration-based learning rate warmup'
assert
args
.
rampup_batch_size
is
None
,
\
'expected no batch-size rampup for iteration-based training'
if
args
.
lr_warmup_fraction
is
not
None
:
assert
args
.
lr_warmup_iters
==
0
,
\
'can only specify one of lr-warmup-fraction and lr-warmup-iters'
# Sample-based training.
if
args
.
train_samples
:
# If we use sample-based training, make sure the
# iteration-based options are off.
assert
args
.
train_iters
is
None
,
\
'expected sample-based training'
assert
args
.
lr_decay_iters
is
None
,
\
'expected sample-based learning rate decay'
assert
args
.
lr_warmup_iters
==
0
,
\
'expected sample-based learnig rate warmup'
if
args
.
lr_warmup_fraction
is
not
None
:
assert
args
.
lr_warmup_samples
==
0
,
\
'can only specify one of lr-warmup-fraction '
\
'and lr-warmup-samples'
# Check required arguments.
required_args
=
[
'num_layers'
,
'hidden_size'
,
'num_attention_heads'
,
'max_position_embeddings'
]
for
req_arg
in
required_args
:
_check_arg_is_not_none
(
args
,
req_arg
)
# Checks.
if
args
.
ffn_hidden_size
is
None
:
args
.
ffn_hidden_size
=
4
*
args
.
hidden_size
if
args
.
kv_channels
is
None
:
assert
args
.
hidden_size
%
args
.
num_attention_heads
==
0
args
.
kv_channels
=
args
.
hidden_size
//
args
.
num_attention_heads
if
args
.
seq_length
is
not
None
:
assert
args
.
encoder_seq_length
is
None
args
.
encoder_seq_length
=
args
.
seq_length
else
:
assert
args
.
encoder_seq_length
is
not
None
args
.
seq_length
=
args
.
encoder_seq_length
if
args
.
seq_length
is
not
None
:
assert
args
.
max_position_embeddings
>=
args
.
seq_length
if
args
.
decoder_seq_length
is
not
None
:
assert
args
.
max_position_embeddings
>=
args
.
decoder_seq_length
if
args
.
lr
is
not
None
:
assert
args
.
min_lr
<=
args
.
lr
if
args
.
save
is
not
None
:
assert
args
.
save_interval
is
not
None
# Mixed precision checks.
if
args
.
fp16_lm_cross_entropy
:
assert
args
.
fp16
,
'lm cross entropy in fp16 only support in fp16 mode.'
if
args
.
fp32_residual_connection
:
assert
args
.
fp16
or
args
.
bf16
,
\
'residual connection in fp32 only supported when using fp16 or bf16.'
TORCH_MAJOR
=
int
(
torch
.
__version__
.
split
(
'.'
)[
0
])
TORCH_MINOR
=
int
(
torch
.
__version__
.
split
(
'.'
)[
1
])
# Persistent fused layer norm.
if
TORCH_MAJOR
<
1
or
(
TORCH_MAJOR
==
1
and
TORCH_MINOR
<
11
):
args
.
no_persist_layer_norm
=
True
if
args
.
rank
==
0
:
print
(
'Persistent fused layer norm kernel is supported from '
'pytorch v1.11 (nvidia pytorch container paired with v1.11). '
'Defaulting to no_persist_layer_norm=True'
)
# Activation checkpointing.
if
args
.
distribute_checkpointed_activations
:
assert
args
.
tensor_model_parallel_size
>
1
,
'can distribute '
\
'checkpointed activations only across tensor model '
\
'parallel groups'
assert
args
.
activations_checkpoint_method
is
not
None
,
\
'for distributed checkpoint activations to work you '
\
'need to use a activation-checkpoint method '
assert
TORCH_MAJOR
>=
1
and
TORCH_MINOR
>=
10
,
\
'distributed checkpoint activations are supported for pytorch '
\
'v1.10 and above (Nvidia Pytorch container >= 21.07). Current '
\
'pytorch version is v%s.%s.'
%
(
TORCH_MAJOR
,
TORCH_MINOR
)
_print_args
(
args
)
return
args
def
_print_args
(
args
):
"""Print arguments."""
if
args
.
rank
==
0
:
print
(
'------------------------ arguments ------------------------'
,
flush
=
True
)
str_list
=
[]
for
arg
in
vars
(
args
):
dots
=
'.'
*
(
48
-
len
(
arg
))
str_list
.
append
(
' {} {} {}'
.
format
(
arg
,
dots
,
getattr
(
args
,
arg
)))
for
arg
in
sorted
(
str_list
,
key
=
lambda
x
:
x
.
lower
()):
print
(
arg
,
flush
=
True
)
print
(
'-------------------- end of arguments ---------------------'
,
flush
=
True
)
def
_check_arg_is_not_none
(
args
,
arg
):
assert
getattr
(
args
,
arg
)
is
not
None
,
'{} argument is None'
.
format
(
arg
)
def
_add_inference_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'inference'
)
group
.
add_argument
(
'--inference-batch-times-seqlen-threshold'
,
type
=
int
,
default
=
512
,
help
=
'During inference, if batch-size times '
'sequence-length is smaller than this threshold '
'then we will not use pipelining, otherwise we will.'
)
return
parser
def
_add_network_size_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'network size'
)
group
.
add_argument
(
'--num-layers'
,
type
=
int
,
default
=
None
,
help
=
'Number of transformer layers.'
)
group
.
add_argument
(
'--hidden-size'
,
type
=
int
,
default
=
None
,
help
=
'Tansformer hidden size.'
)
group
.
add_argument
(
'--ffn-hidden-size'
,
type
=
int
,
default
=
None
,
help
=
'Transformer Feed-Forward Network hidden size. '
'This is set to 4*hidden-size if not provided'
)
group
.
add_argument
(
'--num-attention-heads'
,
type
=
int
,
default
=
None
,
help
=
'Number of transformer attention heads.'
)
group
.
add_argument
(
'--kv-channels'
,
type
=
int
,
default
=
None
,
help
=
'Projection weights dimension in multi-head '
'attention. This is set to '
' args.hidden_size // args.num_attention_heads '
'if not provided.'
)
group
.
add_argument
(
'--max-position-embeddings'
,
type
=
int
,
default
=
None
,
help
=
'Maximum number of position embeddings to use. '
'This is the size of position embedding.'
)
group
.
add_argument
(
'--make-vocab-size-divisible-by'
,
type
=
int
,
default
=
128
,
help
=
'Pad the vocab size to be divisible by this value.'
'This is added for computational efficieny reasons.'
)
group
.
add_argument
(
'--layernorm-epsilon'
,
type
=
float
,
default
=
1e-5
,
help
=
'Layer norm epsilon.'
)
group
.
add_argument
(
'--apply-residual-connection-post-layernorm'
,
action
=
'store_true'
,
help
=
'If set, use original BERT residula connection '
'ordering.'
)
group
.
add_argument
(
'--openai-gelu'
,
action
=
'store_true'
,
help
=
'Use OpenAIs GeLU implementation. This option'
'should not be used unless for backward compatibility'
'reasons.'
)
group
.
add_argument
(
'--onnx-safe'
,
type
=
bool
,
required
=
False
,
help
=
'Use workarounds for known problems with '
'Torch ONNX exporter'
)
group
.
add_argument
(
'--bert-no-binary-head'
,
action
=
'store_false'
,
help
=
'Disable BERT binary head.'
,
dest
=
'bert_binary_head'
)
return
parser
def
_add_logging_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'logging'
)
group
.
add_argument
(
'--log-params-norm'
,
action
=
'store_true'
,
help
=
'If set, calculate and log parameters norm.'
)
group
.
add_argument
(
'--log-num-zeros-in-grad'
,
action
=
'store_true'
,
help
=
'If set, calculate and log the number of zeros in gradient.'
)
group
.
add_argument
(
'--tensorboard-log-interval'
,
type
=
int
,
default
=
1
,
help
=
'Report to tensorboard interval.'
)
group
.
add_argument
(
'--tensorboard-queue-size'
,
type
=
int
,
default
=
1000
,
help
=
'Size of the tensorboard queue for pending events '
'and summaries before one of the ‘add’ calls forces a '
'flush to disk.'
)
group
.
add_argument
(
'--log-timers-to-tensorboard'
,
action
=
'store_true'
,
help
=
'If set, write timers to tensorboard.'
)
group
.
add_argument
(
'--log-batch-size-to-tensorboard'
,
action
=
'store_true'
,
help
=
'If set, write batch-size to tensorboard.'
)
group
.
add_argument
(
'--no-log-learnig-rate-to-tensorboard'
,
action
=
'store_false'
,
help
=
'Disable learning rate logging to tensorboard.'
,
dest
=
'log_learning_rate_to_tensorboard'
)
group
.
add_argument
(
'--no-log-loss-scale-to-tensorboard'
,
action
=
'store_false'
,
help
=
'Disable loss-scale logging to tensorboard.'
,
dest
=
'log_loss_scale_to_tensorboard'
)
group
.
add_argument
(
'--log-validation-ppl-to-tensorboard'
,
action
=
'store_true'
,
help
=
'If set, write validation perplexity to '
'tensorboard.'
)
group
.
add_argument
(
'--log-memory-to-tensorboard'
,
action
=
'store_true'
,
help
=
'Enable memory logging to tensorboard.'
)
group
.
add_argument
(
'--log-world-size-to-tensorboard'
,
action
=
'store_true'
,
help
=
'Enable world size logging to tensorboard.'
)
return
parser
def
_add_regularization_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'regularization'
)
group
.
add_argument
(
'--attention-dropout'
,
type
=
float
,
default
=
0.1
,
help
=
'Post attention dropout probability.'
)
group
.
add_argument
(
'--hidden-dropout'
,
type
=
float
,
default
=
0.1
,
help
=
'Dropout probability for hidden state transformer.'
)
group
.
add_argument
(
'--weight-decay'
,
type
=
float
,
default
=
0.01
,
help
=
'Weight decay coefficient for L2 regularization.'
)
group
.
add_argument
(
'--clip-grad'
,
type
=
float
,
default
=
1.0
,
help
=
'Gradient clipping based on global L2 norm.'
)
group
.
add_argument
(
'--adam-beta1'
,
type
=
float
,
default
=
0.9
,
help
=
'First coefficient for computing running averages '
'of gradient and its square'
)
group
.
add_argument
(
'--adam-beta2'
,
type
=
float
,
default
=
0.999
,
help
=
'Second coefficient for computing running averages '
'of gradient and its square'
)
group
.
add_argument
(
'--adam-eps'
,
type
=
float
,
default
=
1e-08
,
help
=
'Term added to the denominator to improve'
'numerical stability'
)
group
.
add_argument
(
'--sgd-momentum'
,
type
=
float
,
default
=
0.9
,
help
=
'Momentum factor for sgd'
)
return
parser
def
_add_training_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'training'
)
group
.
add_argument
(
'--micro-batch-size'
,
type
=
int
,
default
=
None
,
help
=
'Batch size per model instance (local batch size). '
'Global batch size is local batch size times data '
'parallel size times number of micro batches.'
)
group
.
add_argument
(
'--batch-size'
,
type
=
int
,
default
=
None
,
help
=
'Old batch size parameter, do not use. '
'Use --micro-batch-size instead'
)
group
.
add_argument
(
'--global-batch-size'
,
type
=
int
,
default
=
None
,
help
=
'Training batch size. If set, it should be a '
'multiple of micro-batch-size times data-parallel-size. '
'If this value is None, then '
'use micro-batch-size * data-parallel-size as the '
'global batch size. This choice will result in 1 for '
'number of micro-batches.'
)
group
.
add_argument
(
'--rampup-batch-size'
,
nargs
=
'*'
,
default
=
None
,
help
=
'Batch size ramp up with the following values:'
' --rampup-batch-size <start batch size> '
' <batch size incerement> '
' <ramp-up samples> '
'For example:'
' --rampup-batch-size 16 8 300000 \ '
' --global-batch-size 1024'
'will start with global batch size 16 and over '
' (1024 - 16) / 8 = 126 intervals will increase'
'the batch size linearly to 1024. In each interval'
'we will use approximately 300000 / 126 = 2380 samples.'
)
group
.
add_argument
(
'--checkpoint-activations'
,
action
=
'store_true'
,
help
=
'Checkpoint activation to allow for training '
'with larger models, sequences, and batch sizes.'
)
group
.
add_argument
(
'--distribute-checkpointed-activations'
,
action
=
'store_true'
,
help
=
'If set, distribute checkpointed activations '
'across model parallel group.'
)
group
.
add_argument
(
'--activations-checkpoint-method'
,
type
=
str
,
default
=
None
,
choices
=
[
'uniform'
,
'block'
],
help
=
'1) uniform: uniformly divide the total number of '
'Transformer layers and checkpoint the input activation of '
'each divided chunk, '
'2) checkpoint the input activations of only a set number of '
'individual Transformer layers per pipeline stage and do the '
'rest without any checkpointing'
'default) do not apply activations checkpoint to any layers'
)
group
.
add_argument
(
'--activations-checkpoint-num-layers'
,
type
=
int
,
default
=
1
,
help
=
'1) uniform: the number of Transformer layers in each '
'uniformly divided checkpoint unit, '
'2) block: the number of individual Transformer layers '
'to checkpoint within each pipeline stage.'
)
group
.
add_argument
(
'--train-iters'
,
type
=
int
,
default
=
None
,
help
=
'Total number of iterations to train over all '
'training runs. Note that either train-iters or '
'train-samples should be provided.'
)
group
.
add_argument
(
'--train-samples'
,
type
=
int
,
default
=
None
,
help
=
'Total number of samples to train over all '
'training runs. Note that either train-iters or '
'train-samples should be provided.'
)
group
.
add_argument
(
'--log-interval'
,
type
=
int
,
default
=
100
,
help
=
'Report loss and timing interval.'
)
group
.
add_argument
(
'--exit-interval'
,
type
=
int
,
default
=
None
,
help
=
'Exit the program after the iteration is divisible '
'by this value.'
)
group
.
add_argument
(
'--exit-duration-in-mins'
,
type
=
int
,
default
=
None
,
help
=
'Exit the program after this many minutes.'
)
group
.
add_argument
(
'--exit-signal-handler'
,
action
=
'store_true'
,
help
=
'Dynamically save the checkpoint and shutdown the '
'training if SIGTERM is received'
)
group
.
add_argument
(
'--tensorboard-dir'
,
type
=
str
,
default
=
None
,
help
=
'Write TensorBoard logs to this directory.'
)
group
.
add_argument
(
'--no-masked-softmax-fusion'
,
action
=
'store_false'
,
help
=
'Disable fusion of query_key_value scaling, '
'masking, and softmax.'
,
dest
=
'masked_softmax_fusion'
)
group
.
add_argument
(
'--no-bias-gelu-fusion'
,
action
=
'store_false'
,
help
=
'Disable bias and gelu fusion.'
,
dest
=
'bias_gelu_fusion'
)
group
.
add_argument
(
'--no-bias-dropout-fusion'
,
action
=
'store_false'
,
help
=
'Disable bias and dropout fusion.'
,
dest
=
'bias_dropout_fusion'
)
group
.
add_argument
(
'--optimizer'
,
type
=
str
,
default
=
'adam'
,
choices
=
[
'adam'
,
'sgd'
],
help
=
'Optimizer function'
)
group
.
add_argument
(
'--dataloader-type'
,
type
=
str
,
default
=
None
,
choices
=
[
'single'
,
'cyclic'
],
help
=
'Single pass vs multiple pass data loader'
)
group
.
add_argument
(
'--no-async-tensor-model-parallel-allreduce'
,
action
=
'store_true'
,
help
=
'Disable asynchronous execution of '
'tensor-model-parallel all-reduce with weight '
'gradient compuation of a column-linear layer.'
)
group
.
add_argument
(
'--no-persist-layer-norm'
,
action
=
'store_true'
,
help
=
'Disable using persistent fused layer norm kernel. '
'This kernel supports only a set of hidden sizes. Please '
'check persist_ln_hidden_sizes if your hidden '
'size is supported.'
)
return
parser
def
_add_initialization_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'initialization'
)
group
.
add_argument
(
'--seed'
,
type
=
int
,
default
=
1234
,
help
=
'Random seed used for python, numpy, '
'pytorch, and cuda.'
)
group
.
add_argument
(
'--data-parallel-random-init'
,
action
=
'store_true'
,
help
=
'Enable random initialization of params '
'across data parallel ranks'
)
group
.
add_argument
(
'--init-method-std'
,
type
=
float
,
default
=
0.02
,
help
=
'Standard deviation of the zero mean normal '
'distribution used for weight initialization.'
)
group
.
add_argument
(
'--init-method-xavier-uniform'
,
action
=
'store_true'
,
help
=
'Enable Xavier uniform parameter initialization'
)
return
parser
def
_add_learning_rate_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'learning rate'
)
group
.
add_argument
(
'--lr'
,
type
=
float
,
default
=
None
,
help
=
'Initial learning rate. Depending on decay style '
'and initial warmup, the learing rate at each '
'iteration would be different.'
)
group
.
add_argument
(
'--lr-decay-style'
,
type
=
str
,
default
=
'linear'
,
choices
=
[
'constant'
,
'linear'
,
'cosine'
],
help
=
'Learning rate decay function.'
)
group
.
add_argument
(
'--lr-decay-iters'
,
type
=
int
,
default
=
None
,
help
=
'number of iterations to decay learning rate over,'
' If None defaults to `--train-iters`'
)
group
.
add_argument
(
'--lr-decay-samples'
,
type
=
int
,
default
=
None
,
help
=
'number of samples to decay learning rate over,'
' If None defaults to `--train-samples`'
)
group
.
add_argument
(
'--lr-warmup-fraction'
,
type
=
float
,
default
=
None
,
help
=
'fraction of lr-warmup-(iters/samples) to use '
'for warmup (as a float)'
)
group
.
add_argument
(
'--lr-warmup-iters'
,
type
=
int
,
default
=
0
,
help
=
'number of iterations to linearly warmup '
'learning rate over.'
)
group
.
add_argument
(
'--lr-warmup-samples'
,
type
=
int
,
default
=
0
,
help
=
'number of samples to linearly warmup '
'learning rate over.'
)
group
.
add_argument
(
'--warmup'
,
type
=
int
,
default
=
None
,
help
=
'Old lr warmup argument, do not use. Use one of the'
'--lr-warmup-* arguments above'
)
group
.
add_argument
(
'--min-lr'
,
type
=
float
,
default
=
0.0
,
help
=
'Minumum value for learning rate. The scheduler'
'clip values below this threshold.'
)
group
.
add_argument
(
'--override-lr-scheduler'
,
action
=
'store_true'
,
help
=
'Reset the values of the scheduler (learning rate,'
'warmup iterations, minimum learning rate, maximum '
'number of iterations, and decay style from input '
'arguments and ignore values from checkpoints. Note'
'that all the above values will be reset.'
)
group
.
add_argument
(
'--use-checkpoint-lr-scheduler'
,
action
=
'store_true'
,
help
=
'Use checkpoint to set the values of the scheduler '
'(learning rate, warmup iterations, minimum learning '
'rate, maximum number of iterations, and decay style '
'from checkpoint and ignore input arguments.'
)
return
parser
def
_add_checkpointing_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'checkpointing'
)
group
.
add_argument
(
'--save'
,
type
=
str
,
default
=
None
,
help
=
'Output directory to save checkpoints to.'
)
group
.
add_argument
(
'--save-interval'
,
type
=
int
,
default
=
None
,
help
=
'Number of iterations between checkpoint saves.'
)
group
.
add_argument
(
'--no-save-optim'
,
action
=
'store_true'
,
default
=
None
,
help
=
'Do not save current optimizer.'
)
group
.
add_argument
(
'--no-save-rng'
,
action
=
'store_true'
,
default
=
None
,
help
=
'Do not save current rng state.'
)
group
.
add_argument
(
'--load'
,
type
=
str
,
default
=
None
,
help
=
'Directory containing a model checkpoint.'
)
group
.
add_argument
(
'--no-load-optim'
,
action
=
'store_true'
,
default
=
None
,
help
=
'Do not load optimizer when loading checkpoint.'
)
group
.
add_argument
(
'--no-load-rng'
,
action
=
'store_true'
,
default
=
None
,
help
=
'Do not load rng state when loading checkpoint.'
)
group
.
add_argument
(
'--finetune'
,
action
=
'store_true'
,
help
=
'Load model for finetuning. Do not load optimizer '
'or rng state from checkpoint and set iteration to 0. '
'Assumed when loading a release checkpoint.'
)
return
parser
def
_add_mixed_precision_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'mixed precision'
)
group
.
add_argument
(
'--fp16'
,
action
=
'store_true'
,
help
=
'Run model in fp16 mode.'
)
group
.
add_argument
(
'--bf16'
,
action
=
'store_true'
,
help
=
'Run model in bfloat16 mode.'
)
group
.
add_argument
(
'--loss-scale'
,
type
=
float
,
default
=
None
,
help
=
'Static loss scaling, positive power of 2 '
'values can improve fp16 convergence. If None, dynamic'
'loss scaling is used.'
)
group
.
add_argument
(
'--initial-loss-scale'
,
type
=
float
,
default
=
2
**
32
,
help
=
'Initial loss-scale for dynamic loss scaling.'
)
group
.
add_argument
(
'--min-loss-scale'
,
type
=
float
,
default
=
1.0
,
help
=
'Minimum loss scale for dynamic loss scale.'
)
group
.
add_argument
(
'--loss-scale-window'
,
type
=
float
,
default
=
1000
,
help
=
'Window over which to raise/lower dynamic scale.'
)
group
.
add_argument
(
'--hysteresis'
,
type
=
int
,
default
=
2
,
help
=
'hysteresis for dynamic loss scaling'
)
group
.
add_argument
(
'--fp32-residual-connection'
,
action
=
'store_true'
,
help
=
'Move residual connections to fp32.'
)
group
.
add_argument
(
'--no-query-key-layer-scaling'
,
action
=
'store_false'
,
help
=
'Do not scale Q * K^T by 1 / layer-number.'
,
dest
=
'apply_query_key_layer_scaling'
)
group
.
add_argument
(
'--attention-softmax-in-fp32'
,
action
=
'store_true'
,
help
=
'Run attention masking and softmax in fp32. '
'This flag is ignored unless '
'--no-query-key-layer-scaling is specified.'
)
group
.
add_argument
(
'--accumulate-allreduce-grads-in-fp32'
,
action
=
'store_true'
,
help
=
'Gradient accumulation and all-reduce in fp32.'
)
group
.
add_argument
(
'--fp16-lm-cross-entropy'
,
action
=
'store_true'
,
help
=
'Move the cross entropy unreduced loss calculation'
'for lm head to fp16.'
)
return
parser
def
_add_distributed_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'distributed'
)
group
.
add_argument
(
'--tensor-model-parallel-size'
,
type
=
int
,
default
=
1
,
help
=
'Degree of tensor model parallelism.'
)
group
.
add_argument
(
'--pipeline-model-parallel-size'
,
type
=
int
,
default
=
1
,
help
=
'Degree of pipeline model parallelism.'
)
group
.
add_argument
(
'--pipeline-model-parallel-split-rank'
,
type
=
int
,
default
=
None
,
help
=
'Rank where encoder and decoder should be split.'
)
group
.
add_argument
(
'--model-parallel-size'
,
type
=
int
,
default
=
None
,
help
=
'Old model parallel argument, do not use. Use '
'--tensor-model-parallel-size instead.'
)
group
.
add_argument
(
'--num-layers-per-virtual-pipeline-stage'
,
type
=
int
,
default
=
None
,
help
=
'Number of layers per virtual pipeline stage'
)
group
.
add_argument
(
'--distributed-backend'
,
default
=
'nccl'
,
choices
=
[
'nccl'
,
'gloo'
],
help
=
'Which backend to use for distributed training.'
)
group
.
add_argument
(
'--DDP-impl'
,
default
=
'local'
,
choices
=
[
'local'
,
'torch'
],
help
=
'which DistributedDataParallel implementation '
'to use.'
)
group
.
add_argument
(
'--no-contiguous-buffers-in-local-ddp'
,
action
=
'store_false'
,
help
=
'If set, dont use '
'contiguous buffer in local DDP.'
,
dest
=
'use_contiguous_buffers_in_local_ddp'
)
group
.
add_argument
(
'--no-scatter-gather-tensors-in-pipeline'
,
action
=
'store_false'
,
help
=
'Use scatter/gather to optimize communication of tensors in pipeline'
,
dest
=
'scatter_gather_tensors_in_pipeline'
)
group
.
add_argument
(
'--local_rank'
,
type
=
int
,
default
=
None
,
help
=
'local rank passed from distributed launcher.'
)
group
.
add_argument
(
'--lazy-mpu-init'
,
type
=
bool
,
required
=
False
,
help
=
'If set to True, initialize_megatron() '
'skips DDP initialization and returns function to '
'complete it instead.Also turns on '
'--use-cpu-initialization flag. This is for '
'external DDP manager.'
)
group
.
add_argument
(
'--use-cpu-initialization'
,
action
=
'store_true'
,
default
=
None
,
help
=
'If set, affine parallel weights '
'initialization uses CPU'
)
group
.
add_argument
(
'--empty-unused-memory-level'
,
default
=
0
,
type
=
int
,
choices
=
[
0
,
1
,
2
],
help
=
'Call torch.cuda.empty_cache() each iteration '
'(training and eval), to reduce fragmentation.'
'0=off, 1=moderate, 2=aggressive.'
)
return
parser
def
_add_validation_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'validation'
)
group
.
add_argument
(
'--eval-iters'
,
type
=
int
,
default
=
100
,
help
=
'Number of iterations to run for evaluation'
'validation/test for.'
)
group
.
add_argument
(
'--eval-interval'
,
type
=
int
,
default
=
1000
,
help
=
'Interval between running evaluation on '
'validation set.'
)
return
parser
def
_add_data_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'data and dataloader'
)
group
.
add_argument
(
'--data-path'
,
nargs
=
'*'
,
default
=
None
,
help
=
'Path to the training dataset. Accepted format:'
'1) a single data path, 2) multiple datasets in the'
'form: dataset1-weight dataset1-path dataset2-weight '
'dataset2-path ...'
)
group
.
add_argument
(
'--split'
,
type
=
str
,
default
=
'969, 30, 1'
,
help
=
'Comma-separated list of proportions for training,'
' validation, and test split. For example the split '
'`90,5,5` will use 90%% of data for training, 5%% for '
'validation and 5%% for test.'
)
group
.
add_argument
(
'--vocab-file'
,
type
=
str
,
default
=
None
,
help
=
'Path to the vocab file.'
)
group
.
add_argument
(
'--merge-file'
,
type
=
str
,
default
=
None
,
help
=
'Path to the BPE merge file.'
)
group
.
add_argument
(
'--vocab-extra-ids'
,
type
=
int
,
default
=
0
,
help
=
'Number of additional vocabulary tokens. '
'They are used for span masking in the T5 model'
)
group
.
add_argument
(
'--seq-length'
,
type
=
int
,
default
=
None
,
help
=
'Maximum sequence length to process.'
)
group
.
add_argument
(
'--encoder-seq-length'
,
type
=
int
,
default
=
None
,
help
=
'Maximum encoder sequence length to process.'
'This should be exclusive of --seq-length'
)
group
.
add_argument
(
'--decoder-seq-length'
,
type
=
int
,
default
=
None
,
help
=
"Maximum decoder sequence length to process."
)
group
.
add_argument
(
'--retriever-seq-length'
,
type
=
int
,
default
=
256
,
help
=
'Maximum sequence length for the biencoder model '
' for retriever'
)
group
.
add_argument
(
'--sample-rate'
,
type
=
float
,
default
=
1.0
,
help
=
'sample rate for training data. Supposed to be 0 '
' < sample_rate < 1'
)
group
.
add_argument
(
'--mask-prob'
,
type
=
float
,
default
=
0.15
,
help
=
'Probability of replacing a token with mask.'
)
group
.
add_argument
(
'--short-seq-prob'
,
type
=
float
,
default
=
0.1
,
help
=
'Probability of producing a short sequence.'
)
group
.
add_argument
(
'--mmap-warmup'
,
action
=
'store_true'
,
help
=
'Warm up mmap files.'
)
group
.
add_argument
(
'--num-workers'
,
type
=
int
,
default
=
2
,
help
=
"Dataloader number of workers."
)
group
.
add_argument
(
'--tokenizer-type'
,
type
=
str
,
default
=
None
,
choices
=
[
'BertWordPieceLowerCase'
,
'BertWordPieceCase'
,
'GPT2BPETokenizer'
],
help
=
'What type of tokenizer to use.'
)
group
.
add_argument
(
'--data-impl'
,
type
=
str
,
default
=
'infer'
,
choices
=
[
'lazy'
,
'cached'
,
'mmap'
,
'infer'
],
help
=
'Implementation of indexed datasets.'
)
group
.
add_argument
(
'--reset-position-ids'
,
action
=
'store_true'
,
help
=
'Reset posistion ids after end-of-document token.'
)
group
.
add_argument
(
'--reset-attention-mask'
,
action
=
'store_true'
,
help
=
'Reset self attention maske after '
'end-of-document token.'
)
group
.
add_argument
(
'--eod-mask-loss'
,
action
=
'store_true'
,
help
=
'Mask loss for the end of document tokens.'
)
return
parser
def
_add_autoresume_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'autoresume'
)
group
.
add_argument
(
'--adlr-autoresume'
,
action
=
'store_true'
,
help
=
'Enable autoresume on adlr cluster.'
)
group
.
add_argument
(
'--adlr-autoresume-interval'
,
type
=
int
,
default
=
1000
,
help
=
'Intervals over which check for autoresume'
'termination signal'
)
return
parser
def
_add_biencoder_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'biencoder'
)
# network size
group
.
add_argument
(
'--ict-head-size'
,
type
=
int
,
default
=
None
,
help
=
'Size of block embeddings to be used in ICT and '
'REALM (paper default: 128)'
)
group
.
add_argument
(
'--biencoder-projection-dim'
,
type
=
int
,
default
=
0
,
help
=
'Size of projection head used in biencoder (paper'
' default: 128)'
)
group
.
add_argument
(
'--biencoder-shared-query-context-model'
,
action
=
'store_true'
,
help
=
'Whether to share the parameters of the query '
'and context models or not'
)
# checkpointing
group
.
add_argument
(
'--ict-load'
,
type
=
str
,
default
=
None
,
help
=
'Directory containing an ICTBertModel checkpoint'
)
group
.
add_argument
(
'--bert-load'
,
type
=
str
,
default
=
None
,
help
=
'Directory containing an BertModel checkpoint '
'(needed to start ICT and REALM)'
)
# data
group
.
add_argument
(
'--titles-data-path'
,
type
=
str
,
default
=
None
,
help
=
'Path to titles dataset used for ICT'
)
group
.
add_argument
(
'--query-in-block-prob'
,
type
=
float
,
default
=
0.1
,
help
=
'Probability of keeping query in block for '
'ICT dataset'
)
group
.
add_argument
(
'--use-one-sent-docs'
,
action
=
'store_true'
,
help
=
'Whether to use one sentence documents in ICT'
)
group
.
add_argument
(
'--evidence-data-path'
,
type
=
str
,
default
=
None
,
help
=
'Path to Wikipedia Evidence frm DPR paper'
)
# training
group
.
add_argument
(
'--retriever-report-topk-accuracies'
,
nargs
=
'+'
,
type
=
int
,
default
=
[],
help
=
"Which top-k accuracies to report "
"(e.g. '1 5 20')"
)
group
.
add_argument
(
'--retriever-score-scaling'
,
action
=
'store_true'
,
help
=
'Whether to scale retriever scores by inverse '
'square root of hidden size'
)
# faiss index
group
.
add_argument
(
'--block-data-path'
,
type
=
str
,
default
=
None
,
help
=
'Where to save/load BlockData to/from'
)
group
.
add_argument
(
'--embedding-path'
,
type
=
str
,
default
=
None
,
help
=
'Where to save/load Open-Retrieval Embedding'
' data to/from'
)
# indexer
group
.
add_argument
(
'--indexer-batch-size'
,
type
=
int
,
default
=
128
,
help
=
'How large of batches to use when doing indexing '
'jobs'
)
group
.
add_argument
(
'--indexer-log-interval'
,
type
=
int
,
default
=
1000
,
help
=
'After how many batches should the indexer '
'report progress'
)
return
parser
def
_add_vit_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
"vit"
)
group
.
add_argument
(
'--num-classes'
,
type
=
int
,
default
=
1000
,
help
=
'num of classes in vision classificaiton task'
)
group
.
add_argument
(
'--img-h'
,
type
=
int
,
default
=
224
,
help
=
'Image height for vision classification task'
)
group
.
add_argument
(
'--img-w'
,
type
=
int
,
default
=
224
,
help
=
'Image height for vision classification task'
)
group
.
add_argument
(
'--num-channels'
,
type
=
int
,
default
=
3
,
help
=
'Number of channels in input image data'
)
group
.
add_argument
(
'--patch-dim'
,
type
=
int
,
default
=
16
,
help
=
'patch dimension used in vit'
)
group
.
add_argument
(
'--classes-fraction'
,
type
=
float
,
default
=
1.0
,
help
=
'training with fraction of classes.'
)
group
.
add_argument
(
'--data-per-class-fraction'
,
type
=
float
,
default
=
1.0
,
help
=
'training with fraction of data per class.'
)
group
.
add_argument
(
'--no-data-sharding'
,
action
=
'store_false'
,
help
=
'Disable data sharding.'
,
dest
=
'data_sharding'
)
return
parser
3rdparty/Megatron-LM/megatron/checkpointing.py
0 → 100644
View file @
0211193c
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Input/output checkpointing."""
import
os
import
random
import
sys
import
numpy
as
np
import
torch
from
megatron
import
(
get_args
,
mpu
,
print_rank_0
,
update_num_microbatches
,
utils
)
_CHECKPOINT_VERSION
=
None
def
set_checkpoint_version
(
value
):
global
_CHECKPOINT_VERSION
if
_CHECKPOINT_VERSION
is
not
None
:
assert
_CHECKPOINT_VERSION
==
value
,
\
"checkpoint versions do not match"
_CHECKPOINT_VERSION
=
value
def
get_checkpoint_version
():
global
_CHECKPOINT_VERSION
return
_CHECKPOINT_VERSION
def
check_checkpoint_args
(
checkpoint_args
):
"""Ensure fixed arguments for a model are the same for the input
arguments and the one retrieved from checkpoint."""
args
=
get_args
()
def
_compare
(
arg_name
,
old_arg_name
=
None
):
if
old_arg_name
is
not
None
:
checkpoint_value
=
getattr
(
checkpoint_args
,
old_arg_name
)
else
:
checkpoint_value
=
getattr
(
checkpoint_args
,
arg_name
)
args_value
=
getattr
(
args
,
arg_name
)
error_message
=
'{} value from checkpoint ({}) is not equal to the '
\
'input argument value ({}).'
.
format
(
arg_name
,
checkpoint_value
,
args_value
)
assert
checkpoint_value
==
args_value
,
error_message
_compare
(
'num_layers'
)
_compare
(
'hidden_size'
)
_compare
(
'num_attention_heads'
)
if
args
.
vocab_file
:
_compare
(
'max_position_embeddings'
)
_compare
(
'make_vocab_size_divisible_by'
)
_compare
(
'padded_vocab_size'
)
_compare
(
'tokenizer_type'
)
if
args
.
data_parallel_random_init
:
_compare
(
'data_parallel_random_init'
)
if
get_checkpoint_version
()
<
3.0
:
_compare
(
'tensor_model_parallel_size'
,
old_arg_name
=
'model_parallel_size'
)
if
get_checkpoint_version
()
>=
3.0
:
_compare
(
'tensor_model_parallel_size'
)
_compare
(
'pipeline_model_parallel_size'
)
def
ensure_directory_exists
(
filename
):
"""Build filename's path if it does not already exists."""
dirname
=
os
.
path
.
dirname
(
filename
)
if
not
os
.
path
.
exists
(
dirname
):
os
.
makedirs
(
dirname
)
def
get_checkpoint_name
(
checkpoints_path
,
iteration
,
release
=
False
):
"""A unified checkpoint name."""
if
release
:
directory
=
'release'
else
:
directory
=
'iter_{:07d}'
.
format
(
iteration
)
# Use both the tensor and pipeline MP rank.
if
mpu
.
get_pipeline_model_parallel_world_size
()
==
1
:
return
os
.
path
.
join
(
checkpoints_path
,
directory
,
'mp_rank_{:02d}'
.
format
(
mpu
.
get_tensor_model_parallel_rank
()),
'model_optim_rng.pt'
)
return
os
.
path
.
join
(
checkpoints_path
,
directory
,
'mp_rank_{:02d}_{:03d}'
.
format
(
mpu
.
get_tensor_model_parallel_rank
(),
mpu
.
get_pipeline_model_parallel_rank
()),
'model_optim_rng.pt'
)
def
get_checkpoint_tracker_filename
(
checkpoints_path
):
"""Tracker file rescords the latest chckpoint during
training to restart from."""
return
os
.
path
.
join
(
checkpoints_path
,
'latest_checkpointed_iteration.txt'
)
def
read_metadata
(
tracker_filename
):
# Read the tracker file and either set the iteration or
# mark it as a release checkpoint.
iteration
=
0
release
=
False
with
open
(
tracker_filename
,
'r'
)
as
f
:
metastring
=
f
.
read
().
strip
()
try
:
iteration
=
int
(
metastring
)
except
ValueError
:
release
=
metastring
==
'release'
if
not
release
:
print_rank_0
(
'ERROR: Invalid metadata file {}. Exiting'
.
format
(
tracker_filename
))
sys
.
exit
()
assert
iteration
>
0
or
release
,
'error parsing metadata file {}'
.
format
(
tracker_filename
)
# Get the max iteration retrieved across the ranks.
iters_cuda
=
torch
.
cuda
.
LongTensor
([
iteration
])
torch
.
distributed
.
all_reduce
(
iters_cuda
,
op
=
torch
.
distributed
.
ReduceOp
.
MAX
)
max_iter
=
iters_cuda
[
0
].
item
()
# We should now have all the same iteration.
# If not, print a warning and chose the maximum
# iteration across all ranks.
if
iteration
!=
max_iter
:
print
(
'WARNING: on rank {} found iteration {} in the '
'metadata while max iteration across the ranks '
'is {}, replacing it with max iteration.'
.
format
(
rank
,
iteration
,
max_iter
),
flush
=
True
)
return
max_iter
,
release
def
get_rng_state
():
""" collect rng state across data parallel ranks """
args
=
get_args
()
rng_state
=
{
'random_rng_state'
:
random
.
getstate
(),
'np_rng_state'
:
np
.
random
.
get_state
(),
'torch_rng_state'
:
torch
.
get_rng_state
(),
'cuda_rng_state'
:
torch
.
cuda
.
get_rng_state
(),
'rng_tracker_states'
:
mpu
.
get_cuda_rng_tracker
().
get_states
()}
rng_state_list
=
None
if
torch
.
distributed
.
is_initialized
()
and
\
mpu
.
get_data_parallel_world_size
()
>
1
and
\
args
.
data_parallel_random_init
:
rng_state_list
=
\
[
None
for
i
in
range
(
mpu
.
get_data_parallel_world_size
())]
torch
.
distributed
.
all_gather_object
(
rng_state_list
,
rng_state
,
group
=
mpu
.
get_data_parallel_group
())
else
:
rng_state_list
=
[
rng_state
]
return
rng_state_list
def
save_checkpoint
(
iteration
,
model
,
optimizer
,
lr_scheduler
):
"""Save a model checkpoint."""
args
=
get_args
()
# Only rank zero of the data parallel writes to the disk.
model
=
utils
.
unwrap_model
(
model
)
print_rank_0
(
'saving checkpoint at iteration {:7d} to {}'
.
format
(
iteration
,
args
.
save
))
# collect rng state across data parallel ranks
rng_state
=
get_rng_state
()
if
not
torch
.
distributed
.
is_initialized
()
or
mpu
.
get_data_parallel_rank
()
==
0
:
# Arguments, iteration, and model.
state_dict
=
{}
state_dict
[
'args'
]
=
args
state_dict
[
'checkpoint_version'
]
=
3.0
state_dict
[
'iteration'
]
=
iteration
if
len
(
model
)
==
1
:
state_dict
[
'model'
]
=
model
[
0
].
state_dict_for_save_checkpoint
()
else
:
for
i
in
range
(
len
(
model
)):
mpu
.
set_virtual_pipeline_model_parallel_rank
(
i
)
state_dict
[
'model%d'
%
i
]
=
model
[
i
].
state_dict_for_save_checkpoint
()
# Optimizer stuff.
if
not
args
.
no_save_optim
:
if
optimizer
is
not
None
:
state_dict
[
'optimizer'
]
=
optimizer
.
state_dict
()
if
lr_scheduler
is
not
None
:
state_dict
[
'lr_scheduler'
]
=
lr_scheduler
.
state_dict
()
# RNG states.
if
not
args
.
no_save_rng
:
state_dict
[
"rng_state"
]
=
rng_state
# Save.
checkpoint_name
=
get_checkpoint_name
(
args
.
save
,
iteration
)
ensure_directory_exists
(
checkpoint_name
)
torch
.
save
(
state_dict
,
checkpoint_name
)
# Wait so everyone is done (necessary)
if
torch
.
distributed
.
is_initialized
():
torch
.
distributed
.
barrier
()
print_rank_0
(
' successfully saved checkpoint at iteration {:7d} to {}'
.
format
(
iteration
,
args
.
save
))
# And update the latest iteration
if
not
torch
.
distributed
.
is_initialized
()
or
torch
.
distributed
.
get_rank
()
==
0
:
tracker_filename
=
get_checkpoint_tracker_filename
(
args
.
save
)
with
open
(
tracker_filename
,
'w'
)
as
f
:
f
.
write
(
str
(
iteration
))
# Wait so everyone is done (not necessary)
if
torch
.
distributed
.
is_initialized
():
torch
.
distributed
.
barrier
()
def
_transpose_first_dim
(
t
,
num_splits
,
num_splits_first
,
model
):
input_shape
=
t
.
size
()
# We use a self_attention module but the values extracted aren't
# specific to self attention so should work for cross attention as well
while
hasattr
(
model
,
'module'
):
model
=
model
.
module
attention_module
=
model
.
language_model
.
encoder
.
layers
[
0
].
self_attention
hidden_size_per_attention_head
=
attention_module
.
hidden_size_per_attention_head
num_attention_heads_per_partition
=
attention_module
.
num_attention_heads_per_partition
if
num_splits_first
:
"""[num_splits * np * hn, h]
-->(view) [num_splits, np, hn, h]
-->(tranpose) [np, num_splits, hn, h]
-->(view) [np * num_splits * hn, h] """
intermediate_shape
=
\
(
num_splits
,
num_attention_heads_per_partition
,
hidden_size_per_attention_head
)
+
input_shape
[
1
:]
t
=
t
.
view
(
*
intermediate_shape
)
t
=
t
.
transpose
(
0
,
1
).
contiguous
()
else
:
"""[np * hn * num_splits, h]
-->(view) [np, hn, num_splits, h]
-->(tranpose) [np, num_splits, hn, h]
-->(view) [np * num_splits * hn, h] """
intermediate_shape
=
\
(
num_attention_heads_per_partition
,
hidden_size_per_attention_head
,
num_splits
)
+
\
input_shape
[
1
:]
t
=
t
.
view
(
*
intermediate_shape
)
t
=
t
.
transpose
(
1
,
2
).
contiguous
()
t
=
t
.
view
(
*
input_shape
)
return
t
def
fix_query_key_value_ordering
(
model
,
checkpoint_version
):
"""Fix up query/key/value matrix ordering if checkpoint
version is smaller than 2.0
"""
if
checkpoint_version
<
2.0
:
if
isinstance
(
model
,
list
):
assert
len
(
model
)
==
1
model
=
model
[
0
]
for
name
,
param
in
model
.
named_parameters
():
if
name
.
endswith
((
'.query_key_value.weight'
,
'.query_key_value.bias'
)):
if
checkpoint_version
==
0
:
fixed_param
=
_transpose_first_dim
(
param
.
data
,
3
,
True
,
model
)
elif
checkpoint_version
==
1.0
:
fixed_param
=
_transpose_first_dim
(
param
.
data
,
3
,
False
,
model
)
else
:
print_rank_0
(
f
"Invalid checkpoint version
{
checkpoint_version
}
."
)
sys
.
exit
()
param
.
data
.
copy_
(
fixed_param
)
if
name
.
endswith
((
'.key_value.weight'
,
'.key_value.bias'
)):
if
checkpoint_version
==
0
:
fixed_param
=
_transpose_first_dim
(
param
.
data
,
2
,
True
,
model
)
elif
checkpoint_version
==
1.0
:
fixed_param
=
_transpose_first_dim
(
param
.
data
,
2
,
False
,
model
)
else
:
print_rank_0
(
f
"Invalid checkpoint version
{
checkpoint_version
}
."
)
sys
.
exit
()
param
.
data
.
copy_
(
fixed_param
)
print_rank_0
(
" succesfully fixed query-key-values ordering for"
" checkpoint version {}"
.
format
(
checkpoint_version
))
def
load_checkpoint
(
model
,
optimizer
,
lr_scheduler
,
load_arg
=
'load'
,
strict
=
True
):
"""Load a model checkpoint and return the iteration.
strict (bool): whether to strictly enforce that the keys in
:attr:`state_dict` of the checkpoint match the names of
parameters and buffers in model.
"""
args
=
get_args
()
load_dir
=
getattr
(
args
,
load_arg
)
model
=
utils
.
unwrap_model
(
model
)
# Read the tracker file and set the iteration.
tracker_filename
=
get_checkpoint_tracker_filename
(
load_dir
)
# If no tracker file, return iretation zero.
if
not
os
.
path
.
isfile
(
tracker_filename
):
print_rank_0
(
'WARNING: could not find the metadata file {} '
.
format
(
tracker_filename
))
print_rank_0
(
' will not load any checkpoints and will start from '
'random'
)
return
0
# Otherwise, read the tracker file and either set the iteration or
# mark it as a release checkpoint.
iteration
,
release
=
read_metadata
(
tracker_filename
)
# Checkpoint.
checkpoint_name
=
get_checkpoint_name
(
load_dir
,
iteration
,
release
)
print_rank_0
(
f
' loading checkpoint from
{
args
.
load
}
at iteration
{
iteration
}
'
)
# Load the checkpoint.
try
:
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
except
ModuleNotFoundError
:
from
megatron.fp16_deprecated
import
loss_scaler
# For backward compatibility.
print_rank_0
(
' > deserializing using the old code structure ...'
)
sys
.
modules
[
'fp16.loss_scaler'
]
=
sys
.
modules
[
'megatron.fp16_deprecated.loss_scaler'
]
sys
.
modules
[
'megatron.fp16.loss_scaler'
]
=
sys
.
modules
[
'megatron.fp16_deprecated.loss_scaler'
]
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
sys
.
modules
.
pop
(
'fp16.loss_scaler'
,
None
)
sys
.
modules
.
pop
(
'megatron.fp16.loss_scaler'
,
None
)
except
BaseException
as
e
:
print_rank_0
(
'could not load the checkpoint'
)
print_rank_0
(
e
)
sys
.
exit
()
# set checkpoint version
set_checkpoint_version
(
state_dict
.
get
(
'checkpoint_version'
,
0
))
# Set iteration.
if
args
.
finetune
or
release
:
iteration
=
0
else
:
try
:
iteration
=
state_dict
[
'iteration'
]
except
KeyError
:
try
:
# Backward compatible with older checkpoints
iteration
=
state_dict
[
'total_iters'
]
except
KeyError
:
print_rank_0
(
'A metadata file exists but unable to load '
'iteration from checkpoint {}, exiting'
.
format
(
checkpoint_name
))
sys
.
exit
()
# Check arguments.
assert
args
.
consumed_train_samples
==
0
assert
args
.
consumed_valid_samples
==
0
if
'args'
in
state_dict
:
checkpoint_args
=
state_dict
[
'args'
]
check_checkpoint_args
(
checkpoint_args
)
args
.
consumed_train_samples
=
getattr
(
checkpoint_args
,
'consumed_train_samples'
,
0
)
update_num_microbatches
(
consumed_samples
=
args
.
consumed_train_samples
)
args
.
consumed_valid_samples
=
getattr
(
checkpoint_args
,
'consumed_valid_samples'
,
0
)
else
:
print_rank_0
(
'could not find arguments in the checkpoint ...'
)
# Model.
if
len
(
model
)
==
1
:
model
[
0
].
load_state_dict
(
state_dict
[
'model'
],
strict
=
strict
)
else
:
for
i
in
range
(
len
(
model
)):
mpu
.
set_virtual_pipeline_model_parallel_rank
(
i
)
model
[
i
].
load_state_dict
(
state_dict
[
'model%d'
%
i
],
strict
=
strict
)
# Fix up query/key/value matrix ordering if needed
checkpoint_version
=
get_checkpoint_version
()
print_rank_0
(
f
' checkpoint version
{
checkpoint_version
}
'
)
fix_query_key_value_ordering
(
model
,
checkpoint_version
)
# Optimizer.
if
not
release
and
not
args
.
finetune
and
not
args
.
no_load_optim
:
try
:
if
optimizer
is
not
None
:
optimizer
.
load_state_dict
(
state_dict
[
'optimizer'
])
if
lr_scheduler
is
not
None
:
lr_scheduler
.
load_state_dict
(
state_dict
[
'lr_scheduler'
])
except
KeyError
:
print_rank_0
(
'Unable to load optimizer from checkpoint {}. '
'Specify --no-load-optim or --finetune to prevent '
'attempting to load the optimizer state, '
'exiting ...'
.
format
(
checkpoint_name
))
sys
.
exit
()
# rng states.
if
not
release
and
not
args
.
finetune
and
not
args
.
no_load_rng
:
try
:
if
'rng_state'
in
state_dict
:
# access rng_state for data parallel rank
if
args
.
data_parallel_random_init
:
rng_state
=
state_dict
[
'rng_state'
][
mpu
.
get_data_parallel_rank
()]
else
:
rng_state
=
state_dict
[
'rng_state'
][
0
]
random
.
setstate
(
rng_state
[
'random_rng_state'
])
np
.
random
.
set_state
(
rng_state
[
'np_rng_state'
])
torch
.
set_rng_state
(
rng_state
[
'torch_rng_state'
])
torch
.
cuda
.
set_rng_state
(
rng_state
[
'cuda_rng_state'
])
# Check for empty states array
if
not
rng_state
[
'rng_tracker_states'
]:
raise
KeyError
mpu
.
get_cuda_rng_tracker
().
set_states
(
rng_state
[
'rng_tracker_states'
])
else
:
# backward compatability
random
.
setstate
(
state_dict
[
'random_rng_state'
])
np
.
random
.
set_state
(
state_dict
[
'np_rng_state'
])
torch
.
set_rng_state
(
state_dict
[
'torch_rng_state'
])
torch
.
cuda
.
set_rng_state
(
state_dict
[
'cuda_rng_state'
])
# Check for empty states array
if
not
state_dict
[
'rng_tracker_states'
]:
raise
KeyError
mpu
.
get_cuda_rng_tracker
().
set_states
(
state_dict
[
'rng_tracker_states'
])
except
KeyError
:
print_rank_0
(
'Unable to load rng state from checkpoint {}. '
'Specify --no-load-rng or --finetune to prevent '
'attempting to load the rng state, '
'exiting ...'
.
format
(
checkpoint_name
))
sys
.
exit
()
# Some utilities want to load a checkpoint without distributed being initialized
if
torch
.
distributed
.
is_initialized
():
torch
.
distributed
.
barrier
()
print_rank_0
(
f
' successfully loaded checkpoint from
{
args
.
load
}
'
f
'at iteration
{
iteration
}
'
)
return
iteration
def
load_biencoder_checkpoint
(
model
,
only_query_model
=
False
,
only_context_model
=
False
,
custom_load_path
=
None
):
"""
selectively load retrieval models for indexing/retrieving
from saved checkpoints
"""
args
=
get_args
()
model
=
utils
.
unwrap_model
(
model
)
load_path
=
custom_load_path
if
custom_load_path
is
not
None
else
args
.
load
tracker_filename
=
get_checkpoint_tracker_filename
(
load_path
)
with
open
(
tracker_filename
,
'r'
)
as
f
:
iteration
=
int
(
f
.
read
().
strip
())
checkpoint_name
=
get_checkpoint_name
(
load_path
,
iteration
,
False
)
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
'global rank {} is loading checkpoint {}'
.
format
(
torch
.
distributed
.
get_rank
(),
checkpoint_name
))
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
ret_state_dict
=
state_dict
[
'model'
]
if
only_query_model
:
ret_state_dict
.
pop
(
'context_model'
)
if
only_context_model
:
ret_state_dict
.
pop
(
'query_model'
)
assert
len
(
model
)
==
1
model
[
0
].
load_state_dict
(
ret_state_dict
)
torch
.
distributed
.
barrier
()
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
' successfully loaded {}'
.
format
(
checkpoint_name
))
return
model
3rdparty/Megatron-LM/megatron/data/Makefile
0 → 100644
View file @
0211193c
CXXFLAGS
+=
-O3
-Wall
-shared
-std
=
c++11
-fPIC
-fdiagnostics-color
CPPFLAGS
+=
$(
shell
python3
-m
pybind11
--includes
)
LIBNAME
=
helpers
LIBEXT
=
$(
shell
python3-config
--extension-suffix
)
default
:
$(LIBNAME)$(LIBEXT)
%$(LIBEXT)
:
%.cpp
$(CXX)
$(CXXFLAGS)
$(CPPFLAGS)
$<
-o
$@
3rdparty/Megatron-LM/megatron/data/__init__.py
0 → 100644
View file @
0211193c
from
.
import
indexed_dataset
3rdparty/Megatron-LM/megatron/data/autoaugment.py
0 → 100644
View file @
0211193c
"""AutoAugment data augmentation policy for ImageNet.
-- Begin license text.
MIT License
Copyright (c) 2018 Philip Popien
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
-- End license text.
Code adapted from https://github.com/DeepVoltaire/AutoAugment.
This module implements the fixed AutoAugment data augmentation policy for ImageNet provided in
Appendix A, Table 9 of reference [1]. It does not include any of the search code for augmentation
policies.
Reference:
[1] https://arxiv.org/abs/1805.09501
"""
import
random
import
numpy
as
np
from
PIL
import
Image
from
PIL
import
ImageEnhance
from
PIL
import
ImageOps
_MAX_LEVEL
=
10
# Maximum integer strength of an augmentation, if applicable.
class
ImageNetPolicy
:
"""Definition of an ImageNetPolicy.
Implements a fixed AutoAugment data augmentation policy targeted at
ImageNet training by randomly applying at runtime one of the 25 pre-defined
data augmentation sub-policies provided in Reference [1].
Usage example as a Pytorch Transform:
>>> transform=transforms.Compose([transforms.Resize(256),
>>> ImageNetPolicy(),
>>> transforms.ToTensor()])
"""
def
__init__
(
self
,
fillcolor
=
(
128
,
128
,
128
)):
"""Initialize an ImageNetPolicy.
Args:
fillcolor (tuple): RGB color components of the color to be used for
filling when needed (default: (128, 128, 128), which
corresponds to gray).
"""
# Instantiate a list of sub-policies.
# Each entry of the list is a SubPolicy which consists of
# two augmentation operations,
# each of those parametrized as operation, probability, magnitude.
# Those two operations are applied sequentially on the image upon call.
self
.
policies
=
[
SubPolicy
(
"posterize"
,
0.4
,
8
,
"rotate"
,
0.6
,
9
,
fillcolor
),
SubPolicy
(
"solarize"
,
0.6
,
5
,
"autocontrast"
,
0.6
,
5
,
fillcolor
),
SubPolicy
(
"equalize"
,
0.8
,
8
,
"equalize"
,
0.6
,
3
,
fillcolor
),
SubPolicy
(
"posterize"
,
0.6
,
7
,
"posterize"
,
0.6
,
6
,
fillcolor
),
SubPolicy
(
"equalize"
,
0.4
,
7
,
"solarize"
,
0.2
,
4
,
fillcolor
),
SubPolicy
(
"equalize"
,
0.4
,
4
,
"rotate"
,
0.8
,
8
,
fillcolor
),
SubPolicy
(
"solarize"
,
0.6
,
3
,
"equalize"
,
0.6
,
7
,
fillcolor
),
SubPolicy
(
"posterize"
,
0.8
,
5
,
"equalize"
,
1.0
,
2
,
fillcolor
),
SubPolicy
(
"rotate"
,
0.2
,
3
,
"solarize"
,
0.6
,
8
,
fillcolor
),
SubPolicy
(
"equalize"
,
0.6
,
8
,
"posterize"
,
0.4
,
6
,
fillcolor
),
SubPolicy
(
"rotate"
,
0.8
,
8
,
"color"
,
0.4
,
0
,
fillcolor
),
SubPolicy
(
"rotate"
,
0.4
,
9
,
"equalize"
,
0.6
,
2
,
fillcolor
),
SubPolicy
(
"equalize"
,
0.0
,
7
,
"equalize"
,
0.8
,
8
,
fillcolor
),
SubPolicy
(
"invert"
,
0.6
,
4
,
"equalize"
,
1.0
,
8
,
fillcolor
),
SubPolicy
(
"color"
,
0.6
,
4
,
"contrast"
,
1.0
,
8
,
fillcolor
),
SubPolicy
(
"rotate"
,
0.8
,
8
,
"color"
,
1.0
,
2
,
fillcolor
),
SubPolicy
(
"color"
,
0.8
,
8
,
"solarize"
,
0.8
,
7
,
fillcolor
),
SubPolicy
(
"sharpness"
,
0.4
,
7
,
"invert"
,
0.6
,
8
,
fillcolor
),
SubPolicy
(
"shearX"
,
0.6
,
5
,
"equalize"
,
1.0
,
9
,
fillcolor
),
SubPolicy
(
"color"
,
0.4
,
0
,
"equalize"
,
0.6
,
3
,
fillcolor
),
SubPolicy
(
"equalize"
,
0.4
,
7
,
"solarize"
,
0.2
,
4
,
fillcolor
),
SubPolicy
(
"solarize"
,
0.6
,
5
,
"autocontrast"
,
0.6
,
5
,
fillcolor
),
SubPolicy
(
"invert"
,
0.6
,
4
,
"equalize"
,
1.0
,
8
,
fillcolor
),
SubPolicy
(
"color"
,
0.6
,
4
,
"contrast"
,
1.0
,
8
,
fillcolor
),
SubPolicy
(
"equalize"
,
0.8
,
8
,
"equalize"
,
0.6
,
3
,
fillcolor
),
]
def
__call__
(
self
,
img
):
"""Define call method for ImageNetPolicy class."""
policy_idx
=
random
.
randint
(
0
,
len
(
self
.
policies
)
-
1
)
return
self
.
policies
[
policy_idx
](
img
)
def
__repr__
(
self
):
"""Define repr method for ImageNetPolicy class."""
return
"ImageNetPolicy"
class
SubPolicy
:
"""Definition of a SubPolicy.
A SubPolicy consists of two augmentation operations,
each of those parametrized as operation, probability, magnitude.
The two operations are applied sequentially on the image upon call.
"""
def
__init__
(
self
,
operation1
,
probability1
,
magnitude_idx1
,
operation2
,
probability2
,
magnitude_idx2
,
fillcolor
,
):
"""Initialize a SubPolicy.
Args:
operation1 (str): Key specifying the first augmentation operation.
There are fourteen key values altogether (see supported_ops below
listing supported operations). probability1 (float): Probability
within [0., 1.] of applying the first augmentation operation.
magnitude_idx1 (int): Integer specifiying the strength of the first
operation as an index further used to derive the magnitude from a
range of possible values.
operation2 (str): Key specifying the second augmentation operation.
probability2 (float): Probability within [0., 1.] of applying the
second augmentation operation.
magnitude_idx2 (int): Integer specifiying the strength of the
second operation as an index further used to derive the magnitude
from a range of possible values.
fillcolor (tuple): RGB color components of the color to be used for
filling.
Returns:
"""
# List of supported operations for operation1 and operation2.
supported_ops
=
[
"shearX"
,
"shearY"
,
"translateX"
,
"translateY"
,
"rotate"
,
"color"
,
"posterize"
,
"solarize"
,
"contrast"
,
"sharpness"
,
"brightness"
,
"autocontrast"
,
"equalize"
,
"invert"
,
]
assert
(
operation1
in
supported_ops
)
and
(
operation2
in
supported_ops
),
"SubPolicy:one of oper1 or oper2 refers to an unsupported operation."
assert
(
0.0
<=
probability1
<=
1.0
and
0.0
<=
probability2
<=
1.0
),
"SubPolicy: prob1 and prob2 should be within [0., 1.]."
assert
(
isinstance
(
magnitude_idx1
,
int
)
and
0
<=
magnitude_idx1
<=
10
),
"SubPolicy: idx1 should be specified as an integer within [0, 10]."
assert
(
isinstance
(
magnitude_idx2
,
int
)
and
0
<=
magnitude_idx2
<=
10
),
"SubPolicy: idx2 should be specified as an integer within [0, 10]."
# Define a dictionary where each key refers to a specific type of
# augmentation and the corresponding value is a range of ten possible
# magnitude values for that augmentation.
num_levels
=
_MAX_LEVEL
+
1
ranges
=
{
"shearX"
:
np
.
linspace
(
0
,
0.3
,
num_levels
),
"shearY"
:
np
.
linspace
(
0
,
0.3
,
num_levels
),
"translateX"
:
np
.
linspace
(
0
,
150
/
331
,
num_levels
),
"translateY"
:
np
.
linspace
(
0
,
150
/
331
,
num_levels
),
"rotate"
:
np
.
linspace
(
0
,
30
,
num_levels
),
"color"
:
np
.
linspace
(
0.0
,
0.9
,
num_levels
),
"posterize"
:
np
.
round
(
np
.
linspace
(
8
,
4
,
num_levels
),
0
).
astype
(
np
.
int
),
"solarize"
:
np
.
linspace
(
256
,
0
,
num_levels
),
# range [0, 256]
"contrast"
:
np
.
linspace
(
0.0
,
0.9
,
num_levels
),
"sharpness"
:
np
.
linspace
(
0.0
,
0.9
,
num_levels
),
"brightness"
:
np
.
linspace
(
0.0
,
0.9
,
num_levels
),
"autocontrast"
:
[
0
]
*
num_levels
,
# This augmentation doesn't use magnitude parameter.
"equalize"
:
[
0
]
*
num_levels
,
# This augmentation doesn't use magnitude parameter.
"invert"
:
[
0
]
*
num_levels
,
# This augmentation doesn't use magnitude parameter.
}
def
rotate_with_fill
(
img
,
magnitude
):
"""Define rotation transformation with fill.
The input image is first rotated, then it is blended together with
a gray mask of the same size. Note that fillcolor as defined
elsewhere in this module doesn't apply here.
Args:
magnitude (float): rotation angle in degrees.
Returns:
rotated_filled (PIL Image): rotated image with gray filling for
disoccluded areas unveiled by the rotation.
"""
rotated
=
img
.
convert
(
"RGBA"
).
rotate
(
magnitude
)
rotated_filled
=
Image
.
composite
(
rotated
,
Image
.
new
(
"RGBA"
,
rotated
.
size
,
(
128
,)
*
4
),
rotated
)
return
rotated_filled
.
convert
(
img
.
mode
)
# Define a dictionary of augmentation functions where each key refers
# to a specific type of augmentation and the corresponding value defines
# the augmentation itself using a lambda function.
# pylint: disable=unnecessary-lambda
func_dict
=
{
"shearX"
:
lambda
img
,
magnitude
:
img
.
transform
(
img
.
size
,
Image
.
AFFINE
,
(
1
,
magnitude
*
random
.
choice
([
-
1
,
1
]),
0
,
0
,
1
,
0
),
Image
.
BICUBIC
,
fillcolor
=
fillcolor
,
),
"shearY"
:
lambda
img
,
magnitude
:
img
.
transform
(
img
.
size
,
Image
.
AFFINE
,
(
1
,
0
,
0
,
magnitude
*
random
.
choice
([
-
1
,
1
]),
1
,
0
),
Image
.
BICUBIC
,
fillcolor
=
fillcolor
,
),
"translateX"
:
lambda
img
,
magnitude
:
img
.
transform
(
img
.
size
,
Image
.
AFFINE
,
(
1
,
0
,
magnitude
*
img
.
size
[
0
]
*
random
.
choice
([
-
1
,
1
]),
0
,
1
,
0
,
),
fillcolor
=
fillcolor
,
),
"translateY"
:
lambda
img
,
magnitude
:
img
.
transform
(
img
.
size
,
Image
.
AFFINE
,
(
1
,
0
,
0
,
0
,
1
,
magnitude
*
img
.
size
[
1
]
*
random
.
choice
([
-
1
,
1
]),
),
fillcolor
=
fillcolor
,
),
"rotate"
:
lambda
img
,
magnitude
:
rotate_with_fill
(
img
,
magnitude
),
"color"
:
lambda
img
,
magnitude
:
ImageEnhance
.
Color
(
img
).
enhance
(
1
+
magnitude
*
random
.
choice
([
-
1
,
1
])
),
"posterize"
:
lambda
img
,
magnitude
:
ImageOps
.
posterize
(
img
,
magnitude
),
"solarize"
:
lambda
img
,
magnitude
:
ImageOps
.
solarize
(
img
,
magnitude
),
"contrast"
:
lambda
img
,
magnitude
:
ImageEnhance
.
Contrast
(
img
).
enhance
(
1
+
magnitude
*
random
.
choice
([
-
1
,
1
])),
"sharpness"
:
lambda
img
,
magnitude
:
ImageEnhance
.
Sharpness
(
img
).
enhance
(
1
+
magnitude
*
random
.
choice
([
-
1
,
1
])),
"brightness"
:
lambda
img
,
magnitude
:
ImageEnhance
.
Brightness
(
img
).
enhance
(
1
+
magnitude
*
random
.
choice
([
-
1
,
1
])),
"autocontrast"
:
lambda
img
,
magnitude
:
ImageOps
.
autocontrast
(
img
),
"equalize"
:
lambda
img
,
magnitude
:
ImageOps
.
equalize
(
img
),
"invert"
:
lambda
img
,
magnitude
:
ImageOps
.
invert
(
img
),
}
# Store probability, function and magnitude of the first augmentation
# for the sub-policy.
self
.
probability1
=
probability1
self
.
operation1
=
func_dict
[
operation1
]
self
.
magnitude1
=
ranges
[
operation1
][
magnitude_idx1
]
# Store probability, function and magnitude of the second augmentation
# for the sub-policy.
self
.
probability2
=
probability2
self
.
operation2
=
func_dict
[
operation2
]
self
.
magnitude2
=
ranges
[
operation2
][
magnitude_idx2
]
def
__call__
(
self
,
img
):
"""Define call method for SubPolicy class."""
# Randomly apply operation 1.
if
random
.
random
()
<
self
.
probability1
:
img
=
self
.
operation1
(
img
,
self
.
magnitude1
)
# Randomly apply operation 2.
if
random
.
random
()
<
self
.
probability2
:
img
=
self
.
operation2
(
img
,
self
.
magnitude2
)
return
img
3rdparty/Megatron-LM/megatron/data/bert_dataset.py
0 → 100644
View file @
0211193c
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""BERT Style dataset."""
import
numpy
as
np
import
torch
from
megatron
import
(
get_args
,
get_tokenizer
,
mpu
,
print_rank_0
)
from
megatron.data.dataset_utils
import
(
get_samples_mapping
,
get_a_and_b_segments
,
truncate_segments
,
create_tokens_and_tokentypes
,
create_masked_lm_predictions
)
class
BertDataset
(
torch
.
utils
.
data
.
Dataset
):
def
__init__
(
self
,
name
,
indexed_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
masked_lm_prob
,
max_seq_length
,
short_seq_prob
,
seed
,
binary_head
):
# Params to store.
self
.
name
=
name
self
.
seed
=
seed
self
.
masked_lm_prob
=
masked_lm_prob
self
.
max_seq_length
=
max_seq_length
self
.
binary_head
=
binary_head
# Dataset.
self
.
indexed_dataset
=
indexed_dataset
# Build the samples mapping.
self
.
samples_mapping
=
get_samples_mapping
(
self
.
indexed_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
self
.
max_seq_length
-
3
,
# account for added tokens
short_seq_prob
,
self
.
seed
,
self
.
name
,
self
.
binary_head
)
# Vocab stuff.
tokenizer
=
get_tokenizer
()
self
.
vocab_id_list
=
list
(
tokenizer
.
inv_vocab
.
keys
())
self
.
vocab_id_to_token_dict
=
tokenizer
.
inv_vocab
self
.
cls_id
=
tokenizer
.
cls
self
.
sep_id
=
tokenizer
.
sep
self
.
mask_id
=
tokenizer
.
mask
self
.
pad_id
=
tokenizer
.
pad
def
__len__
(
self
):
return
self
.
samples_mapping
.
shape
[
0
]
def
__getitem__
(
self
,
idx
):
start_idx
,
end_idx
,
seq_length
=
self
.
samples_mapping
[
idx
]
sample
=
[
self
.
indexed_dataset
[
i
]
for
i
in
range
(
start_idx
,
end_idx
)]
# Note that this rng state should be numpy and not python since
# python randint is inclusive whereas the numpy one is exclusive.
# We % 2**32 since numpy requres the seed to be between 0 and 2**32 - 1
np_rng
=
np
.
random
.
RandomState
(
seed
=
((
self
.
seed
+
idx
)
%
2
**
32
))
return
build_training_sample
(
sample
,
seq_length
,
self
.
max_seq_length
,
# needed for padding
self
.
vocab_id_list
,
self
.
vocab_id_to_token_dict
,
self
.
cls_id
,
self
.
sep_id
,
self
.
mask_id
,
self
.
pad_id
,
self
.
masked_lm_prob
,
np_rng
,
self
.
binary_head
)
def
build_training_sample
(
sample
,
target_seq_length
,
max_seq_length
,
vocab_id_list
,
vocab_id_to_token_dict
,
cls_id
,
sep_id
,
mask_id
,
pad_id
,
masked_lm_prob
,
np_rng
,
binary_head
):
"""Biuld training sample.
Arguments:
sample: A list of sentences in which each sentence is a list token ids.
target_seq_length: Desired sequence length.
max_seq_length: Maximum length of the sequence. All values are padded to
this length.
vocab_id_list: List of vocabulary ids. Used to pick a random id.
vocab_id_to_token_dict: A dictionary from vocab ids to text tokens.
cls_id: Start of example id.
sep_id: Separator id.
mask_id: Mask token id.
pad_id: Padding token id.
masked_lm_prob: Probability to mask tokens.
np_rng: Random number genenrator. Note that this rng state should be
numpy and not python since python randint is inclusive for
the opper bound whereas the numpy one is exclusive.
"""
if
binary_head
:
# We assume that we have at least two sentences in the sample
assert
len
(
sample
)
>
1
assert
target_seq_length
<=
max_seq_length
# Divide sample into two segments (A and B).
if
binary_head
:
tokens_a
,
tokens_b
,
is_next_random
=
get_a_and_b_segments
(
sample
,
np_rng
)
else
:
tokens_a
=
[]
for
j
in
range
(
len
(
sample
)):
tokens_a
.
extend
(
sample
[
j
])
tokens_b
=
[]
is_next_random
=
False
# Truncate to `target_sequence_length`.
max_num_tokens
=
target_seq_length
truncated
=
truncate_segments
(
tokens_a
,
tokens_b
,
len
(
tokens_a
),
len
(
tokens_b
),
max_num_tokens
,
np_rng
)
# Build tokens and toketypes.
tokens
,
tokentypes
=
create_tokens_and_tokentypes
(
tokens_a
,
tokens_b
,
cls_id
,
sep_id
)
# Masking.
max_predictions_per_seq
=
masked_lm_prob
*
max_num_tokens
(
tokens
,
masked_positions
,
masked_labels
,
_
,
_
)
=
create_masked_lm_predictions
(
tokens
,
vocab_id_list
,
vocab_id_to_token_dict
,
masked_lm_prob
,
cls_id
,
sep_id
,
mask_id
,
max_predictions_per_seq
,
np_rng
)
# Padding.
tokens_np
,
tokentypes_np
,
labels_np
,
padding_mask_np
,
loss_mask_np
\
=
pad_and_convert_to_numpy
(
tokens
,
tokentypes
,
masked_positions
,
masked_labels
,
pad_id
,
max_seq_length
)
train_sample
=
{
'text'
:
tokens_np
,
'types'
:
tokentypes_np
,
'labels'
:
labels_np
,
'is_random'
:
int
(
is_next_random
),
'loss_mask'
:
loss_mask_np
,
'padding_mask'
:
padding_mask_np
,
'truncated'
:
int
(
truncated
)}
return
train_sample
def
pad_and_convert_to_numpy
(
tokens
,
tokentypes
,
masked_positions
,
masked_labels
,
pad_id
,
max_seq_length
):
"""Pad sequences and convert them to numpy."""
# Some checks.
num_tokens
=
len
(
tokens
)
padding_length
=
max_seq_length
-
num_tokens
assert
padding_length
>=
0
assert
len
(
tokentypes
)
==
num_tokens
assert
len
(
masked_positions
)
==
len
(
masked_labels
)
# Tokens and token types.
filler
=
[
pad_id
]
*
padding_length
tokens_np
=
np
.
array
(
tokens
+
filler
,
dtype
=
np
.
int64
)
tokentypes_np
=
np
.
array
(
tokentypes
+
filler
,
dtype
=
np
.
int64
)
# Padding mask.
padding_mask_np
=
np
.
array
([
1
]
*
num_tokens
+
[
0
]
*
padding_length
,
dtype
=
np
.
int64
)
# Lables and loss mask.
labels
=
[
-
1
]
*
max_seq_length
loss_mask
=
[
0
]
*
max_seq_length
for
i
in
range
(
len
(
masked_positions
)):
assert
masked_positions
[
i
]
<
num_tokens
labels
[
masked_positions
[
i
]]
=
masked_labels
[
i
]
loss_mask
[
masked_positions
[
i
]]
=
1
labels_np
=
np
.
array
(
labels
,
dtype
=
np
.
int64
)
loss_mask_np
=
np
.
array
(
loss_mask
,
dtype
=
np
.
int64
)
return
tokens_np
,
tokentypes_np
,
labels_np
,
padding_mask_np
,
loss_mask_np
3rdparty/Megatron-LM/megatron/data/biencoder_dataset_utils.py
0 → 100644
View file @
0211193c
import
os
import
time
import
numpy
as
np
import
torch
from
megatron
import
get_args
,
get_tokenizer
,
mpu
,
print_rank_0
from
megatron.data.dataset_utils
import
create_masked_lm_predictions
,
\
pad_and_convert_to_numpy
from
megatron.data.data_samplers
import
MegatronPretrainingSampler
def
make_attention_mask
(
source_block
,
target_block
):
"""
Returns a 2-dimensional (2-D) attention mask
:param source_block: 1-D array
:param target_block: 1-D array
"""
mask
=
(
target_block
[
None
,
:]
>=
1
)
*
(
source_block
[:,
None
]
>=
1
)
mask
=
mask
.
astype
(
np
.
int64
)
# (source_length, target_length)
return
mask
def
get_one_epoch_dataloader
(
dataset
,
micro_batch_size
=
None
):
"""Specifically one epoch to be used in an indexing job."""
args
=
get_args
()
if
micro_batch_size
is
None
:
micro_batch_size
=
args
.
micro_batch_size
num_workers
=
args
.
num_workers
# Use megatron's sampler with consumed samples set to 0 as
# this is only for evaluation and don't intend to resume half way.
# Also, set the drop last to false as don't intend to remove
# the last batch
batch_sampler
=
MegatronPretrainingSampler
(
total_samples
=
len
(
dataset
),
consumed_samples
=
0
,
micro_batch_size
=
args
.
micro_batch_size
,
data_parallel_rank
=
mpu
.
get_data_parallel_rank
(),
data_parallel_size
=
mpu
.
get_data_parallel_world_size
(),
drop_last
=
False
)
return
torch
.
utils
.
data
.
DataLoader
(
dataset
,
batch_sampler
=
batch_sampler
,
num_workers
=
num_workers
,
pin_memory
=
True
)
def
get_ict_batch
(
data_iterator
):
# Items and their type.
keys
=
[
'query_tokens'
,
'query_mask'
,
'context_tokens'
,
'context_mask'
,
'block_data'
]
datatype
=
torch
.
int64
# Broadcast data.
if
data_iterator
is
None
:
data
=
None
else
:
data
=
next
(
data_iterator
)
data_b
=
mpu
.
broadcast_data
(
keys
,
data
,
datatype
)
# Unpack.
query_tokens
=
data_b
[
'query_tokens'
].
long
()
query_mask
=
data_b
[
'query_mask'
]
<
0.5
context_tokens
=
data_b
[
'context_tokens'
].
long
()
context_mask
=
data_b
[
'context_mask'
]
<
0.5
block_indices
=
data_b
[
'block_data'
].
long
()
return
query_tokens
,
query_mask
,
\
context_tokens
,
context_mask
,
block_indices
def
join_str_list
(
str_list
):
"""Join a list of strings, handling spaces appropriately"""
result
=
""
for
s
in
str_list
:
if
s
.
startswith
(
"##"
):
result
+=
s
[
2
:]
else
:
result
+=
" "
+
s
return
result
class
BlockSampleData
(
object
):
"""A struct for fully describing a fixed-size block of data as used in REALM
:param start_idx: for first sentence of the block
:param end_idx: for last sentence of the block (may be partially truncated in sample construction)
:param doc_idx: the index of the document from which the block comes in the original indexed dataset
:param block_idx: a unique integer identifier given to every block.
"""
def
__init__
(
self
,
start_idx
,
end_idx
,
doc_idx
,
block_idx
):
self
.
start_idx
=
start_idx
self
.
end_idx
=
end_idx
self
.
doc_idx
=
doc_idx
self
.
block_idx
=
block_idx
def
as_array
(
self
):
return
np
.
array
([
self
.
start_idx
,
self
.
end_idx
,
self
.
doc_idx
,
self
.
block_idx
]).
astype
(
np
.
int64
)
def
as_tuple
(
self
):
return
self
.
start_idx
,
self
.
end_idx
,
self
.
doc_idx
,
self
.
block_idx
class
BlockSamplesMapping
(
object
):
def
__init__
(
self
,
mapping_array
):
# make sure that the array is compatible with BlockSampleData
assert
mapping_array
.
shape
[
1
]
==
4
self
.
mapping_array
=
mapping_array
def
__len__
(
self
):
return
self
.
mapping_array
.
shape
[
0
]
def
__getitem__
(
self
,
idx
):
"""Get the data associated with an indexed sample."""
sample_data
=
BlockSampleData
(
*
self
.
mapping_array
[
idx
])
return
sample_data
def
get_block_samples_mapping
(
block_dataset
,
title_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
max_seq_length
,
seed
,
name
,
use_one_sent_docs
=
False
):
"""Get samples mapping for a dataset over fixed size blocks. This function also requires
a dataset of the titles for the source documents since their lengths must be taken into account.
:return: samples_mapping (BlockSamplesMapping)
"""
if
not
num_epochs
:
if
not
max_num_samples
:
raise
ValueError
(
"Need to specify either max_num_samples "
"or num_epochs"
)
num_epochs
=
np
.
iinfo
(
np
.
int32
).
max
-
1
if
not
max_num_samples
:
max_num_samples
=
np
.
iinfo
(
np
.
int64
).
max
-
1
# Filename of the index mapping
indexmap_filename
=
data_prefix
indexmap_filename
+=
'_{}_indexmap'
.
format
(
name
)
if
num_epochs
!=
(
np
.
iinfo
(
np
.
int32
).
max
-
1
):
indexmap_filename
+=
'_{}ep'
.
format
(
num_epochs
)
if
max_num_samples
!=
(
np
.
iinfo
(
np
.
int64
).
max
-
1
):
indexmap_filename
+=
'_{}mns'
.
format
(
max_num_samples
)
indexmap_filename
+=
'_{}msl'
.
format
(
max_seq_length
)
indexmap_filename
+=
'_{}s'
.
format
(
seed
)
if
use_one_sent_docs
:
indexmap_filename
+=
'_1sentok'
indexmap_filename
+=
'.npy'
# Build the indexed mapping if not exist.
if
mpu
.
get_data_parallel_rank
()
==
0
and
\
not
os
.
path
.
isfile
(
indexmap_filename
):
print
(
' > WARNING: could not find index map file {}, building '
'the indices on rank 0 ...'
.
format
(
indexmap_filename
))
# Make sure the types match the helpers input types.
assert
block_dataset
.
doc_idx
.
dtype
==
np
.
int64
assert
block_dataset
.
sizes
.
dtype
==
np
.
int32
# Build samples mapping
verbose
=
torch
.
distributed
.
get_rank
()
==
0
start_time
=
time
.
time
()
print_rank_0
(
' > building samples index mapping for {} ...'
.
format
(
name
))
from
megatron.data
import
helpers
mapping_array
=
helpers
.
build_blocks_mapping
(
block_dataset
.
doc_idx
,
block_dataset
.
sizes
,
title_dataset
.
sizes
,
num_epochs
,
max_num_samples
,
max_seq_length
-
3
,
# account for added tokens
seed
,
verbose
,
use_one_sent_docs
)
print_rank_0
(
' > done building samples index mapping'
)
np
.
save
(
indexmap_filename
,
mapping_array
,
allow_pickle
=
True
)
print_rank_0
(
' > saved the index mapping in {}'
.
format
(
indexmap_filename
))
# Make sure all the ranks have built the mapping
print_rank_0
(
' > elapsed time to build and save samples mapping '
'(seconds): {:4f}'
.
format
(
time
.
time
()
-
start_time
))
# This should be a barrier but nccl barrier assumes
# device_index=rank which is not the case for model
# parallel case
counts
=
torch
.
cuda
.
LongTensor
([
1
])
torch
.
distributed
.
all_reduce
(
counts
,
group
=
mpu
.
get_data_parallel_group
())
assert
counts
[
0
].
item
()
==
torch
.
distributed
.
get_world_size
(
group
=
mpu
.
get_data_parallel_group
())
# Load indexed dataset.
print_rank_0
(
' > loading indexed mapping from {}'
.
format
(
indexmap_filename
))
start_time
=
time
.
time
()
mapping_array
=
np
.
load
(
indexmap_filename
,
allow_pickle
=
True
,
mmap_mode
=
'r'
)
samples_mapping
=
BlockSamplesMapping
(
mapping_array
)
print_rank_0
(
' loaded indexed file in {:3.3f} seconds'
.
format
(
time
.
time
()
-
start_time
))
print_rank_0
(
' total number of samples: {}'
.
format
(
mapping_array
.
shape
[
0
]))
return
samples_mapping
Prev
1
2
3
4
5
6
7
…
13
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}